Ornith MTP FrakenModel 1.0 (Try 01) w/MTP. Slower than it's Original?
We explore if MTP is hitting Ornith 1.0. We were not able to get significant breakthroughs - again configurations matter!


Update, within hours there are scratch 4, now 5 variants of Ornith, This is a test of the first one:
Ornith 1.0 (the original) released only days ago, has caused a real upset. Claiming significantly higher benchmarks as a 'fine-tuned' model derivative from it's predecessors of Qwen 3.5 and Gemma 4, it hit the Opensource ranks with 50/50 splits. Some were positive, others neutral, others didn't see benefits in their benchmarks. Qwen 3.6 had dominated the localspace for some now, and an upset was in the works. Some using the new Ornith 1.0 did see significantly better tool calling, others suggested it was a half-mung model. Overall if it's benchmarks were true it was a very significant leap forward irrespective if one felt it was 'Benchmaxxed'. You can decide for yourself, we have an entire setup guide as well.
 deepreinforce-ai
deepreinforce-aiIt only took literally hours for someone to modify it, add MTP (Multi-Token Protocol) support and to give it a 'franken-model' naming:

We immediately set out to pull it and see if we could break the 100T/s on our 4080 rig. Our run configuration after some mangling is sorta a bit of a franken-config in itself because we had to force off-load some of the tensors with our configuration cheat code:
--override-tensor "\.ffn_.*_exps\.weight=CPU" \
/usr/bin/llama-server -m ornith-1.0-35b-Q6_K-MTP-final.gguf \
--spec-type draft-mtp \
--spec-draft-n-max 4 \
-c 16384 \
-ngl 99 \
--flash-attn on \
--cache-type-k turbo2 \
--cache-type-v turbo2 \
--override-tensor "\.ffn_.*_exps\.weight=CPU" \
-b 1024 \
-ub 512 \
--temp 0.7 \
--top-p 0.9 \
--min-p 0.05 \
--repeat-penalty 1.1 \
--jinja \
--host 0.0.0.0 \
--port 8080 \
-np 1 \It fired up cleanly, without much fuss:
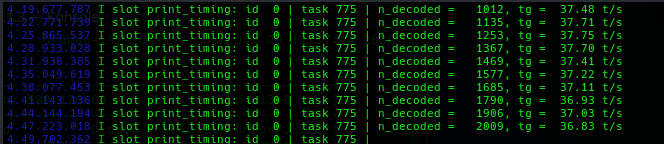
We were not completely really sold on this setup. MTP typically should give some 'slop' but in exchange you can have super-fluid fast token generations. We measured about 37-40 Token/s typically is the same as just running a straight Ornith 1.0 Moe?
We kept trying different configurations over and over, we also tried variants like this:
/usr/bin/llama-server -m ornith-1.0-35b-Q6_K-MTP-final.gguf \
--spec-type draft-mtp \
--spec-draft-n-max 2 \
-c 8192 \
-ngl 20 \
--flash-attn on \
--cache-type-k turbo3 \
--cache-type-v turbo3 \
-b 1024 \
-ub 512 \
--temp 0.7 \
--top-p 0.9 \
--min-p 0.05 \
--repeat-penalty 1.1 \
--jinja \
--host 0.0.0.0 \
--port 8080 \
-np 1 \
--spec-draft-p-min 0.75Final Try - Stacking --spec-type
We finally tried this and it did get pretty fluid, but at no point did we see 200% gains, or 150% gains, and or the 125% gains.
/usr/bin/llama-server -m ornith-1.0-35b-Q6_K-MTP-final.gguf \
--spec-type draft-eagle3,ngram-mod \
--spec-draft-n-max 4 \
-c 131072 \
--no-mmap \
--flash-attn on \
--n-cpu-moe 30 \
--n-gpu-layers -1 \
--cache-type-k turbo4 \
--cache-type-v q8_0 \
-b 1024 \
-ub 512 \
--temp 0.7 \
--top-p 0.9 \
--min-p 0.05 \
--repeat-penalty 1.1 \
--jinja \
--host 0.0.0.0 \
--port 8080 \
-np 1 \
--spec-draft-p-min 0.75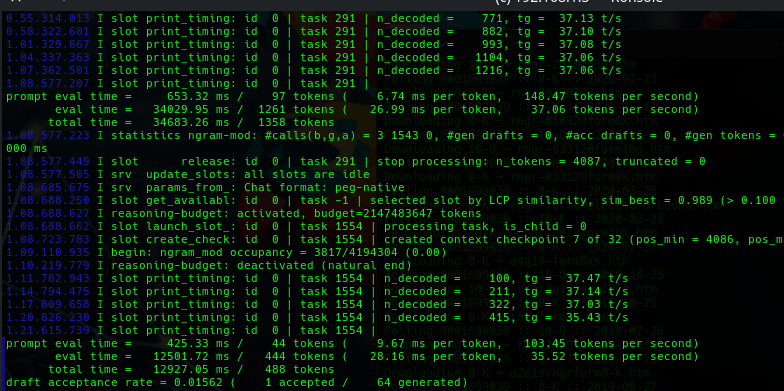
Conclusion
- We have tried offloading the model, but it has not showed us any significant improvements in speed over just running a standard Ornith 1.0 however there are still two more MTP models to go.
- We fully recognize that the huggingface site is not using llama.cpp but an alternate. We prefer it simply in that we can run very large contexts.
- One needs to understand that MTP can be a 'trade-off' you may be forced to run a smaller context - but you should see very fast token generation. We have not been able to thus far get there (we tried a bunch of varying context sizes).
- Configurations really matter. In one setup we were getting 17T/s adjusting it slightly and we were back cooking at 37 T/s. It really is worth your time to learn your LLM and the best configuration for your GPU! After 50 T/s if you can get your LLM there it becomes quite 'fluid' in that is is responsively flooding you with answers to keep you in flow.
Why?
- Imagine setting up a 37 Token/s workhorse that can run all night have big contexts, and then switching out your config and getting 100 Token/s fluid fast tool calling for fast local questions. It is the 'best-of-both-worlds' type setup. A simple way to explain it is like it's similar to a truck pulling hard in 2nd gear pulling a trailer load, and then moving quickly to take you for snacks!
