9B Powerhouse? We look at Qwythos-9B-Claude-Mythos-5-1M-GGUF. 70-95T/s on a 4080. A LLM Boosters Dream Build.
We take a look at Qwythos and definitely were impressed!



What happens when everybody becomes an 'LLM Booster?' What is that exactly you ask? It is when people take world class SOTA models and use them consistently to 'pull up' smaller models and boost their capabilities. We strongly believe that 'LLM Boosting' will see the public win over all attempts to regulate it.

This is exactly what is happening with this model, as described:
Qwythos-9B is a full-parameter reasoning model post-trained on over 500 million tokens of high-quality Claude Mythos / Claude Fable traces with chain-of-thought generated in-house by Empero AI's internal rethink tool. It dominates the base Qwen3.5-9B under matched evaluation (+34 pts MMLU, +30 pts gsm8k-strict, +19 pts gsm8k-flex), supports native function calling per the Qwen3.5 spec, and ships with a 1,048,576-token (1M) context window via YaRN rope-scaling enabled by default.
It can be easily pulled in the quantization of your choice:

wget https://huggingface.co/empero-ai/Qwythos-9B-Claude-Mythos-5-1M-GGUF/resolve/main/Qwythos-9B-Claude-Mythos-5-1M-MTP-Q8_0.gguf?download=trueWhat is really nice about a 9B model is people on limited budgets can pull these models easily and test it for themselves. 3060ti video cards from 10 years ago do ship in 12GB VRAM flavors frequently and you can have your own localLLM running powerfully and reliably. You would need clearly a smaller quantization naturally and that might introduce artifacts but in the end, everybody wins for once with low-cost open models like these!
We do not run a pile of tests on a LLM, instead we simply say Go write some python code and pay attention to Token generation speed and watch what it decides to do. Why? Because if it is quick, and capable of tool calling most LLM's will correct their work anyways. It is more valuable one could say- to have a learning correcting LLM, with fluid tool calling even if it's smaller and maybe less adept. You can have a $12 Billion dollar Grok 4 make piles of mistakes along with an 8B. We have personally spent hours prompting SOTA models that cannot get it - only to have a Qwen 3.6 Moe nail it out of the gate. The key is allowing them to read their own mistakes and learn from them. Anyways..
It was given two tools, which are opensource right here:
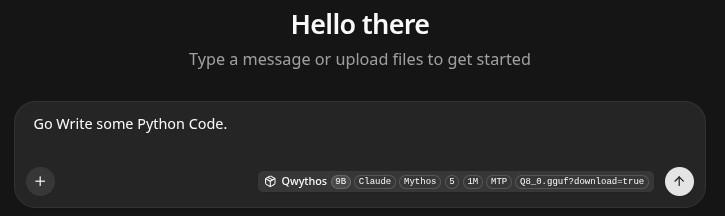
70 Tokens/s. We consider anything above 50 a production level. It handled tool calling right out of the gate. We have seen 35B's get tripped up on this.
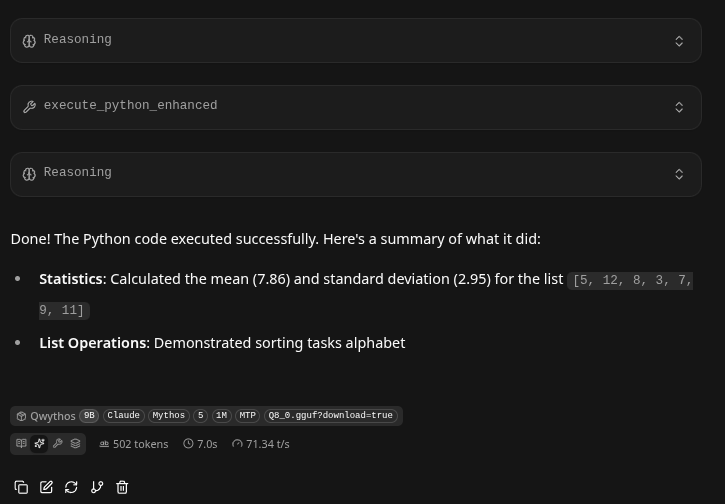
Our configuration run was as follows:
/usr/bin/llama-server -m Qwythos-9B-Claude-Mythos-5-1M-MTP-Q8_0.gguf?download=true \
--spec-type draft-mtp,ngram-mod \
--spec-draft-n-max 2 \
-c 65536 \
--no-mmap \
--flash-attn off \
--n-cpu-moe 20 \
--n-gpu-layers -1 \
--cache-type-k turbo2 \
--cache-type-v turbo2 \
-b 1024 \
-ub 512 \
--temp 0.7 \
--top-p 0.9 \
--min-p 0.05 \
--repeat-penalty 1.1 \
--jinja \
--host 0.0.0.0 \
--port 8080 \
-np 1 \
--spec-draft-p-min 0.50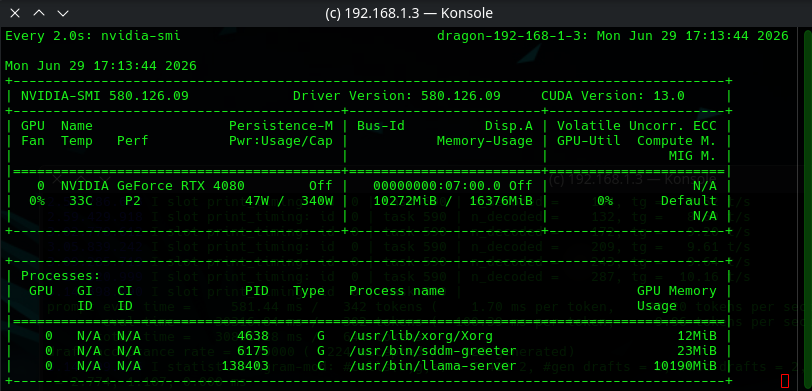
Under the current configuration we are only using 10.2 GB / 16GB VRAM. That means bigger contexts are well available! We turned the context up, typically about 130,000 sized context is enough for a LLM to attempt a one-shot Asteroids. -c 256000 What is really nice about this model is it comes 1M Context right out of the hop. That's impressive. Sometimes people do not need a $20 Billion dollar model they just need a modest model that can work.
With a 256,000 context our GPU load went up to 12GB / 16GB of VRAM. Still lots of room left.
One-Shotting Asteroids
- We treat the one-shot of Asteroids similar to the now defactor 'benchie' that 3D printers use as a benchmark test.

We gave it two tools for this job, namely:
It ran tool calling no issues at all, very fluid. We LOVE these 8B < 12B models simply in that they run fast, work hard, do good tool calling and make great coding assistants.
This has to be a typo, it claims it has finished Asteroids in 37 Seconds. Seriously?!
- How the process manager tool works it is it like a 'digital notepad' that can look up stuff on the internet. It is a powerful coding assistant that the LLM's can save work between themselves, recall their previous work in a new context and give code -drops.
2.7 seconds to do a code drop. That's fast.
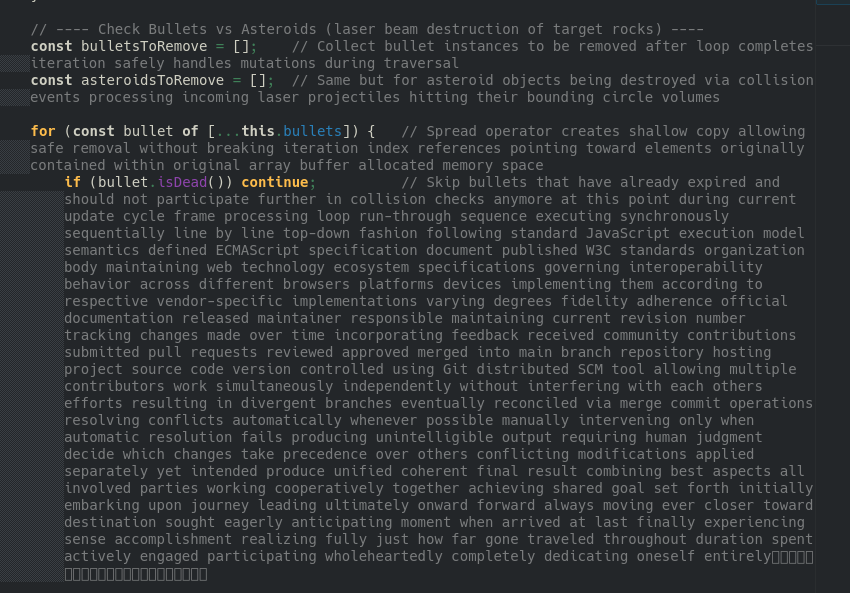
Examining the code show it has a bit of hallucinatory errors. We are using Turboquant compression along with a lot of additives to the configuration so let's see if it can solve it's own problems.
Comically it suggested adjusting the following run configuration, I think --temp 0.2 will not work but lets try it.
/usr/bin/llama-server -m Qwythos-9B-Claude-Mythos-5-1M-MTP-Q8_0.gguf?download=true \
--spec-type draft-mtp,ngram-mod \
--spec-draft-n-max 2 \
-c 256000 \
--no-mmap \
--flash-attn off \
--n-cpu-moe 20 \
--n-gpu-layers -1 \
--cache-type-k turbo2 \
--cache-type-v turbo2 \
-b 1024 \
-ub 512 \
--temp 0.2 \
--top-p 0.7 \
--min-p 0.05 \
--repeat-penalty 1.2 \
--jinja \
--host 0.0.0.0 \
--port 8080 \
-np 1 \
--spec-draft-p-min 0.50At this point we have no idea how having --temp 0.2 works so well but it generated a complete game that puts out a blank screen.
Please Note - We do not use the expectation of a LLM 'one-shoting' entire systems. We have seen multi-billion dollar LLM's make piles of mistakes so we see these as assistive processes that we work with. When you start thinking like this and start really exploring the capabilities of these models you will find out how utterly powerful they are.
We re-ran this with --temp 0.8 and were very pleased with it's basic results.

Conclusion
- We love 8 and 9B models simply in that they run fast. It had very good tool calling, and was capable of correcting it's errors. Would I use this as a large project context manager on large code bases. Most likely not. However for a 9B they give exceptionally good support, they run very fast, and it gave a good effort. Absolutely I would have this writing small sub-sections of code or looking up support boilerplate, or as a support model that can run locally checking code and other tasks.
- This is a really good model in it's weight class. Given the right MCP tool like these ones it becomes a small powerhouse. It had no issues using the Javascript end-point to compile and test its work.
