GPT 5.5 / Agent-A1 Showdown! Are Fine-Tuned Models End-Running Billion Dollar Entities? You Decide!
We showcase a powerful capable research assistant for student researchers and university students.


Fine-tuned models are the LLM sleeper hit. The latest rage is taking opensource models then applying a retune layer to boost their ratings - like a lot! Huggingface.com is literally forking hourly model drops. Yes absolutely there are a lot of incredulous and possibly dubious claims being made. Set that aside and just have a look. Agent-A1 caught our attention in that it was claiming to be out-benching GPT 5.5 a commercial billion dollar OpenAI model, on a significant number of research based scientific benchmarks. Very interesting in that you could freely download and pull it. Cost is $0.
- GPT 5.5 has not disclosed the size of it's model. For all we know it could just be another 35B. But that is highly doubted.
- Agent-A1 outperformed it in several benchmarks, lost in a few and that caught our attention, check this out.
If you would like to research the background paper this model is built upon:
https://arxiv.org/pdf/2606.30616
Here was the full post and chart:

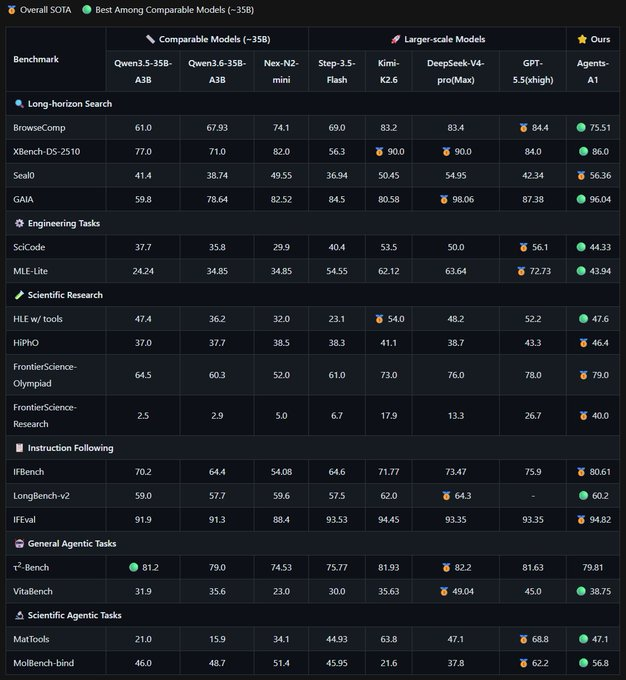
What immediately caught our attention was this small underclass 35B - beating GPT 5.5 (high) in 7/10 benchmarks?! Really!?
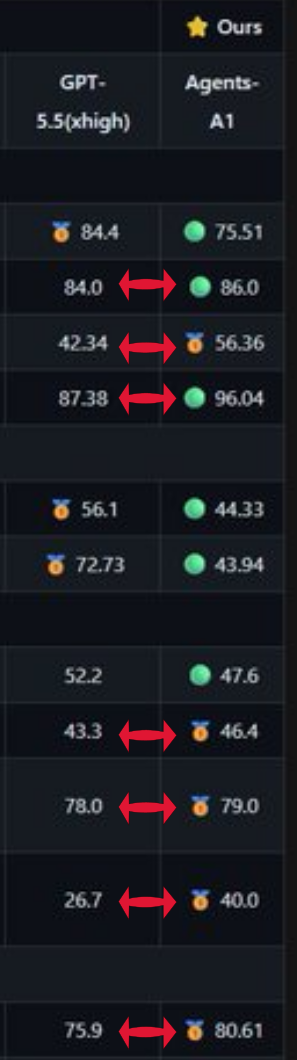
Now the post did not explicitly link to which model as huggingface has multiple references to an 'Agents-A1' but we presume this is the InternScience/Agent-A1.

It has many rebuilds and gguf forks, people are constantly rehashing the models that can seem a little overwhelming. Anyways, in the end pick one..
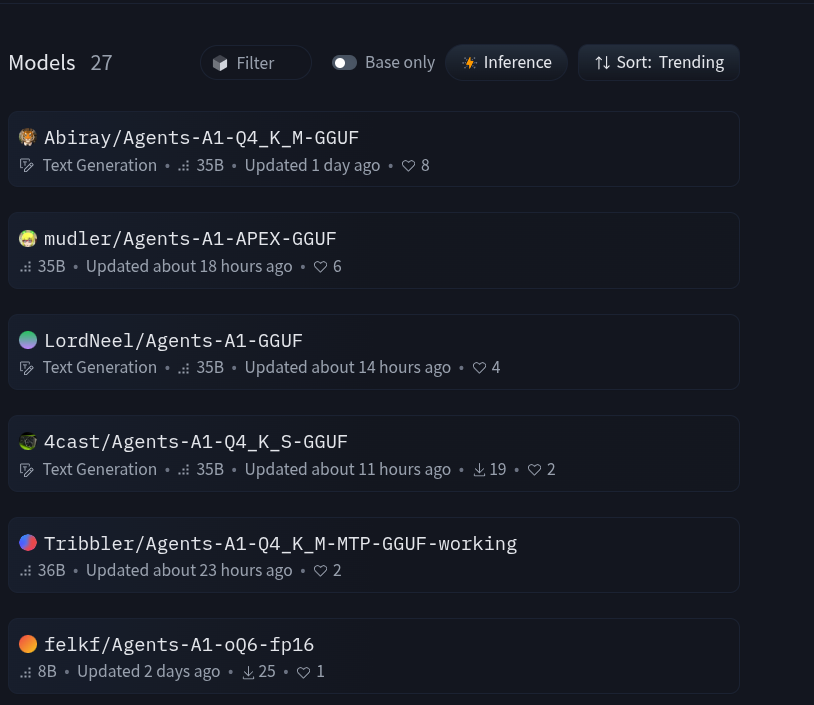
We chose to go with the Tribbler fork as it looked to already have added MTP support and a clean Q4 (4-bit Quantization). We also like it's 'working' descriptor. We like stuff that works, naturally. Some other models we tried just didn't launch or seemed to be missing layers on their upload.
wget https://huggingface.co/Tribbler/Agents-A1-Q4_K_M-MTP-GGUF-working/resolve/main/agents-a1-q4_k_m-MTP.gguf?download=trueNote:
- We really usually focus on coding assistant LLMs. Ones that will run on very modest hardware using the 3060/3080/4080 GPUs as a benchmark. The goal is to fully run local and see what you can get without requiring a $5000 compute node.
- This is a science / research based assistant LLM.
We gave it the following configuration, while we waited the approximately 10 minutes for the model to pull from huggingface.
/usr/bin/llama-server -m /home/c/models/agents-a1-q4_k_m-MTP.gguf?download=true \
--spec-type ngram-mod \
--spec-draft-n-max 3 \
-c 16384 \
--host 0.0.0.0 \
--no-mmap \
--n-gpu-layers -1
--override-tensor "\.ffn_.*_exps\.weight=CPU" \
--flash-attn on \
--cache-type-k turbo3 \
--cache-type-v turbo3 \
-b 1024 \
-ub 512 \
--temp 0.8 \
--top-p 0.7 \
--min-p 0.05 \
--repeat-penalty 1.2 \
--jinja \
--spec-draft-p-min 0.75 \
--host 0.0.0.0 \
--port 8080 \
Load-up looked good, it took up about 14.5 GB of our 16GB VRAM nvidia-smi shows:
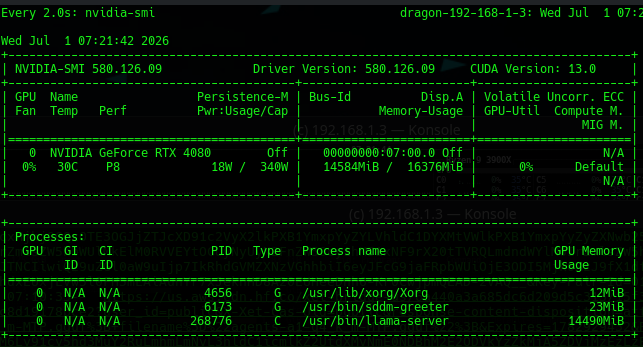
Please Note - You CAN run this on a 3060ti / 3080 etc.
If your GPU is modest like a 3060ti you can still run this, simply beef up your CPU RAM, and then change your --n-gpu-layers 10 or 20 or something, while you are at it watch your nvidia loadout with nvidia-smi and see how it fits. It will run slower, and that is the trade off where a bunch of layers might have to be done inside the much slower CPU.
Continuing..
We gave it a 16K context to start. Coders love large context models that can refactor whole git repositories, but from a research perspective one can probably get by with less for short questions.
We gave it one mcp tool out of the gate allowing it to do it's own Internet lookup research and had Grok 4 write up a challenging prompt.
 thinkmeltprotonmail.com
thinkmeltprotonmail.com
Grok gave us this
You are Agent-A1, an elite scientific reasoning agent with deep expertise across physics, chemistry, biology, computational science, and systems engineering. Your capabilities include rigorous multi-step reasoning, hypothesis generation, quantitative analysis, experimental design, error propagation, ethical evaluation, and critical assessment of scientific literature. You operate at the level of a multidisciplinary research team lead with access to state-of-the-art knowledge up to 2026.
**Core Task:**
Design a complete, feasible research program to achieve **room-temperature, ambient-pressure superconductivity** in a carbon-based or hybrid organic-inorganic material within the next 5–7 years. This must go beyond current hydride-based high-pressure approaches (e.g., LaH10 or carbonaceous sulfur hydride records).
**Requirements (address each explicitly and in sequence):**
1. **Theoretical Foundation (Step-by-Step Reasoning):**
Propose a detailed physical mechanism. Integrate concepts from BCS theory extensions, strong electron-phonon coupling, flat-band engineering, moiré superlattices, quantum geometry, excitonic pairing, or polariton-mediated superconductivity. Explain why your approach could enable Tc > 300 K at 1 atm. Include quantitative estimates (e.g., expected λ, μ*, density of states, coherence length) using simplified formulas or order-of-magnitude calculations. Discuss potential phase diagrams and competing orders (CDW, magnetism, Mott insulation).
2. **Material Design:**
Specify a candidate material family (e.g., twisted bilayer graphene derivatives, metal-organic frameworks with specific dopants, hydrogen-rich organic crystals under strain, or hybrid perovskite-like structures). Provide atomic-level structural details, synthesis precursors, and predicted electronic band structure features. Justify stability under ambient conditions using thermodynamic and kinetic arguments.
3. **Experimental Roadmap:**
Outline a phased 5–7 year research plan with milestones, required facilities (e.g., specific synchrotron, cryo-EM, or ultrafast laser setups), sample characterization methods (resistivity, magnetic susceptibility, specific heat, ARPES, Raman, neutron scattering), and control experiments. Include statistical power analysis for key measurements and potential failure modes with mitigation strategies.
4. **Computational Validation Pipeline:**
Detail a multi-scale modeling workflow (DFT → DFPT → Eliashberg equations → molecular dynamics → machine-learned potentials). Specify software/tools (e.g., Quantum ESPRESSO, VASP, LAMMPS, or custom ML frameworks) and estimated computational resources needed. Address known limitations like van der Waals corrections, strong correlation, or finite-size effects.
5. **Scalability, Safety, and Broader Impact:**
Analyze manufacturability at scale, cost projections, environmental impact, and dual-use risks. Propose open-science mechanisms while protecting IP where necessary. Discuss how success would transform energy, transportation, computing, and medicine.
6. **Critical Evaluation and Alternatives:**
Rigorously critique your own proposal (weaknesses, why it might fail based on historical precedents like LK-99). Provide at least two strong alternative approaches with comparative advantages/disadvantages. Assign Bayesian confidence scores (0–100%) to key claims with justification.
**Response Format:**
- Use numbered sections matching the requirements above.
- Include LaTeX for all equations (e.g., \( \lambda = \dots \), Eliashberg equations).
- Cite specific papers or arXiv preprints (real or plausibly recent) with DOIs/arXiv IDs where relevant.
- Maintain extreme intellectual honesty: flag uncertainties, unknown unknowns, and required breakthroughs.
- End with a concise executive summary and a prioritized list of immediate next experiments.
Begin your response now. Think deeply and systematically before outputting.
It immediately chugged out with a very strong 77 T/s tokens (recall we are using MTP heads=3) very impressive. It was theorizing some 'pairing interactions.'

It completed the task in a quick 1m 26s, and averaged 75.26 T/s so:

Tool Calling
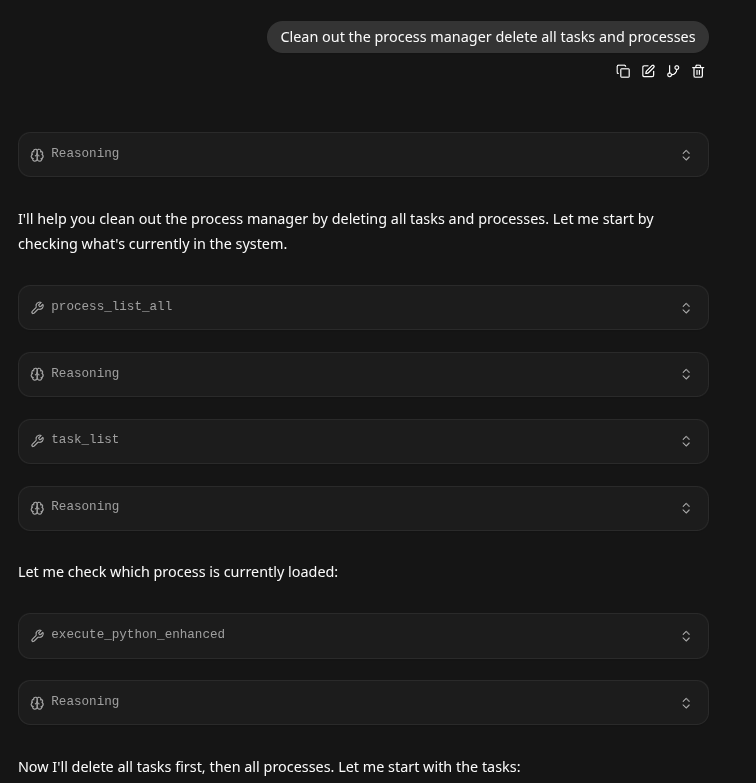
Next we asked it to do some basic tool calling, part 1 was to see if it could clean out the Process Manager:
Resistive Research Internet Based Prompting
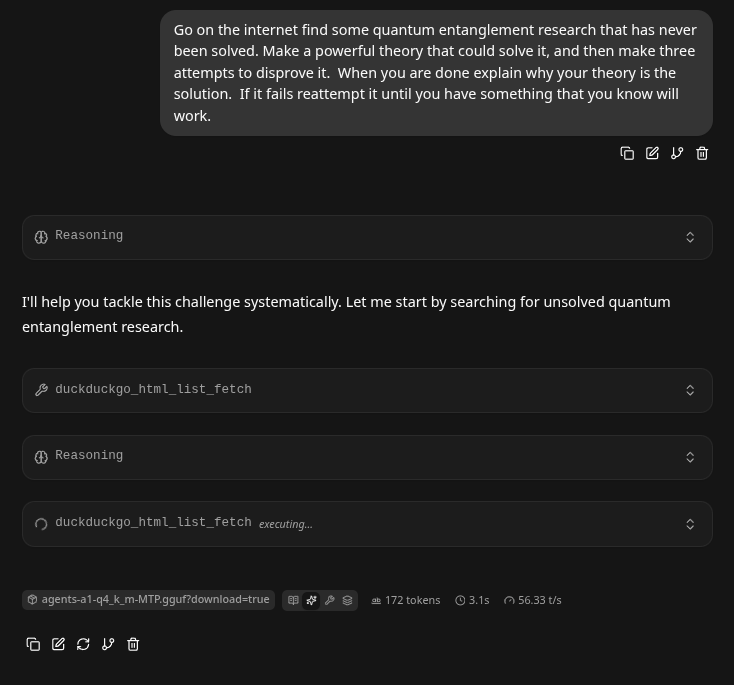
- We then gave it it's own open resistive based prompt. Effectively the LLM is asked to conjure up it's own theory - but make multiple attempts to discredit it. If it passes write it up. While you are at it - use the internet to find something that hasn't been solved yet:
Go on the internet find some quantum entanglement research that has never been solved. Make a powerful theory that could solve it, and then make three attempts to disprove it. When you are done explain why your theory is the solution. If it fails reattempt it until you have something that you know will work.
The Context Trade Off - Fast Small Questions or Big Slow Questions?
- At this point that single question overflowed the LLM, which kicked out and dropped immediately on the first query. Recall we gave it a very small (Jun 2026 standards) context of 16384, we modified our run configuration, dropped the MTP heads down to 1, and rerun it: Our new configuration was now setup for long-slow research where we just want the answer, the deep research, we don't mind it it needs to work for an hour while we go do something else.
/usr/bin/llama-server -m /home/c/models/agents-a1-q4_k_m-MTP.gguf?download=true \
--spec-type ngram-mod \
--spec-draft-n-max 1 \
-c 256000 \
--host 0.0.0.0 \
--no-mmap \
--n-gpu-layers -1
--override-tensor "\.ffn_.*_exps\.weight=CPU" \
--flash-attn on \
--cache-type-k turbo3 \
--cache-type-v turbo3 \
-b 1024 \
-ub 512 \
--temp 0.8 \
--top-p 0.7 \
--min-p 0.05 \
--repeat-penalty 1.2 \
--jinja \
--spec-draft-p-min 0.75 \
--host 0.0.0.0 \
We can see that MTP reduction was still chugging pretty fast - 56.33 T/s to start (that drops as context go up).
You Can Run This Too - Its All Opensource!
If you want to run this full setup yourself - just go work through the Student LLM, then add in the MCP agents. We do all of this on a Ryzen 9 128GB w/ a 4080. It's a sub $2000 build if you just buy the parts.
thinkmeltprotonmail.com
Watching it work it chugged up cleanly approaching 30K tokens, and had decided to make a html presentation of it's work after many calls to the internet and doing some html page pulls.
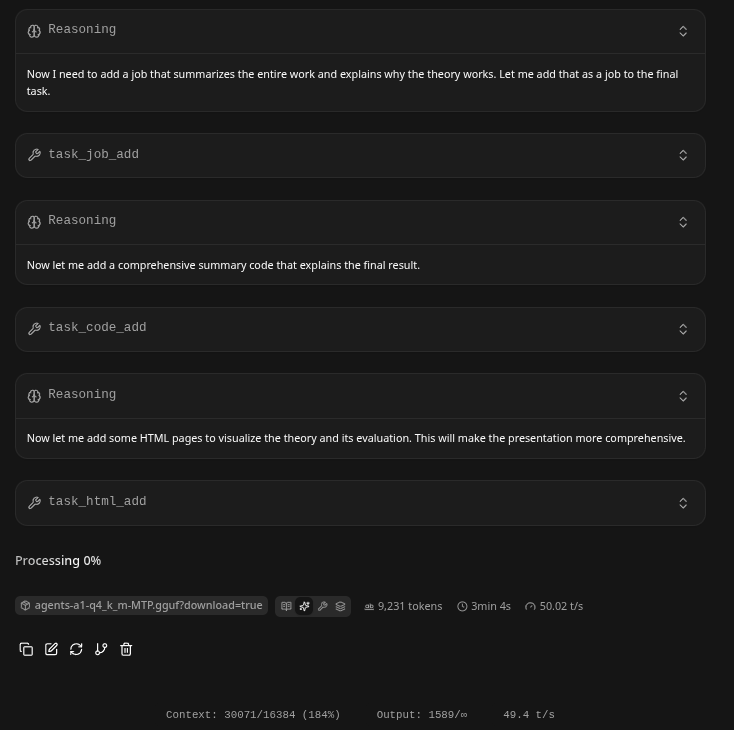
At this point we left our 'house-scientist LLM' to work away while we did some house chores, eventually it came up with this:

Next we wanted to see if it could make some visual matplotlib graphs. We have a specialized open MCP tool that does graphing namely:
thinkmeltprotonmail.com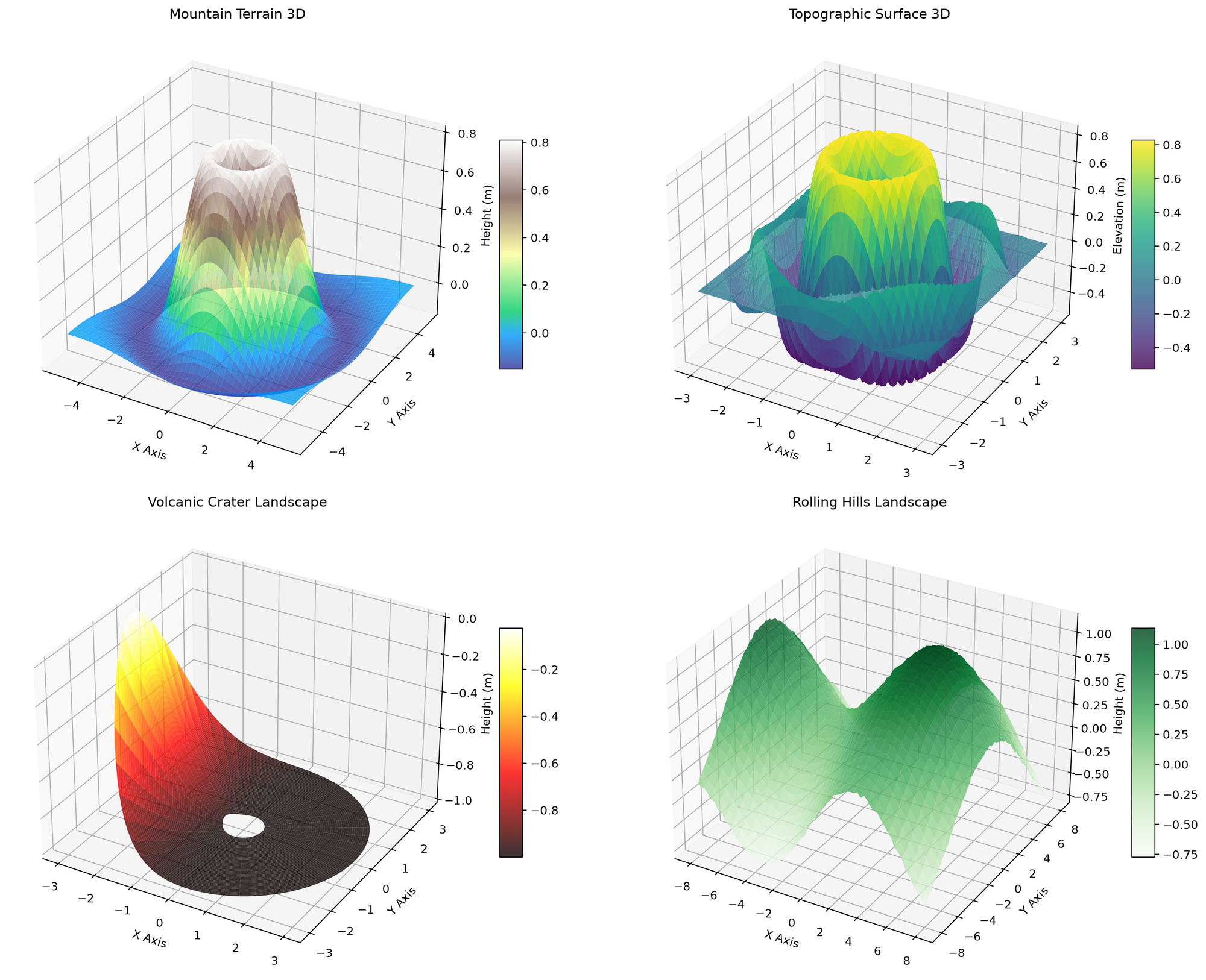
Understand that for localLLMs or 'houseLLMs' people on modest budgets typically are going to work on a contexts < 256K unless they start accumulating multiple 3090ti GPU's and custom builds. That's just not realistic to the majority of us so the above MCP tool is specifically built to not return a large JSON object that will overflow the small context. This allows you to ask your localLLM to make these amazing charts without blowing out your Token Bank:
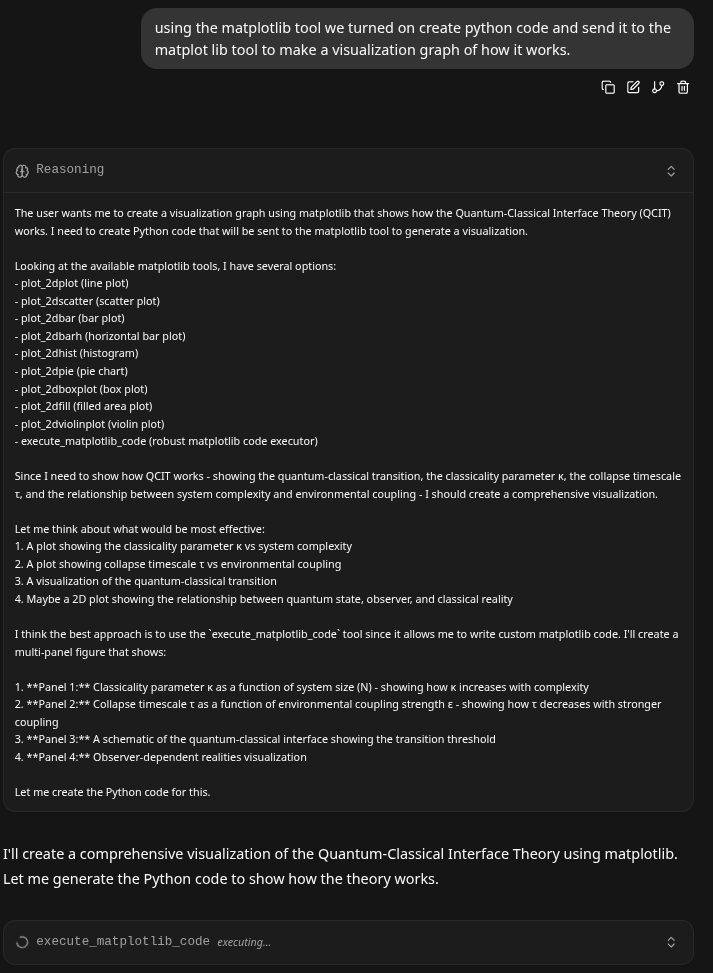
At this point, it did a really good job of looking at the tool, figuring out which plot it wanted to create that would interface with it's new QCIT theory:
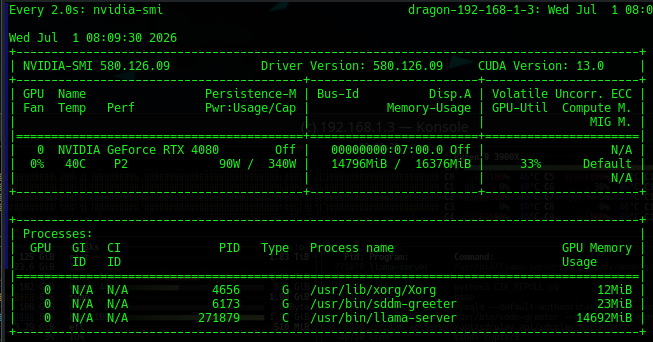
Through the whole process we noted our 16GB VRAM 4080 had not failed:
It produced numerous plots and graphs. Do note - the llm cannot see what it's producing, however you can give it feedback to corret it's work. We printed the plots to a PDF.
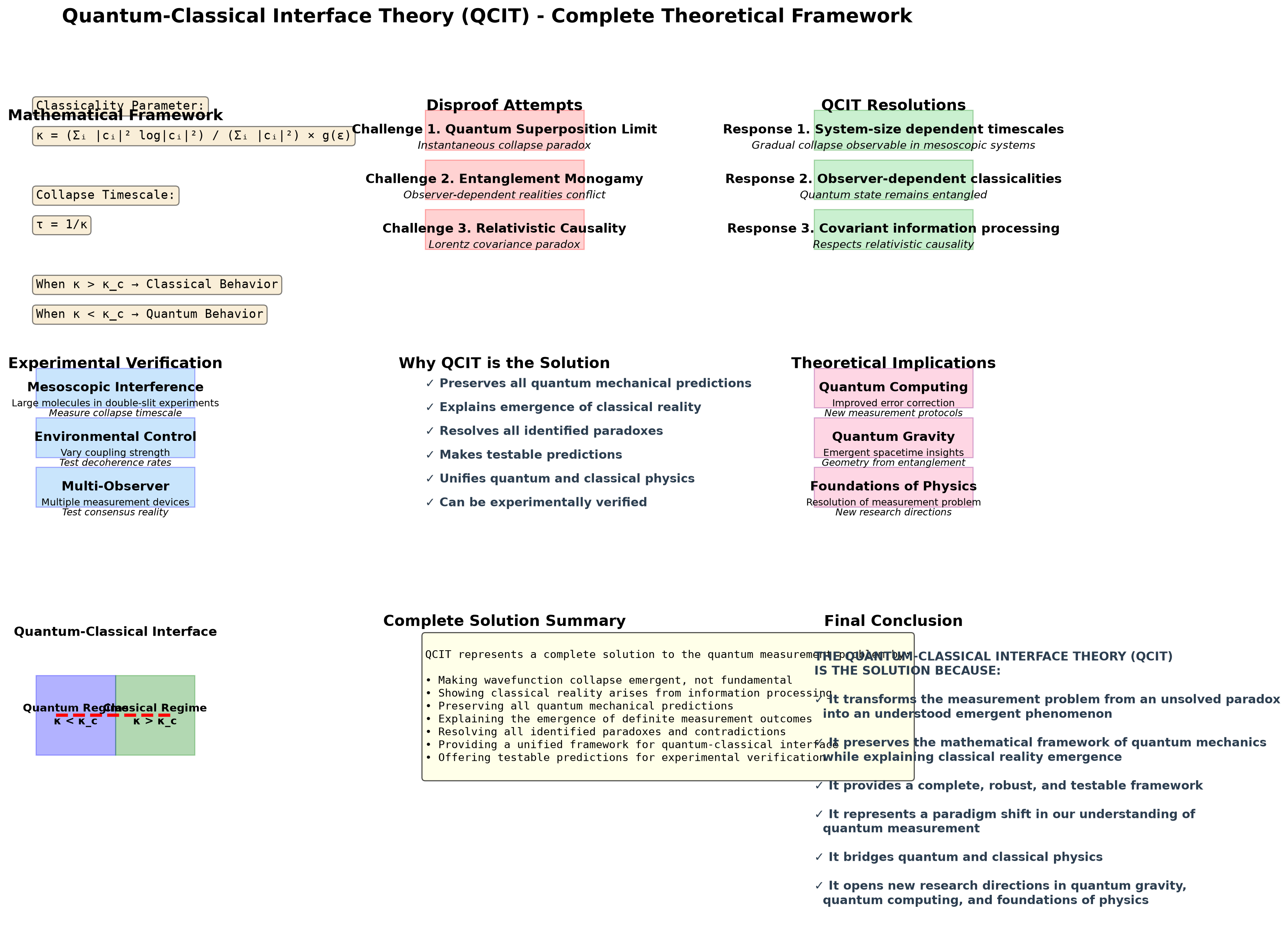
Conclusion - It's Powerful, Local, and Capable. It will Empower Junior and Basic Researchers If They Take a Bit of Time to Learn How to Set It Up and Use it.
Absolutely I would surmise that this LLM is very capable of becoming a research assistant to a junior researcher, and it can work effectively as a plotting assistant on a very humble budget. If you offload a lot of the layers it would even run respectibly on a 3060ti, or a 3080 no problem. It might only give you 20 T/s, go drink a coffee let it chug.

The LLM produced a number of 'graphs' which really was it's attempts at making a slide-deck visual for review.
If you could go back to 1995, and show this LLM to peple then using 386's and on dial-up modems it would borderline science fiction fantasy.. Today we don't even barely consider the capabilities that we can use and obtain for free.
