Iterating github. Letting Ornith Examine and Improve Entire Code Bases / git Repos.


The idea is simple. Most files now may fit into a single context. What if you take a leading model and have it review line-by-line entire code bases for you? What would be the result?
- Yes - I know claude and others are probably doing this but what about doing it from a houseLLM with a localGPU using the best model of the day Ornith 1.0
What is amazing is this can be extended for security testing, and or pentesting simply by modifying the prompt!
This is complex? Just learn a bit at a time, and work through the powerful StudentLLM. Don't underestimate it - when you finish it - it is actually one of the worlds most advanced localLLM configurations, and you can run 70B, 35B Moe, MTP, Turboquant, whatever you want!
 thinkmeltprotonmail.com
thinkmeltprotonmail.com
Yes you can use an excellent Hermes agent, in this case we boiler-plated some code to really learn the process.

Here is some boilerplate code, and we were wondering if it has become possible to have these kinds of iterative loops working on our behalf.
- The git repo is pulled, in our instance we want to learn from this excellent fork of llama.cpp
 TheTom
TheTom- A list of files are queried and they are prompt serially marched one by one through the reviewing Ornith.
- It produces an output fork that is automatically tested and compiled and this sub-loop sends back the errors if any until it passes.
- If a dramatic improvement is found the new repo -> base repo and the process is started.
Some code
import asyncio
import subprocess
import json
from pathlib import Path
from typing import List, Dict, Optional
import git # pip install GitPython
import aiohttp
import re
import time
class GitAlgorithmOptimizerAgent:
def __init__(self, server_url: str = "http://192.168.1.3:8080", work_dir: str = "/tmp/git_scan"):
self.server_url = server_url.rstrip("/")
self.work_dir = Path(work_dir)
self.work_dir.mkdir(parents=True, exist_ok=True)
self.max_build_attempts = 5
self.build_timeout = 300 # seconds
async def _query_llm(self, prompt: str, max_tokens: int = 2000) -> str:
payload = {
"prompt": prompt,
"n_predict": max_tokens,
"temperature": 0.7,
"top_p": 0.9,
}
async with aiohttp.ClientSession() as session:
async with session.post(f"{self.server_url}/completion", json=payload) as resp:
if resp.status != 200:
text = await resp.text()
raise Exception(f"LLM error: {resp.status} - {text}")
data = await resp.json()
return data.get("content", "")
async def clone_repo(self, repo_url: str, branch: str = "main") -> Path:
repo_name = repo_url.split("/")[-1].replace(".git", "")
local_path = self.work_dir / repo_name
if local_path.exists():
print(f"Using existing clone at {local_path}")
return local_path
print(f"Cloning {repo_url}...")
subprocess.run(["git", "clone", "--depth", "1", "-b", branch, repo_url, str(local_path)], check=True)
return local_path
def scan_source_files(self, repo_path: Path, max_size: int = 12000) -> List[Dict]:
"""Scan source files across multiple languages: Python, C, C++, CUDA."""
source_files = []
extensions = {
'.py': 'Python',
'.c': 'C',
'.cpp': 'C++',
'.h': 'C/C++ Header',
'.hpp': 'C++ Header',
'.cu': 'CUDA',
'.cuh': 'CUDA Header'
}
for ext, lang in extensions.items():
for file_path in repo_path.rglob(f"*{ext}"):
try:
with open(file_path, "r", encoding="utf-8") as f:
content = f.read()
relative_path = str(file_path.relative_to(repo_path))
source_files.append({
"path": relative_path,
"language": lang,
"content": content[:max_size],
"size": len(content)
})
except Exception as e:
print(f"Error reading {file_path}: {e}")
print(f"Scanned {len(source_files)} source files across Python, C, C++, and CUDA.")
return source_files
async def analyze_for_optimizations(self, file_info: Dict) -> Dict:
lang = file_info.get("language", "Unknown")
prompt = f"""You are an expert algorithm optimizer for {lang} code.
Analyze the following code for performance bottlenecks and suggest faster alternatives.
File: {file_info['path']}
Language: {lang}
Code:
{file_info['content']}
Focus on time complexity, data structures, memory usage, compiler optimizations, and language-specific best practices.
Respond with valid JSON only:
{{"suggestions": [{{"original_snippet": "...", "improved_snippet": "...", "reason": "..."}}], "overall_assessment": "brief summary"}}"""
try:
response = await self._query_llm(prompt, max_tokens=3000)
json_match = re.search(r'\{.*\}', response, re.DOTALL)
if json_match:
return json.loads(json_match.group(0))
return {"error": "No JSON found", "raw": response[:500]}
except Exception as e:
return {"error": str(e)}
def save_results_to_local_git_fork(self, repo_path: Path, results: List[Dict],
branch_name: str = "algorithm-optimizations"):
"""Commit analysis results and any code changes to a new branch."""
try:
repo = git.Repo(repo_path)
if branch_name in [b.name for b in repo.branches]:
repo.git.checkout(branch_name)
else:
repo.git.checkout("-b", branch_name)
report_path = repo_path / "optimization_report.json"
with open(report_path, "w", encoding="utf-8") as f:
json.dump(results, f, indent=2)
repo.index.add([str(report_path)])
repo.index.commit(f"Add algorithmic optimization analysis report (branch: {branch_name})")
print(f"Results committed to local branch '{branch_name}' in {repo_path}")
except Exception as e:
print(f"Git commit error: {e}")
def _run_build(self, repo_path: Path) -> tuple[bool, str]:
"""Attempt CMake build (llama.cpp fork)."""
build_dir = repo_path / "build"
build_dir.mkdir(exist_ok=True)
try:
cmake_cmd = [
"cmake", "-B", str(build_dir), "-S", str(repo_path),
"-DGGML_CUDA=ON",
"-DCMAKE_BUILD_TYPE=Release"
]
print("Running CMake configure...")
config_result = subprocess.run(cmake_cmd, cwd=repo_path, capture_output=True, text=True,
timeout=self.build_timeout)
if config_result.returncode != 0:
return False, f"CMake configure failed:\n{config_result.stderr}\n{config_result.stdout}"
print("Running build...")
build_cmd = ["cmake", "--build", str(build_dir), "-j", "8", "--config", "Release"]
build_result = subprocess.run(build_cmd, cwd=repo_path, capture_output=True, text=True,
timeout=self.build_timeout * 2)
if build_result.returncode == 0:
return True, build_result.stdout
else:
return False, f"Build failed:\n{build_result.stderr}\n{build_result.stdout}"
except subprocess.TimeoutExpired:
return False, "Build timed out."
except Exception as e:
return False, f"Build error: {str(e)}"
async def _fix_build_errors(self, repo_path: Path, build_error: str, max_fix_attempts: int = 3) -> bool:
"""Iteratively fix build errors using LLM."""
for attempt in range(1, max_fix_attempts + 1):
print(f"Build fix attempt {attempt}/{max_fix_attempts}...")
# Gather context from C/C++/CUDA files
key_files = []
for ext in ['.cpp', '.c', '.cu', '.h', '.hpp', '.cuh']:
for file_path in list(repo_path.rglob(f"*{ext}"))[:8]:
try:
with open(file_path, "r", encoding="utf-8") as f:
content = f.read()[:6000]
key_files.append({
"path": str(file_path.relative_to(repo_path)),
"content": content
})
except:
pass
prompt = f"""You are an expert C++/CUDA/CMake build fixer for a llama.cpp-based project.
The project failed to build with the following error:
{build_error[:8000]}
Key source file snippets:
{json.dumps(key_files, indent=2)}
Provide precise fixes. Respond with valid JSON only:
{{
"fixes": [
{{"file_path": "relative/path/to/file.cpp", "original_snippet": "...", "improved_snippet": "...", "explanation": "..."}},
...
],
"cmake_changes": "any suggestions for CMakeLists.txt or flags",
"overall_plan": "brief summary"
}}"""
try:
response = await self._query_llm(prompt, max_tokens=3500)
json_match = re.search(r'\{.*\}', response, re.DOTALL)
if not json_match:
continue
fix_data = json.loads(json_match.group(0))
applied = False
for fix in fix_data.get("fixes", []):
file_path = repo_path / fix["file_path"]
if file_path.exists():
try:
with open(file_path, "r", encoding="utf-8") as f:
content = f.read()
updated = content.replace(fix["original_snippet"], fix["improved_snippet"])
with open(file_path, "w", encoding="utf-8") as f:
f.write(updated)
print(f"Applied fix to {fix['file_path']}")
applied = True
except Exception as e:
print(f"Failed to apply fix: {e}")
success, output = self._run_build(repo_path)
if success:
print("Build succeeded after fixes!")
return True
else:
build_error = output
time.sleep(2)
except Exception as e:
print(f"Fix attempt error: {e}")
print("Max fix attempts reached.")
return False
async def run_analysis(self, repo_url: str, max_files: int = 30, max_cycles: int = 3) -> None:
"""Main iterative optimization cycle supporting multiple languages."""
repo_path = await self.clone_repo(repo_url)
for cycle in range(1, max_cycles + 1):
print(f"\n=== Starting Optimization Cycle {cycle}/{max_cycles} ===")
files = self.scan_source_files(repo_path)
results = []
for file in files[:max_files]:
print(f"Analyzing {file['path']} ({file['language']})...")
analysis = await self.analyze_for_optimizations(file)
results.append({"file": file["path"], "language": file["language"], "analysis": analysis})
branch_name = f"algorithm-optimizations-cycle-{cycle}"
self.save_results_to_local_git_fork(repo_path, results, branch_name)
print("Attempting build...")
success, build_output = self._run_build(repo_path)
if not success:
print("Initial build failed. Entering fix sub-cycle.")
build_fixed = await self._fix_build_errors(repo_path, build_output)
if not build_fixed:
print("Failed to fix build. Stopping this cycle.")
break
else:
print("Build succeeded.")
print(f"Cycle {cycle} completed.")
print("\nAll optimization cycles finished.")
# Usage
async def main():
agent = GitAlgorithmOptimizerAgent(server_url="http://192.168.1.3:8080")
await agent.run_analysis("https://github.com/TheTom/turboquant_plus", max_cycles=30)
print("Full iterative process complete.")
if __name__ == "__main__":
asyncio.run(main())Our specs:
- 4080 16GB VRAM / Ryzen 9 3900 w/128 GB Ram, Our run configuration is Ornith 1.0 with this setup:
thinkmeltprotonmail.com
- Outside that we simply let it work.
- The Moe + 4080 was kept very busy:
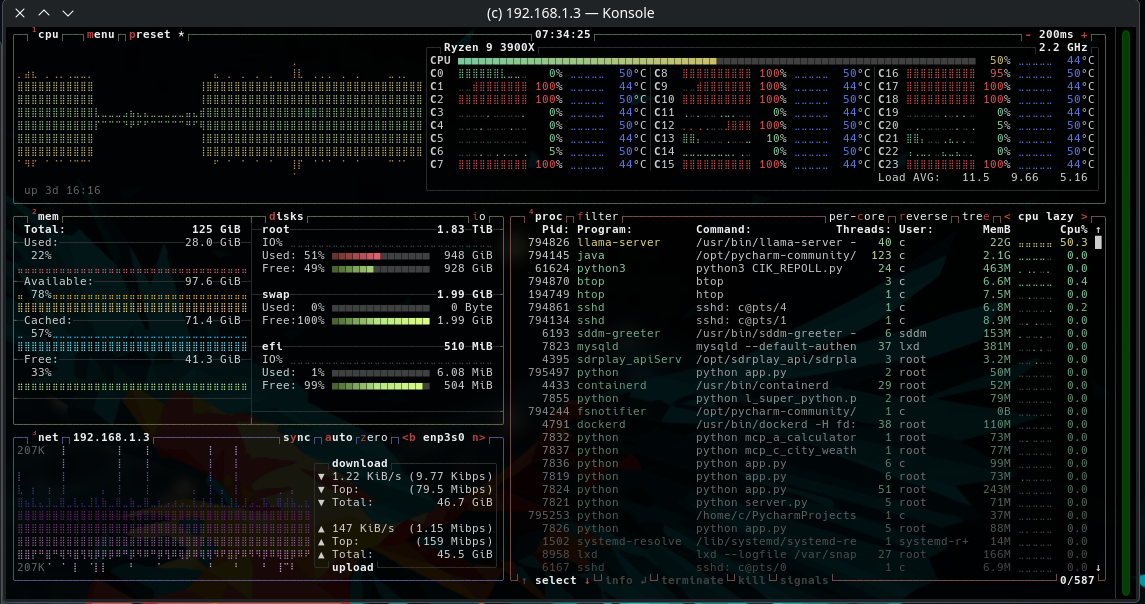
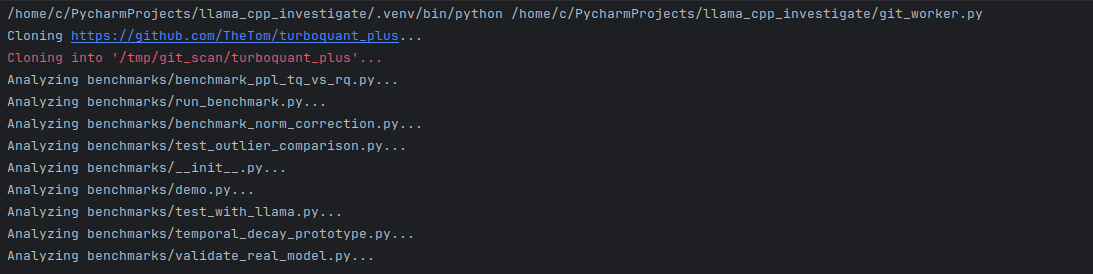
It looked to take about a minute to review each file:
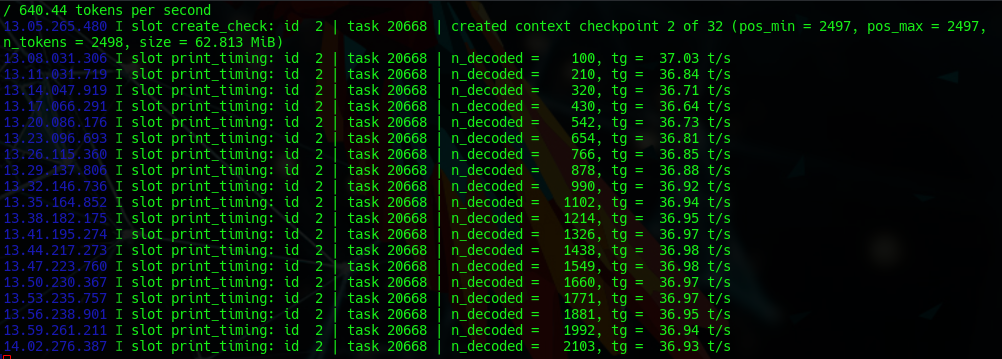
Ingest was solid we came in at 640 Tokens/s and our generation was a solid 36T/s consistent across tasks
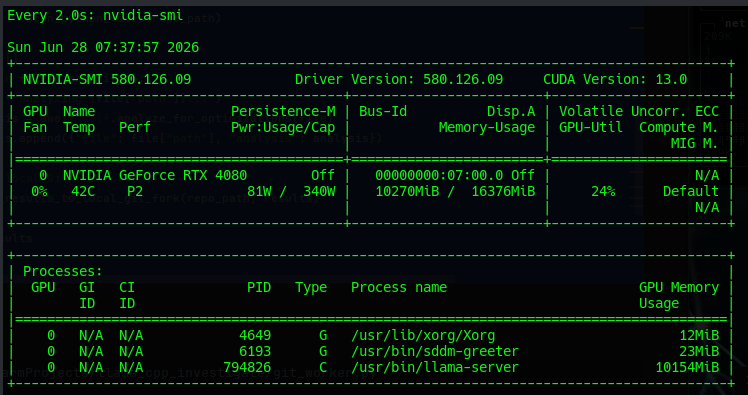
As you can see here we are actually wasting resources.. We are only using about 10 GB of our card no matter what file we look at - there may be very large files that come so we will not touch it for now
Finished - Not at all.
- We still need to add some feed-back compilation loops and speed testing of the builds. That needs all the setups and configurations plus the cmake. However the seed is started.
- From this point it can be built and added upon. If we make significant improvements we will post it here!
Update - Adding a Compilationn and Repair Sub-Fork
- We are part of an iterative cycle. We see things that need fixing, we are really an 'agent' that prompts the LLM to do much boilerplating work.
- Millions and millions of researchers iterating through things accelerating their research and development.
- Results go logarithmic everywhere there is a large distributive bell-curve.
Multiple Path Iteration
- This modification of the code will create a different git every time it runs.
- Overwriting sequential iterations may have the algorithms passing by a 'sweet-spot'
- Please up the token limit - the LLM writing this things you can do it in 3500 tokens/file completely not realistic - set it to your GPU resources.
import asyncio
import subprocess
import json
from pathlib import Path
from typing import List, Dict
import git # pip install GitPython
import aiohttp
import re
import time
import shutil
class GitAlgorithmOptimizerAgent:
def __init__(self, server_url: str = "http://192.168.1.3:8080", work_dir: str = "/tmp/git_scan"):
self.server_url = server_url.rstrip("/")
self.work_dir = Path(work_dir)
self.work_dir.mkdir(parents=True, exist_ok=True)
self.max_build_attempts = 5
self.build_timeout = 300 # seconds
async def _query_llm(self, prompt: str, max_tokens: int = 2000) -> str:
payload = {
"prompt": prompt,
"n_predict": max_tokens,
"temperature": 0.7,
"top_p": 0.9,
}
async with aiohttp.ClientSession() as session:
async with session.post(f"{self.server_url}/completion", json=payload) as resp:
if resp.status != 200:
text = await resp.text()
raise Exception(f"LLM error: {resp.status} - {text}")
data = await resp.json()
return data.get("content", "")
async def create_independent_fork(self, base_repo_path: Path, cycle: int) -> Path:
"""Create a fresh independent fork (copy) for this iteration to enable multi-dimensional exploration."""
fork_name = f"turboquant_plus_fork_cycle_{cycle}_{int(time.time())}"
fork_path = self.work_dir / fork_name
print(f"Creating independent fork for cycle {cycle}: {fork_path}")
if fork_path.exists():
shutil.rmtree(fork_path)
shutil.copytree(base_repo_path, fork_path, dirs_exist_ok=True)
return fork_path
def scan_source_files(self, repo_path: Path, max_size: int = 12000) -> List[Dict]:
"""Scan source files across Python, C, C++, CUDA."""
source_files = []
extensions = {
'.py': 'Python',
'.c': 'C',
'.cpp': 'C++',
'.h': 'C/C++ Header',
'.hpp': 'C++ Header',
'.cu': 'CUDA',
'.cuh': 'CUDA Header'
}
for ext, lang in extensions.items():
for file_path in repo_path.rglob(f"*{ext}"):
try:
with open(file_path, "r", encoding="utf-8") as f:
content = f.read()
relative_path = str(file_path.relative_to(repo_path))
source_files.append({
"path": relative_path,
"language": lang,
"content": content[:max_size],
"size": len(content)
})
except Exception as e:
print(f"Error reading {file_path}: {e}")
print(f"Scanned {len(source_files)} source files.")
return source_files
async def analyze_for_optimizations(self, file_info: Dict) -> Dict:
lang = file_info.get("language", "Unknown")
prompt = f"""You are an expert algorithm optimizer for {lang} code.
Analyze the following code for performance bottlenecks and suggest faster alternatives.
File: {file_info['path']}
Language: {lang}
Code:
{file_info['content']}
Focus on time complexity, data structures, memory usage, compiler optimizations, and language-specific best practices.
Respond with valid JSON only:
{{"suggestions": [{{"original_snippet": "...", "improved_snippet": "...", "reason": "..."}}], "overall_assessment": "brief summary"}}"""
try:
response = await self._query_llm(prompt, max_tokens=3000)
json_match = re.search(r'\{.*\}', response, re.DOTALL)
if json_match:
return json.loads(json_match.group(0))
return {"error": "No JSON found", "raw": response[:500]}
except Exception as e:
return {"error": str(e)}
def save_results_to_local_git_fork(self, repo_path: Path, results: List[Dict], branch_name: str):
"""Commit results to the independent fork branch."""
try:
repo = git.Repo(repo_path)
if branch_name in [b.name for b in repo.branches]:
repo.git.checkout(branch_name)
else:
repo.git.checkout("-b", branch_name)
report_path = repo_path / "optimization_report.json"
with open(report_path, "w", encoding="utf-8") as f:
json.dump(results, f, indent=2)
repo.index.add([str(report_path)])
repo.index.commit(f"Add algorithmic optimization analysis report (cycle branch: {branch_name})")
print(f"Results committed to branch '{branch_name}' in independent fork {repo_path.name}")
except Exception as e:
print(f"Git commit error: {e}")
def _run_build(self, repo_path: Path) -> tuple[bool, str]:
"""CMake build for the independent fork."""
build_dir = repo_path / "build"
build_dir.mkdir(exist_ok=True)
try:
cmake_cmd = [
"cmake", "-B", str(build_dir), "-S", str(repo_path),
"-DGGML_CUDA=ON",
"-DCMAKE_BUILD_TYPE=Release"
]
print(f"Configuring build in {repo_path.name}...")
config_result = subprocess.run(cmake_cmd, cwd=repo_path, capture_output=True, text=True, timeout=self.build_timeout)
if config_result.returncode != 0:
return False, f"CMake configure failed:\n{config_result.stderr}\n{config_result.stdout}"
print(f"Building {repo_path.name}...")
build_cmd = ["cmake", "--build", str(build_dir), "-j", "8", "--config", "Release"]
build_result = subprocess.run(build_cmd, cwd=repo_path, capture_output=True, text=True, timeout=self.build_timeout * 2)
if build_result.returncode == 0:
return True, build_result.stdout
else:
return False, f"Build failed:\n{build_result.stderr}\n{build_result.stdout}"
except subprocess.TimeoutExpired:
return False, "Build timed out."
except Exception as e:
return False, f"Build error: {str(e)}"
async def _fix_build_errors(self, repo_path: Path, build_error: str, max_fix_attempts: int = 3) -> bool:
"""LLM-driven iterative build fixing on this independent fork."""
for attempt in range(1, max_fix_attempts + 1):
print(f"Build fix attempt {attempt}/{max_fix_attempts} on {repo_path.name}...")
key_files = []
for ext in ['.cpp', '.c', '.cu', '.h', '.hpp', '.cuh']:
for file_path in list(repo_path.rglob(f"*{ext}"))[:8]:
try:
with open(file_path, "r", encoding="utf-8") as f:
content = f.read()[:6000]
key_files.append({"path": str(file_path.relative_to(repo_path)), "content": content})
except:
pass
prompt = f"""You are an expert C++/CUDA/CMake build fixer.
Project: {repo_path.name}
Build error:
{build_error[:8000]}
Key files:
{json.dumps(key_files, indent=2)}
Respond with valid JSON only containing fixes."""
# (Full prompt structure as in previous version - abbreviated here for brevity)
try:
response = await self._query_llm(prompt, max_tokens=3500)
json_match = re.search(r'\{.*\}', response, re.DOTALL)
if not json_match:
continue
fix_data = json.loads(json_match.group(0))
for fix in fix_data.get("fixes", []):
file_path = repo_path / fix.get("file_path", "")
if file_path.exists():
try:
with open(file_path, "r", encoding="utf-8") as f:
content = f.read()
updated = content.replace(fix["original_snippet"], fix["improved_snippet"])
with open(file_path, "w", encoding="utf-8") as f:
f.write(updated)
print(f"Applied fix to {fix.get('file_path')}")
except Exception as e:
print(f"Patch error: {e}")
success, output = self._run_build(repo_path)
if success:
print(f"✅ Build succeeded on independent fork {repo_path.name}!")
return True
build_error = output
except Exception as e:
print(f"Fix error: {e}")
print(f"❌ Max fixes reached for {repo_path.name}")
return False
async def run_analysis(self, repo_url: str, max_files: int = 30, max_cycles: int = 3) -> None:
"""Multi-dimensional independent fork iteration."""
base_repo_path = await self.clone_repo(repo_url)
for cycle in range(1, max_cycles + 1):
print(f"\n=== Starting Independent Fork Cycle {cycle}/{max_cycles} ===")
# Create fresh independent fork for this path
fork_path = await self.create_independent_fork(base_repo_path, cycle)
files = self.scan_source_files(fork_path)
results = []
for file in files[:max_files]:
print(f"Analyzing {file['path']} ({file['language']}) in fork cycle {cycle}...")
analysis = await self.analyze_for_optimizations(file)
results.append({
"file": file["path"],
"language": file["language"],
"analysis": analysis
})
branch_name = f"optimizations-cycle-{cycle}"
self.save_results_to_local_git_fork(fork_path, results, branch_name)
# Build + Fix sub-cycle on this independent fork
print(f"Building independent fork for cycle {cycle}...")
success, build_output = self._run_build(fork_path)
if not success:
print("Initial build failed - entering fix sub-cycle.")
build_fixed = await self._fix_build_errors(fork_path, build_output)
if not build_fixed:
print(f"Failed to produce working fork for cycle {cycle}. Continuing to next path.")
continue
print(f"✅ Working independent fork created for cycle {cycle}: {fork_path}")
print("\nAll multi-dimensional optimization cycles completed.")
# Usage
async def main():
agent = GitAlgorithmOptimizerAgent(server_url="http://192.168.1.3:8080")
await agent.run_analysis("https://github.com/TheTom/turboquant_plus", max_cycles=3)
print("Multi-path iterative process complete.")
if __name__ == "__main__":
asyncio.run(main())