Qwopus-3.6-35B-A3B-Coder Review. A Powerful LocalLLM Tuned for Coders. It is one of the best 35B sized models we have ever reviewed. Seriously.
Qwopus-3.6-35B-A3B-Coder is a localLLM dream for software developers. Incredibly accurate and powerful prompt processing!


We literally finish one review, and another model drops. The LLM ecosystem moves so fast right now that one can barely finish looking at one model before the next one comes available. You the localLLM user is the benefactor!

We are using the StudentLLM configuration, and a 4080 GPU (16GB VRAM) on a Ryzen 9. That's very modest hardware as in this instance much of the model needed loading to the CPU offloading various layers. What that means is your ability to accomplish things on the ever evolving ecosystem of LLM's is expanding so fast, but you will always be the benefactor. In fact we even showed how potent 8B and 9B sized models can be (A, B)
Our configuration
/usr/bin/llama-server -m Qwopus3.6-35B-A3B-Coder-MTP-Q6_K.gguf?download=true \
--spec-type ngram-mod \
--spec-draft-n-max 3 \
-c 32768 \
--host 0.0.0.0 \
--no-mmap \
--n-gpu-layers -1
--override-tensor "\.ffn_.*_exps\.weight=CPU" \
--flash-attn on \
--cache-type-k turbo3 \
--cache-type-v turbo3 \
-b 1024 \
-ub 512 \
--temp 0.8 \
--top-p 0.7 \
--min-p 0.05 \
--repeat-penalty 1.2 \
--jinja \
--spec-draft-p-min 0.75 \
--host 0.0.0.0 \
--port 8080 \
Loaded as follows:
Out the gate it gave very good tool calling, scripted up some basic pythonic code and we naturally started the 'Benchie Benchmark' of asking it to write it's own Asteroid game.
- We get the LLM to research it's own specs so the prompt might be different each time it looks up a random site on the internet.
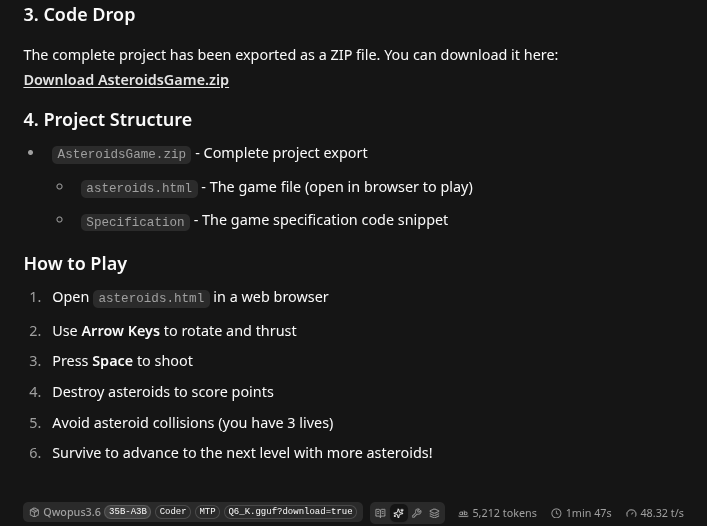
Within 1 min 47 seconds it had produced some quality asteroids, created a code drop point using the process manager MCP. If you need these powerful tool calls they are all available here:
- What was very nice is 48.32 Tokens/s generation. Considering we are using a overflow model that was a whopping 29 GB, squished a bunch of layers to the GPU, and leaving a bunch on the CPU this is working very well.
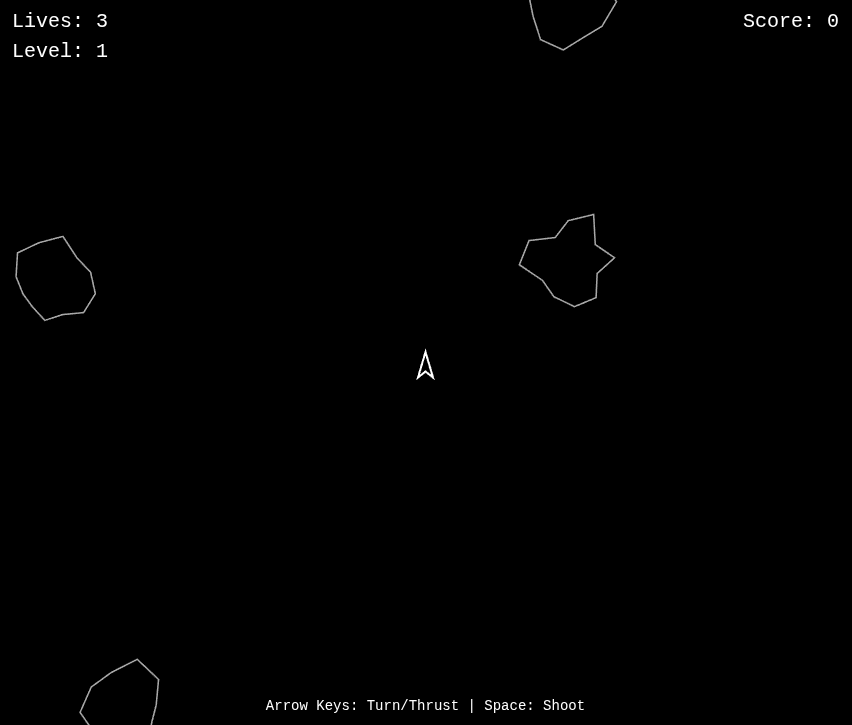
At this point we were quite shocked. It nailed Asteroids cleanly, playable and accurately in a single prompt! We typically accept that if a LLM can create Asteroids in 5-6 prompts it's still a very viable capable LLM, considering that we have seen SOTA models that can muck stuff up on a consistent basis.
Of real interest is that we are running --spec-draft-n-max 3 and getting very good 48 Tokens/s
Long Context Testing
We then adjusted our configuration, backed off --spec-draft-n-max 0 increased context -c 128000 and restarted it.
Our new configuration:
/usr/bin/llama-server -m Qwopus3.6-35B-A3B-Coder-MTP-Q6_K.gguf?download=true \
--spec-type ngram-mod \
--spec-draft-n-max 0 \
-c 128000 \
--host 0.0.0.0 \
--no-mmap \
--n-gpu-layers -1
--override-tensor "\.ffn_.*_exps\.weight=CPU" \
--flash-attn on \
--cache-type-k turbo3 \
--cache-type-v turbo3 \
-b 1024 \
-ub 512 \
--temp 0.8 \
--top-p 0.7 \
--min-p 0.05 \
--repeat-penalty 1.2 \
--jinja \
--spec-draft-p-min 0.75 \
--host 0.0.0.0 \
--port 8080 \We gave it a very challenging prompt that most LLM's will normally not be able to complete on their own - that is self-prompt expansion and application development.
The load on the Nvidia 4080 sat as follows:
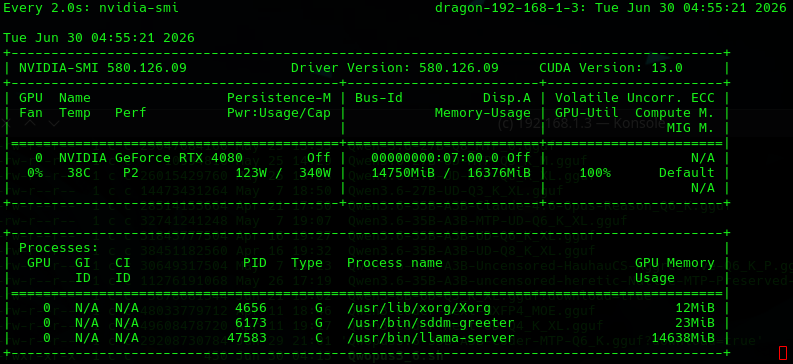
It showed no issues doing iterative research and development of it's task.
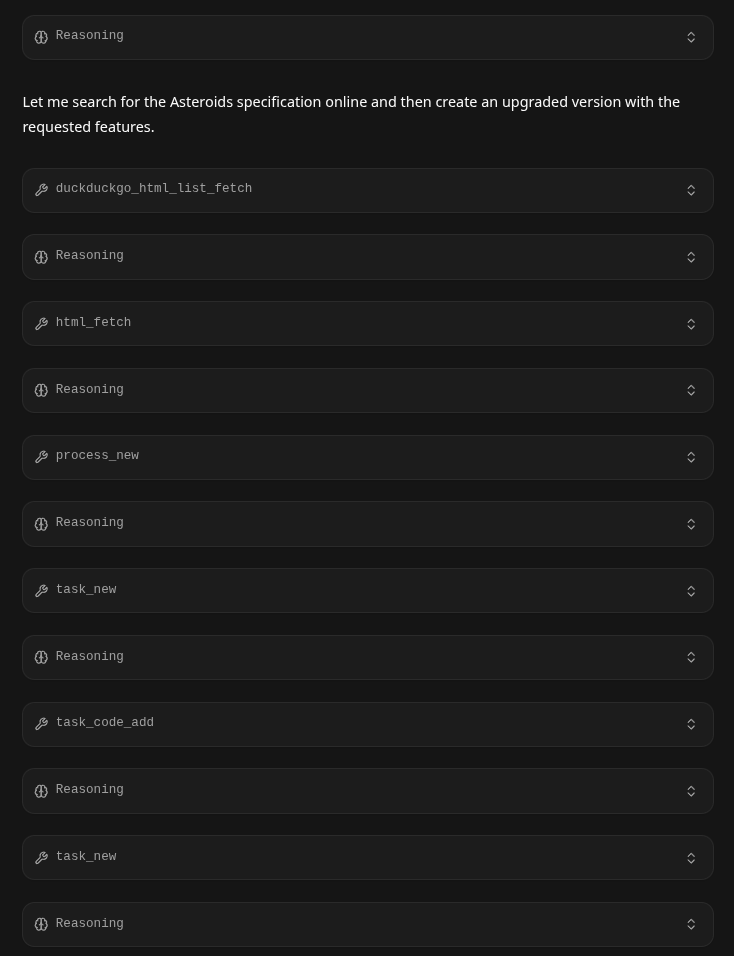
At 28,000 tokens it was still chugging at 40 Tokens/s not bad!

At about roughly approaching the 5 minute mark it was finished:

At this point we could see that it had generated two html detailed web pages, plus some python specifications, but did not actually generate the game itself.
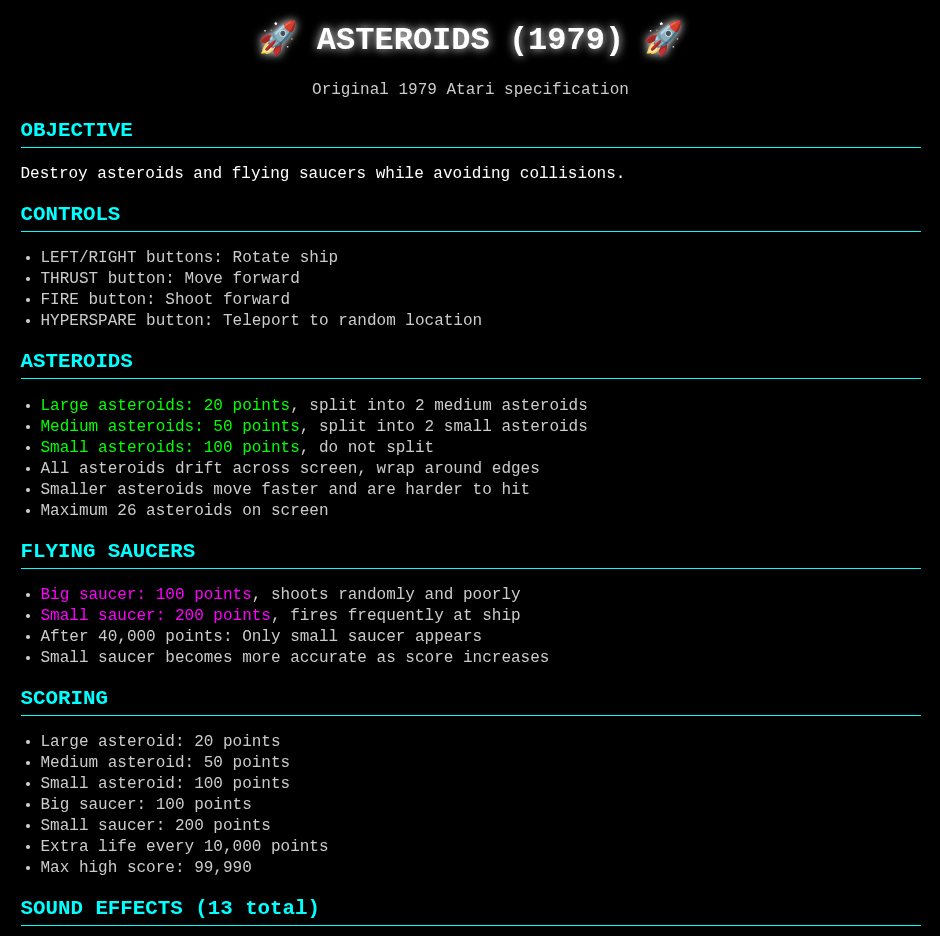
That was on Us!
We realized at this point it had done exactly what we asked it to do - it upgraded the specification but did not actually write the game - we didn't ask it!
It was also interesting in that it ran concurrently with either the GPU floored at 90%+ or the GPU semi-idle at 30% while the cores on the Ryzen hauled.
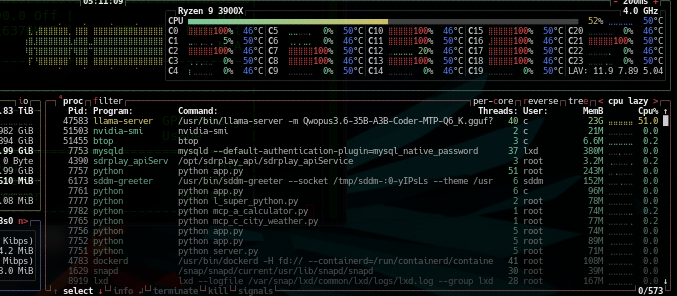
It should be noted it built a beautiful structure using the Process Manager
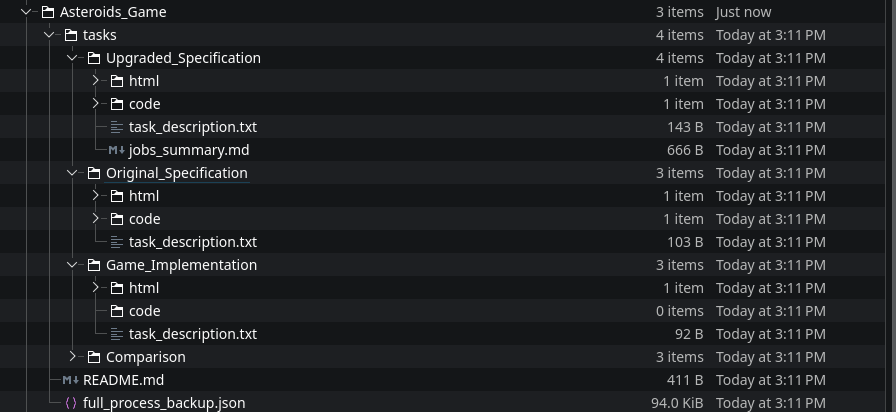
Near perfect. Wow Now Go Write the Actual Game Please..
- This clearly is a prompt crusher of an LLM. It did exactly what we asked it to do. There was a few flaws in the game, but we could tell that it would nail the corrections out of the gate.
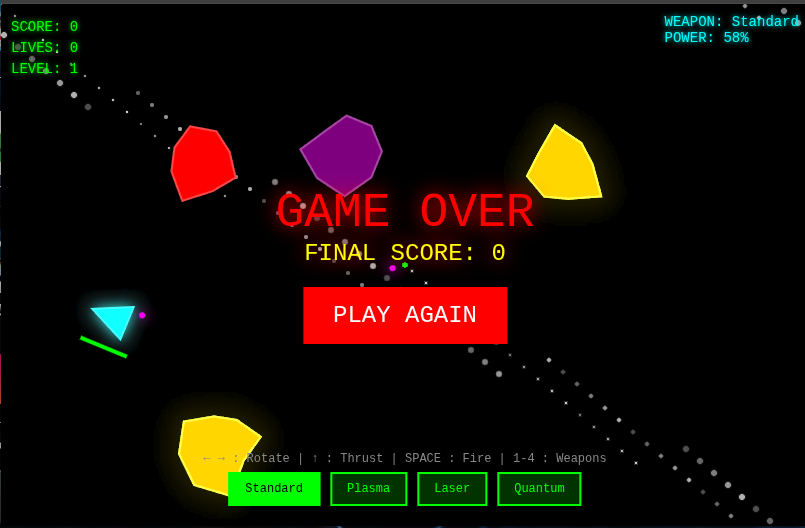
This is a Top Tier LLM in the 35B Class
- There is no question that this model in its weight class is more than a daily driver, it is clearly up there with Ornith 1.0 and I leave it to you which one you want (run both!) We would suspect that Ornith might work at a slightly higher level, but this is one of the most accurate prompt followers we have ever seen. It is very rare for prompts to be fulfilled this accurately. But this is a utterly powerful LLM and we expect that it will become a flagship model at huggingface.com
