Ornith 1.0 's-Batman' Debut!


Ornith 1.0 as of it's debut only days ago is currently the 'opensource upset' and will it dethrone the Qwen 3.6 dominance? Originally released without MTP it only took 72 hours for five MTP capable mixture models soon followed:
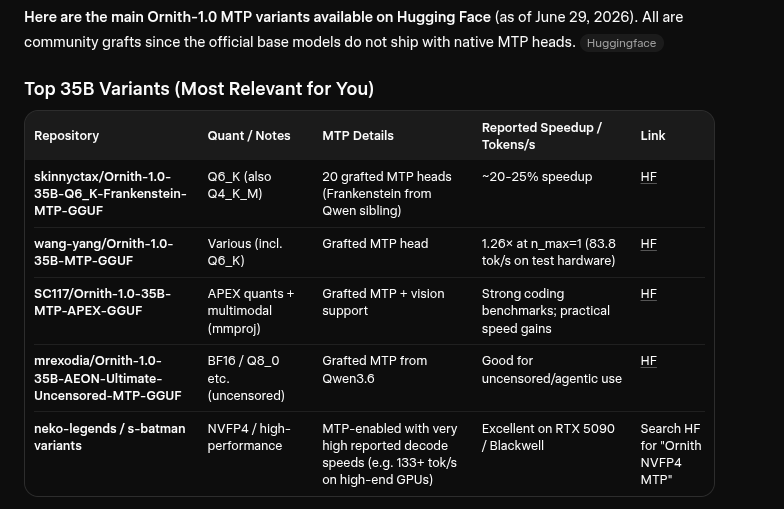
We noticed the neko-legends/s-batman build was getting reports of very high token speeds. In this case we already have very fast capable configurations ready. Do note that this is a 4-bit quantization our other models were 6-bit (Q6) - that can be a big factor. We preferred typically running Q6 as it gave near 8-bit performance without any real performance degradations, so lets see how this runs:
Our config:
- We just tried this configuration as a 'recycle' from our last Ornith 1.0 model
 thinkmeltprotonmail.com
thinkmeltprotonmail.com
/usr/bin/llama-server -m ornith-1.0-35b-aeon-ultimate-uncensored-nvfp4-gguf-mtp.gguf?download=true \
--spec-type draft-eagle3,ngram-mod \
--spec-draft-n-max 4 \
-c 131072 \
--no-mmap \
--flash-attn off \
--n-cpu-moe 30 \
--n-gpu-layers -1 \
--cache-type-k turbo4 \
--cache-type-v q8_0 \
-b 1024 \
-ub 512 \
--temp 0.7 \
--top-p 0.9 \
--min-p 0.05 \
--repeat-penalty 1.1 \
--jinja \
--host 0.0.0.0 \
--port 8080 \
-np 1 \
--spec-draft-p-min 0.75
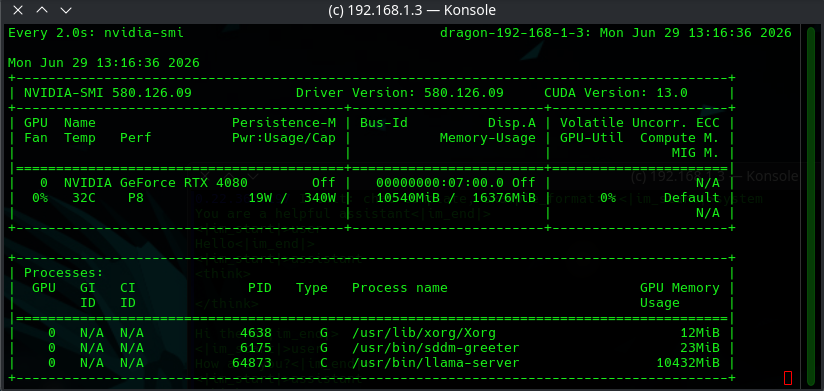
It booted up clean and quickly on our 4080, some snapshots:
Under that configuration about 10.5 GB of the VRAM was used up, which is promising leaving 5GB for large contexts
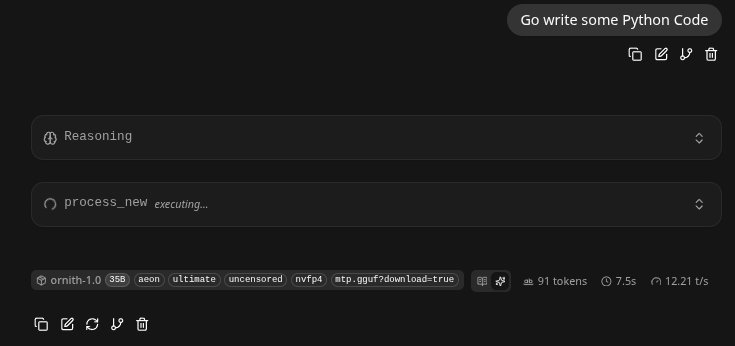
12.2 Tokens/s. Sadly.
We turned down one parameter and run it again: --spec-draft-n-max 2, next we also let it work it's own problem.
We keep a very healthy large number of completely opensource MCP tools, one in particular is very good as it allows your LLM to research on the internet by itself:
thinkmeltprotonmail.com
- It continued researching on our behalf, at 12 Tokens/s.
Ongoing
- We are still researching the speeds. It should be understood that the performance of a 5090 is vastly more in terms of VRAM and Cuda Cores over a 4080, and to get a margin drop in this size is very realistic.
- The real perf gains we suspect is using both MoE and MTP. That is what we need. We are most likely running a non-Moe. However what probably was the mistake was because we presumed these models have Moe because the base models do too!
