Agentic Server Primer: Llama.cpp MCP Lesson 8: Process Manager Web Enabled Research Assistant w/ Code Drop.
Agentic Server Primer: Llama.cpp MCP Lesson 8: Process Manager Web Enabled Research Assistant


In our previous lesson we built a Process Manager for our HouseLLM. This was VERY powerful because now enabled anyone to continue a context or break it up into pieces and not lose it's work - all locally from your own gear. But why not add the feature of research - of going onto the Internet and looking stuff up. Our previous lesson for your reference:
If you just need to pull and run this docker here it is!
docker pull docker.io/cnmcdee/mcp-process-manager:latest
docker run -d --name mcp-process-manager --restart unless-stopped -e "FLASH_ENV=production" -p 0.0.0.0:5008:5008 cnmcdee/mcp-process-manager:latest thinkmeltprotonmail.com
thinkmeltprotonmail.com
Adding this was literally a command to your local AI, and it dutifully wrote and added this for us.
We added effective only a few tools, and had our LLM change the structure.
# ── HTML-page tools ─────────────────────────────────────────────────────
mcp.add_tool(task_manager.task_html_add)
mcp.add_tool(task_manager.task_html_get)
mcp.add_tool(task_manager.task_html_delete)
mcp.add_tool(task_manager.task_html_update)
# ── Web-fetching tools ───────────────────────────────────────────────
mcp.add_tool(task_manager.duckduckgo_html_list_fetch)
mcp.add_tool(task_manager.html_fetch)
# ── Enhanced code_drop tool (now packages everything) ───────────────
mcp.add_tool(task_manager.code_drop)Code Drop
- Because this tool can enable your LLM to generate MASSIVE amounts of code overnight, you can ask your LLM to do a 'code_drop' The back function will automatically parse all the code snippets into a ZIP, it will create a temporary download link with it's work! Serious time saver!
- Note - this will generate a link to localhost, just change it to an ip address if this is not your local machine or a headless unit.
- Nicee... A typical structure built and packed for your download..
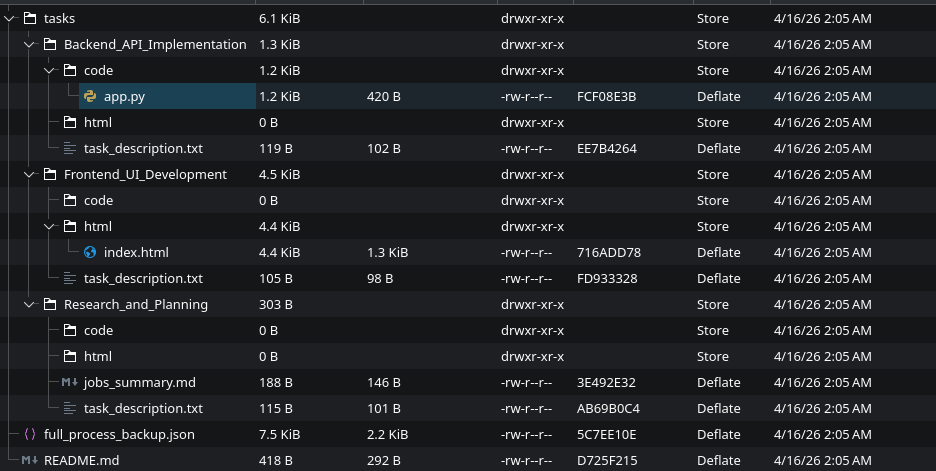
Full Code
- You might need to install some of the support pacakges - naturally. A very easy way to do this is just install pycharm, then cut and paste this code into any open app.py - because pycharm is very supportive it will take care of buidling your venv, and or instaling the neccessary packages to run it!
import re
import json
import os
from datetime import datetime
import requests
from bs4 import BeautifulSoup
from urllib.parse import urlparse, parse_qs
from fastmcp import FastMCP
from fastmcp.tools import tool
from starlette.middleware import Middleware
from starlette.middleware.cors import CORSMiddleware
from starlette.staticfiles import StaticFiles
import uvicorn
import tempfile
import shutil
from pathlib import Path
# Initialize the MCP server
mcp = FastMCP(
name="Process Manager",
instructions="Provides a process manager for tracking tasks and their associated jobs, code blocks, and HTML pages. "
"Also includes web-search (DuckDuckGo) and webpage-fetching tools for retrieving external content.")
# Directory for downloadable ZIP files (served statically at /downloads)
DOWNLOADS_DIR = Path("downloads")
DOWNLOADS_DIR.mkdir(exist_ok=True)
class TaskManager:
def __init__(self, storage_dir: str = "processes"):
self.storage_dir = storage_dir
os.makedirs(self.storage_dir, exist_ok=True)
self.current_process = None
self.current_process_file = None
def _sanitize_name(self, name: str) -> str:
"""Sanitize user-supplied name to prevent path traversal and invalid filenames."""
if not name or not str(name).strip():
name = "unnamed_process"
safe_name = re.sub(r'[^a-zA-Z0-9_.-]', '_', str(name).strip())
return safe_name[:150]
def _get_filepath(self, name: str) -> str:
"""Return full path to the sanitized JSON file."""
safe_name = self._sanitize_name(name)
if not safe_name.endswith('.json'):
safe_name += '.json'
return os.path.join(self.storage_dir, safe_name)
def _save_current(self):
"""Persist the current process to disk."""
if self.current_process and self.current_process_file:
filepath = self._get_filepath(self.current_process_file)
with open(filepath, 'w', encoding='utf-8') as f:
json.dump(self.current_process, f, indent=2, ensure_ascii=False)
def _load_process(self, name: str) -> bool:
"""Load a process from disk and update internal state."""
filepath = self._get_filepath(name)
if not os.path.exists(filepath):
return False
try:
with open(filepath, 'r', encoding='utf-8') as f:
self.current_process = json.load(f)
self.current_process_file = name
return True
except Exception:
return False
@tool()
def process_new(self, name: str, description: str):
"""Creates a new process with the given name and description."""
try:
name = str(name).strip()
if not name:
return json.dumps({"success": False, "error": "Process name cannot be empty."})
filepath = self._get_filepath(name)
if os.path.exists(filepath):
return json.dumps({"success": False, "error": f"Process '{name}' already exists."})
self.current_process = {
"process_name": name,
"description": description,
"created_at": datetime.now().isoformat(),
"tasks": {}
}
self.current_process_file = name
self._save_current()
return json.dumps({
"success": True,
"message": f"Process '{name}' created successfully.",
"process": self.current_process
})
except Exception as e:
return json.dumps({"success": False, "error": str(e)})
@tool()
def process_load(self, name: str):
"""Loads an existing process by name."""
try:
if self._load_process(name):
task_count = len(self.current_process.get("tasks", {}))
return json.dumps({
"success": True,
"message": f"Process '{name}' loaded successfully.",
"process_name": self.current_process.get("process_name"),
"task_count": task_count,
"process_data": self.current_process
})
return json.dumps({
"success": False,
"error": f"Process '{name}' not found."
})
except Exception as e:
return json.dumps({"success": False, "error": str(e)})
@tool()
def process_list_all(self):
"""Lists all saved processes."""
try:
files = [f for f in os.listdir(self.storage_dir) if f.endswith('.json')]
process_list = [{"process": f.replace('.json', '')} for f in files]
return json.dumps({
"success": True,
"process_list": process_list,
"total": len(process_list)
})
except Exception as e:
return json.dumps({"success": False, "error": str(e), "process_list": []})
@tool()
def process_save(self, name: str = None):
"""Saves the current process, optionally renaming it."""
try:
if not self.current_process:
return json.dumps({
"success": False,
"error": "No active process to save. Create or load a process first."
})
if name:
name = str(name).strip()
self.current_process["process_name"] = name
self.current_process_file = name
self._save_current()
return json.dumps({
"success": True,
"message": f"Process saved successfully as '{self.current_process_file}'.",
"process_name": self.current_process.get("process_name")
})
except Exception as e:
return json.dumps({"success": False, "error": str(e)})
@tool()
def process_delete(self, name: str):
"""Deletes an entire process and its associated file from storage.
If the deleted process is currently loaded, the in-memory state is cleared."""
try:
name = str(name).strip()
if not name:
return json.dumps({"success": False, "error": "Process name cannot be empty."})
filepath = self._get_filepath(name)
if not os.path.exists(filepath):
return json.dumps({
"success": False,
"error": f"Process '{name}' not found."
})
os.remove(filepath)
if (self.current_process_file and
self._sanitize_name(self.current_process_file) == self._sanitize_name(name)):
self.current_process = None
self.current_process_file = None
return json.dumps({
"success": True,
"message": f"Process '{name}' deleted successfully.",
"deleted_process": name
})
except Exception as e:
return json.dumps({"success": False, "error": str(e)})
@tool()
def task_new(self, task_name: str, task_description: str):
"""Creates a new task within the current process."""
try:
if not self.current_process:
return json.dumps({"success": False, "error": "No active process. Create or load one first."})
if task_name in self.current_process["tasks"]:
return json.dumps({"success": False, "error": f"Task '{task_name}' already exists."})
self.current_process["tasks"][task_name] = {
"description": task_description,
"created_at": datetime.now().isoformat(),
"jobs": {},
"code": {},
"html_pages": {}
}
self._save_current()
return json.dumps({
"success": True,
"message": f"Task '{task_name}' created successfully.",
"task": self.current_process["tasks"][task_name]
})
except Exception as e:
return json.dumps({"success": False, "error": str(e)})
@tool()
def task_list(self):
"""Lists all tasks with summary information."""
try:
if not self.current_process:
return json.dumps({"success": False, "error": "No active process."})
tasks_summary = {}
for t_name, t_data in self.current_process["tasks"].items():
tasks_summary[t_name] = {
"description": t_data["description"],
"created_at": t_data["created_at"],
"job_count": len(t_data.get("jobs", {})),
"code_count": len(t_data.get("code", {})),
"html_count": len(t_data.get("html_pages", {}))
}
return json.dumps({
"success": True,
"task_count": len(tasks_summary),
"tasks": tasks_summary
}, indent=2)
except Exception as e:
return json.dumps({"success": False, "error": str(e)})
@tool()
def task_details_get(self, task_name: str):
"""Retrieves complete details of a specific task."""
try:
if not self.current_process or task_name not in self.current_process["tasks"]:
return json.dumps({"success": False, "error": f"Task '{task_name}' does not exist."})
task_data = self.current_process["tasks"][task_name]
return json.dumps({
"success": True,
"task_name": task_name,
"task_description": task_data["description"],
"created_at": task_data["created_at"],
"jobs": list(task_data.get("jobs", {}).values()),
"codes": list(task_data.get("code", {}).values()),
"html_pages": list(task_data.get("html_pages", {}).values()),
"job_count": len(task_data.get("jobs", {})),
"code_count": len(task_data.get("code", {})),
"html_count": len(task_data.get("html_pages", {}))
}, indent=2)
except Exception as e:
return json.dumps({"success": False, "error": str(e)})
@tool()
def task_update_description(self, task_name: str, new_description: str):
"""Updates the description of an existing task."""
try:
if not self.current_process or task_name not in self.current_process["tasks"]:
return json.dumps({"success": False, "error": f"Task '{task_name}' does not exist."})
old_description = self.current_process["tasks"][task_name]["description"]
self.current_process["tasks"][task_name]["description"] = new_description
self._save_current()
return json.dumps({
"success": True,
"message": f"Task '{task_name}' description updated successfully.",
"task_name": task_name,
"old_description": old_description,
"new_description": new_description
})
except Exception as e:
return json.dumps({"success": False, "error": str(e)})
@tool()
def task_name_change(self, old_task_name: str, new_task_name: str):
"""Renames an existing task."""
try:
if not self.current_process:
return json.dumps({"success": False, "error": "No active process."})
if old_task_name not in self.current_process["tasks"]:
return json.dumps({"success": False, "error": f"Task '{old_task_name}' does not exist."})
if new_task_name in self.current_process["tasks"]:
return json.dumps({"success": False, "error": f"Task '{new_task_name}' already exists."})
self.current_process["tasks"][new_task_name] = self.current_process["tasks"].pop(old_task_name)
self._save_current()
return json.dumps({
"success": True,
"message": f"Task renamed from '{old_task_name}' to '{new_task_name}' successfully.",
"old_name": old_task_name,
"new_name": new_task_name
})
except Exception as e:
return json.dumps({"success": False, "error": str(e)})
@tool()
def task_delete(self, task_name: str):
"""Deletes a task from the current process."""
try:
if not self.current_process or task_name not in self.current_process["tasks"]:
return json.dumps({"success": False, "error": f"Task '{task_name}' does not exist."})
del self.current_process["tasks"][task_name]
self._save_current()
return json.dumps({
"success": True,
"message": f"Task '{task_name}' deleted successfully."
})
except Exception as e:
return json.dumps({"success": False, "error": str(e)})
@tool()
def task_job_add(self, task_name: str, job_name: str, job_description: str):
"""Adds a job to the specified task."""
try:
if not self.current_process or task_name not in self.current_process["tasks"]:
return json.dumps({"success": False, "error": f"Task '{task_name}' does not exist."})
job_key = f"{job_name}_{datetime.now().isoformat()}"
self.current_process["tasks"][task_name]["jobs"][job_key] = {
"name": job_name,
"description": job_description,
"created_at": datetime.now().isoformat()
}
self._save_current()
return json.dumps({
"success": True,
"message": f"Job '{job_name}' added to task '{task_name}' successfully."
})
except Exception as e:
return json.dumps({"success": False, "error": str(e)})
@tool()
def task_job_get(self, task_name: str, job_name: str):
"""Retrieves job(s) matching the given job_name (partial match)."""
try:
if not self.current_process or task_name not in self.current_process["tasks"]:
return json.dumps({"success": False, "error": f"Task '{task_name}' does not exist."})
jobs = self.current_process["tasks"][task_name].get("jobs", {})
matching = [data for key, data in jobs.items() if job_name in key or job_name == data.get("name")]
return json.dumps({
"success": True,
"task_name": task_name,
"jobs": matching
}, indent=2)
except Exception as e:
return json.dumps({"success": False, "error": str(e)})
@tool()
def task_code_add(self, task_name: str, code_name: str, code_content: str):
"""Adds a code snippet to the specified task."""
try:
if not self.current_process or task_name not in self.current_process["tasks"]:
return json.dumps({"success": False, "error": f"Task '{task_name}' does not exist."})
code_key = f"{code_name}_{datetime.now().isoformat()}"
self.current_process["tasks"][task_name]["code"][code_key] = {
"name": code_name,
"content": code_content,
"created_at": datetime.now().isoformat()
}
self._save_current()
return json.dumps({
"success": True,
"message": f"Code '{code_name}' added to task '{task_name}' successfully."
})
except Exception as e:
return json.dumps({"success": False, "error": str(e)})
@tool()
def task_code_get(self, task_name: str, code_name: str):
"""Retrieves code snippet(s) matching the given code_name (partial match)."""
try:
if not self.current_process or task_name not in self.current_process["tasks"]:
return json.dumps({"success": False, "error": f"Task '{task_name}' does not exist."})
codes = self.current_process["tasks"][task_name].get("code", {})
matching = [data for key, data in codes.items() if code_name in key or code_name == data.get("name")]
return json.dumps({
"success": True,
"task_name": task_name,
"codes": matching
}, indent=2)
except Exception as e:
return json.dumps({"success": False, "error": str(e)})
@tool()
def task_code_delete(self, task_name: str, code_name: str):
"""Deletes code snippet(s) matching the given code_name (partial match)."""
try:
if not self.current_process or task_name not in self.current_process["tasks"]:
return json.dumps({"success": False, "error": f"Task '{task_name}' does not exist."})
codes = self.current_process["tasks"][task_name].get("code", {})
keys_to_delete = [k for k in codes if code_name in k or code_name == codes[k].get("name")]
deleted = [codes[k] for k in keys_to_delete]
for k in keys_to_delete:
del self.current_process["tasks"][task_name]["code"][k]
self._save_current()
if not deleted:
return json.dumps({
"success": False,
"message": f"No code matching '{code_name}' found in task '{task_name}'.",
"task_name": task_name,
"code_name": code_name
})
return json.dumps({
"success": True,
"message": f"Deleted {len(deleted)} code snippet(s) matching '{code_name}'.",
"task_name": task_name,
"deleted_count": len(deleted),
"deleted_codes": deleted
})
except Exception as e:
return json.dumps({"success": False, "error": str(e)})
@tool()
def task_html_add(self, task_name: str, html_name: str, html_content: str):
"""Adds an HTML page to the specified task."""
try:
if not self.current_process or task_name not in self.current_process["tasks"]:
return json.dumps({"success": False, "error": f"Task '{task_name}' does not exist."})
html_key = f"{html_name}_{datetime.now().isoformat()}"
self.current_process["tasks"][task_name]["html_pages"][html_key] = {
"name": html_name,
"content": html_content,
"created_at": datetime.now().isoformat()
}
self._save_current()
return json.dumps({
"success": True,
"message": f"HTML page '{html_name}' added to task '{task_name}' successfully."
})
except Exception as e:
return json.dumps({"success": False, "error": str(e)})
@tool()
def task_html_get(self, task_name: str, html_name: str):
"""Retrieves HTML page(s) matching the given html_name (partial match)."""
try:
if not self.current_process or task_name not in self.current_process["tasks"]:
return json.dumps({"success": False, "error": f"Task '{task_name}' does not exist."})
html_pages = self.current_process["tasks"][task_name].get("html_pages", {})
matching = [data for key, data in html_pages.items() if html_name in key or html_name == data.get("name")]
return json.dumps({
"success": True,
"task_name": task_name,
"html_pages": matching
}, indent=2)
except Exception as e:
return json.dumps({"success": False, "error": str(e)})
@tool()
def task_html_delete(self, task_name: str, html_name: str):
"""Deletes HTML page(s) matching the given html_name (partial match)."""
try:
if not self.current_process or task_name not in self.current_process["tasks"]:
return json.dumps({"success": False, "error": f"Task '{task_name}' does not exist."})
html_pages = self.current_process["tasks"][task_name].get("html_pages", {})
keys_to_delete = [k for k in html_pages if html_name in k or html_name == html_pages[k].get("name")]
deleted = [html_pages[k] for k in keys_to_delete]
for k in keys_to_delete:
del self.current_process["tasks"][task_name]["html_pages"][k]
self._save_current()
if not deleted:
return json.dumps({
"success": False,
"message": f"No HTML page matching '{html_name}' found in task '{task_name}'.",
"task_name": task_name,
"html_name": html_name
})
return json.dumps({
"success": True,
"message": f"Deleted {len(deleted)} HTML page(s) matching '{html_name}'.",
"task_name": task_name,
"deleted_count": len(deleted),
"deleted_html_pages": deleted
})
except Exception as e:
return json.dumps({"success": False, "error": str(e)})
@tool()
def task_html_update(self, task_name: str, html_name: str, new_content: str):
"""Updates (by creating a new version of) an HTML page."""
try:
if not self.current_process or task_name not in self.current_process["tasks"]:
return json.dumps({"success": False, "error": f"Task '{task_name}' does not exist."})
html_key = f"{html_name}_{datetime.now().isoformat()}"
self.current_process["tasks"][task_name]["html_pages"][html_key] = {
"name": html_name,
"content": new_content,
"created_at": datetime.now().isoformat()
}
self._save_current()
return json.dumps({
"success": True,
"message": f"HTML page '{html_name}' updated successfully in task '{task_name}'.",
"new_version_created": True
})
except Exception as e:
return json.dumps({"success": False, "error": str(e)})
@tool()
def duckduckgo_html_list_fetch(self, query: str, max_results: int = 5):
"""Searches DuckDuckGo via its HTML endpoint and returns a list of results (title, URL, snippet)."""
try:
query = str(query).strip()
if not query:
return json.dumps({"success": False, "error": "Search query cannot be empty."})
search_url = f"https://duckduckgo.com/html/?q={requests.utils.quote(query)}"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 "
"(KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36"
}
resp = requests.get(search_url, headers=headers, timeout=15)
resp.raise_for_status()
soup = BeautifulSoup(resp.text, "html.parser")
results = []
for item in soup.select(".result__body")[:max_results]:
a_tag = item.select_one(".result__a")
snippet_tag = item.select_one(".result__snippet")
if a_tag:
title = a_tag.get_text(strip=True)
href = a_tag.get("href", "")
if "uddg=" in href:
href = href.split("uddg=")[1].split("&")[0]
href = requests.utils.unquote(href)
snippet = snippet_tag.get_text(strip=True) if snippet_tag else ""
results.append({
"title": title,
"url": href,
"snippet": snippet
})
return json.dumps({
"success": True,
"query": query,
"result_count": len(results),
"results": results
}, indent=2)
except Exception as e:
return json.dumps({"success": False, "error": f"DuckDuckGo search failed: {str(e)}"})
@tool()
def html_fetch(self, url: str):
"""Fetches a webpage and returns clean, readable text content parsed by BeautifulSoup."""
try:
url = str(url).strip()
if not url.startswith(("http://", "https://")):
url = "https://" + url
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 "
"(KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36"
}
resp = requests.get(url, headers=headers, timeout=20)
resp.raise_for_status()
soup = BeautifulSoup(resp.text, "html.parser")
for unwanted in soup(["script", "style", "nav", "header", "footer", "aside", "form", "button"]):
unwanted.decompose()
text = soup.get_text(separator="\n", strip=True)
if len(text) > 40000:
text = text[:40000] + "\n\n[Content truncated due to length...]"
page_title = soup.title.string.strip() if soup.title else "No title found"
return json.dumps({
"success": True,
"url": url,
"title": page_title,
"content_length": len(text),
"text": text
}, indent=2)
except Exception as e:
return json.dumps({"success": False, "error": str(e)})
@tool()
def task_jobs_list(self):
"""Lists all tasks (identical to task_list for compatibility)."""
return self.task_list()
@tool()
def task_code_update(self, task_name: str, code_name: str, new_content: str):
"""Updates (by creating a new version of) a code snippet."""
try:
if not self.current_process or task_name not in self.current_process["tasks"]:
return json.dumps({"success": False, "error": f"Task '{task_name}' does not exist."})
code_key = f"{code_name}_{datetime.now().isoformat()}"
self.current_process["tasks"][task_name]["code"][code_key] = {
"name": code_name,
"content": new_content,
"created_at": datetime.now().isoformat()
}
self._save_current()
return json.dumps({
"success": True,
"message": f"Code '{code_name}' updated successfully in task '{task_name}'.",
"new_version_created": True
})
except Exception as e:
return json.dumps({"success": False, "error": str(e)})
@tool()
def code_drop(self, custom_filename: str = None):
"""Packages the ENTIRE process: all code snippets, all HTML pages, full process metadata (configuration), task descriptions, and jobs into a well-organized ZIP archive with clean folder structure."""
try:
if not self.current_process:
return json.dumps({"success": False, "error": "No active process. Create or load a process first."})
process_name = self.current_process.get("process_name", "unnamed_process")
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
# Determine ZIP filename
if custom_filename:
zip_name = custom_filename if custom_filename.endswith('.zip') else f"{custom_filename}.zip"
else:
zip_name = f"full_export_{process_name}_{timestamp}.zip"
with tempfile.TemporaryDirectory() as tmp_dir:
tmp_path = Path(tmp_dir)
root_dir = tmp_path / f"{process_name}_{timestamp}"
root_dir.mkdir(parents=True, exist_ok=True)
# 1. Save complete process metadata (this acts as the master configuration file)
(root_dir / "full_process_backup.json").write_text(
json.dumps(self.current_process, indent=2, ensure_ascii=False),
encoding="utf-8"
)
# 2. Create tasks directory with organized content
tasks_dir = root_dir / "tasks"
tasks_dir.mkdir(exist_ok=True)
total_code = 0
total_html = 0
for task_name, task_data in self.current_process.get("tasks", {}).items():
safe_task_name = self._sanitize_name(task_name)
task_dir = tasks_dir / safe_task_name
task_dir.mkdir(exist_ok=True)
# Task description
desc_path = task_dir / "task_description.txt"
desc_path.write_text(
f"# Task: {task_name}\n\n{task_data.get('description', 'No description provided.')}",
encoding="utf-8"
)
# Jobs summary
jobs = task_data.get("jobs", {})
if jobs:
jobs_md = "# Jobs\n\n"
for job in jobs.values():
jobs_md += f"## {job.get('name', 'Unnamed Job')}\n{job.get('description', '')}\n\n"
(task_dir / "jobs_summary.md").write_text(jobs_md, encoding="utf-8")
# Code snippets
code_dir = task_dir / "code"
code_dir.mkdir(exist_ok=True)
for code_entry in task_data.get("code", {}).values():
code_name = code_entry.get("name", "unnamed_code")
content = code_entry.get("content", "")
if "." not in code_name and not code_name.lower().endswith(('.py', '.js', '.java', '.cpp', '.go', '.rs')):
code_name += ".py"
(code_dir / code_name).write_text(content, encoding="utf-8")
total_code += 1
# HTML pages
html_dir = task_dir / "html"
html_dir.mkdir(exist_ok=True)
for html_entry in task_data.get("html_pages", {}).values():
html_name = html_entry.get("name", "unnamed_page")
content = html_entry.get("content", "")
if not html_name.lower().endswith(('.html', '.htm')):
html_name += ".html"
(html_dir / html_name).write_text(content, encoding="utf-8")
total_html += 1
# 3. Top-level README
readme = f"""# {process_name} - Full Export
**Generated:** {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}
- **Tasks**: {len(self.current_process.get("tasks", {}))}
- **Code files**: {total_code}
- **HTML pages**: {total_html}
## Folder Structure
- `full_process_backup.json` → Complete process data (metadata + everything)
- `tasks/<task_name>/`
- `task_description.txt`
- `jobs_summary.md`
- `code/` → All code snippets
- `html/` → All HTML pages
Ready for development, review, or deployment.
"""
(root_dir / "README.md").write_text(readme, encoding="utf-8")
# Create ZIP archive
zip_base = DOWNLOADS_DIR / zip_name.replace('.zip', '')
shutil.make_archive(str(zip_base), 'zip', root_dir)
download_url = f"http://localhost:5008/downloads/{zip_name}"
return json.dumps({
"success": True,
"message": f"Successfully created full project export for '{process_name}' ({total_code} code files, {total_html} HTML pages).",
"download_url": download_url,
"filename": zip_name,
"code_count": total_code,
"html_count": total_html,
"task_count": len(self.current_process.get("tasks", {}))
}, indent=2)
except Exception as e:
return json.dumps({"success": False, "error": str(e)})
task_manager = TaskManager()
# ── Register all bound methods as tools ─────────────────────
mcp.add_tool(task_manager.process_new)
mcp.add_tool(task_manager.process_load)
mcp.add_tool(task_manager.process_list_all)
mcp.add_tool(task_manager.process_save)
mcp.add_tool(task_manager.process_delete)
mcp.add_tool(task_manager.task_new)
mcp.add_tool(task_manager.task_update_description)
mcp.add_tool(task_manager.task_delete)
mcp.add_tool(task_manager.task_name_change)
mcp.add_tool(task_manager.task_job_add)
mcp.add_tool(task_manager.task_job_get)
mcp.add_tool(task_manager.task_details_get)
mcp.add_tool(task_manager.task_list)
mcp.add_tool(task_manager.task_code_add)
mcp.add_tool(task_manager.task_code_get)
mcp.add_tool(task_manager.task_code_delete)
mcp.add_tool(task_manager.task_jobs_list)
mcp.add_tool(task_manager.task_code_update)
# ── HTML-page tools ─────────────────────────────────────────────────────
mcp.add_tool(task_manager.task_html_add)
mcp.add_tool(task_manager.task_html_get)
mcp.add_tool(task_manager.task_html_delete)
mcp.add_tool(task_manager.task_html_update)
# ── Web-fetching tools ───────────────────────────────────────────────
mcp.add_tool(task_manager.duckduckgo_html_list_fetch)
mcp.add_tool(task_manager.html_fetch)
# ── Enhanced code_drop tool (now packages everything) ───────────────
mcp.add_tool(task_manager.code_drop)
# ── Server Startup with CORS and static downloads route ─────────────────────
if __name__ == "__main__":
middleware = [
Middleware(
CORSMiddleware,
allow_origins=["*"],
allow_credentials=True,
allow_methods=["GET", "POST", "OPTIONS"],
allow_headers=["*"],
expose_headers=["*"],
)
]
app = mcp.http_app(
path="/mcp",
middleware=middleware
)
app.mount("/downloads", StaticFiles(directory=str(DOWNLOADS_DIR)), name="downloads")
uvicorn.run(
app,
host="0.0.0.0",
port=5008,
log_level="info"
)- We stayed on 5008, it is the same port as last, really just an add-on. We'll post the full guide on how to dockerize it at the end of this article. For now - how does it work. Well - Good!
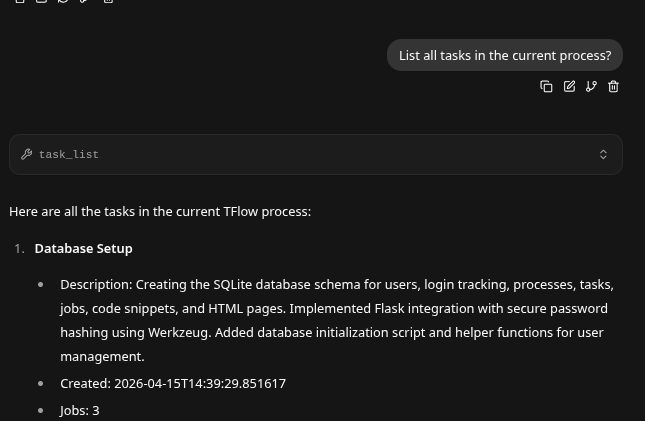
- We now can just work on Task 4 - independent of the entire job.
Context SlowDown
- When you start seriously building production as your context size increases your LLM will slow down. But this is the beauty of this tool - because you can chop your context up into pieces and work on each one. It slowly gave us it's code snippets.
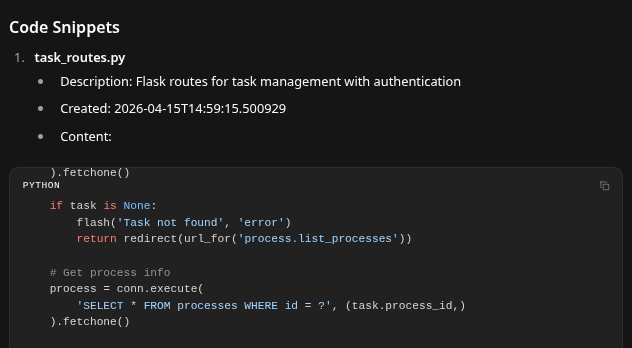
Restart is Now Harmless
- Recycle your work automatically as you can simply start a new context, delete old ones - even assign two LLM's to the same task. That's power!
We Let a LLM Write The Rest..
- We made sure this docker build was based upon the source code, so that requirements matched.
requirements.txt
fastmcp
requests
beautifulsoup4
uvicorn[standard]
starlette
Dockerfile
FROM python:3.12-slim
WORKDIR /app
# Copy and install Python dependencies
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
# Copy the application code
COPY app.py .
# Ensure the storage directory exists (volume mount will override at runtime)
RUN mkdir -p processes
# Expose the port used by the FastMCP server
EXPOSE 5008
# Start the application
CMD ["python", "app.py"]
docker-compose.yml
version: '3.9'
services:
task-manager:
build: .
container_name: task-manager-mcp
ports:
- "5008:5008"
volumes:
- ./processes:/app/processes
restart: unless-stopped
environment:
- PYTHONUNBUFFERED=1
Breakdown of Dockerizing the Application
The provided Python code implements a FastMCP-based process manager server that persists data to JSON files in a processes/ directory, exposes an HTTP endpoint on port 5008 with CORS middleware, and depends on several external libraries. Dockerizing this application ensures consistent runtime environments, isolates dependencies, facilitates reproducible deployments, and simplifies scaling or distribution.
The proposed solution consists of three standard files and assumes the supplied code is saved as app.py in the project root. The directory structure would then be:
.
├── app.py # Your complete Python script
├── requirements.txt
├── Dockerfile
├── docker-compose.yml
└── processes/ # Created automatically; persisted via volume
requirements.txt
This file explicitly declares all non-standard-library dependencies extracted from the imports (fastmcp, requests, beautifulsoup4, uvicorn, and starlette). The [standard] extra for uvicorn includes recommended logging and signal-handling utilities. Using a pinned requirements file guarantees that pip install produces identical environments across builds.
Dockerfile
- Starts from the lightweight
python:3.12-slimbase image to minimize image size and attack surface. - Sets
/appas the working directory and installs dependencies first (leveraging Docker layer caching for faster rebuilds). - Copies
app.pyand creates theprocesses/directory. - Exposes port 5008 to document the service port (the
0.0.0.0binding inside the code ensures accessibility from outside the container). - The
CMDexecutes the script directly, which runsuvicorninternally and starts the FastMCP HTTP application with the registered tools.
docker-compose.yml
This orchestration file defines a single service for straightforward local or production deployment. Key features include:
- Port mapping (
5008:5008) so the MCP endpoint is reachable athttp://localhost:5008/mcp. - A bind mount (
./processes:/app/processes) that persists all JSON process files to the host filesystem. Without this volume, data would be lost on container restart or rebuild. restart: unless-stoppedfor resilience.PYTHONUNBUFFERED=1ensures log output appears immediately indocker logsordocker-composeconsole.
Usage Instructions
- Save the provided code as
app.pyin the project root. - Create the three files listed above.
- (Optional) Create an empty
processes/directory on the host. - Build and start the container:
docker compose up --build -d
- Verify the service:
docker logs task-manager-mcp
The server should bind to 0.0.0.0:5008 and display startup messages from Uvicorn.
- Stop/restart:
docker compose downordocker compose restart.
Additional Considerations
- Persistence: The
TaskManagerclass writes to disk; the volume mount is essential for production use. - Security: CORS is configured to allow all origins (as in the original code). In production, restrict
allow_originsto specific domains. - Scaling: The current setup is single-container; for horizontal scaling, consider a reverse proxy or shared storage.
- Image size and performance: The slim base and
--no-cache-dirkeep the final image compact. No additional system packages are required because all dependencies are pure-Python or have minimal C extensions handled by the base image. - Updates: To change dependencies or the application code, simply edit the respective files and re-run
docker compose up --build.
This configuration provides a complete, production-ready Docker setup that faithfully reproduces the original application behavior while adding portability and data persistence. If any adjustments (e.g., environment variables, multi-stage builds, or health checks) are required, please provide further specifications.
