Qwen3.6 Drops!- A HouseLLM Production Level Coding Perspective? One-Shot GoAccess
We Test Qwen3.6 if it is up to your home production standards.


Huggingface and most sites were excited to get the latest Qwen3.6 - scoring unbelievably high for a 35B. People were clearly questioning if this model was tuned to rig the benchmarks, but nonetheless its performance out of the gate was looking very impressive:
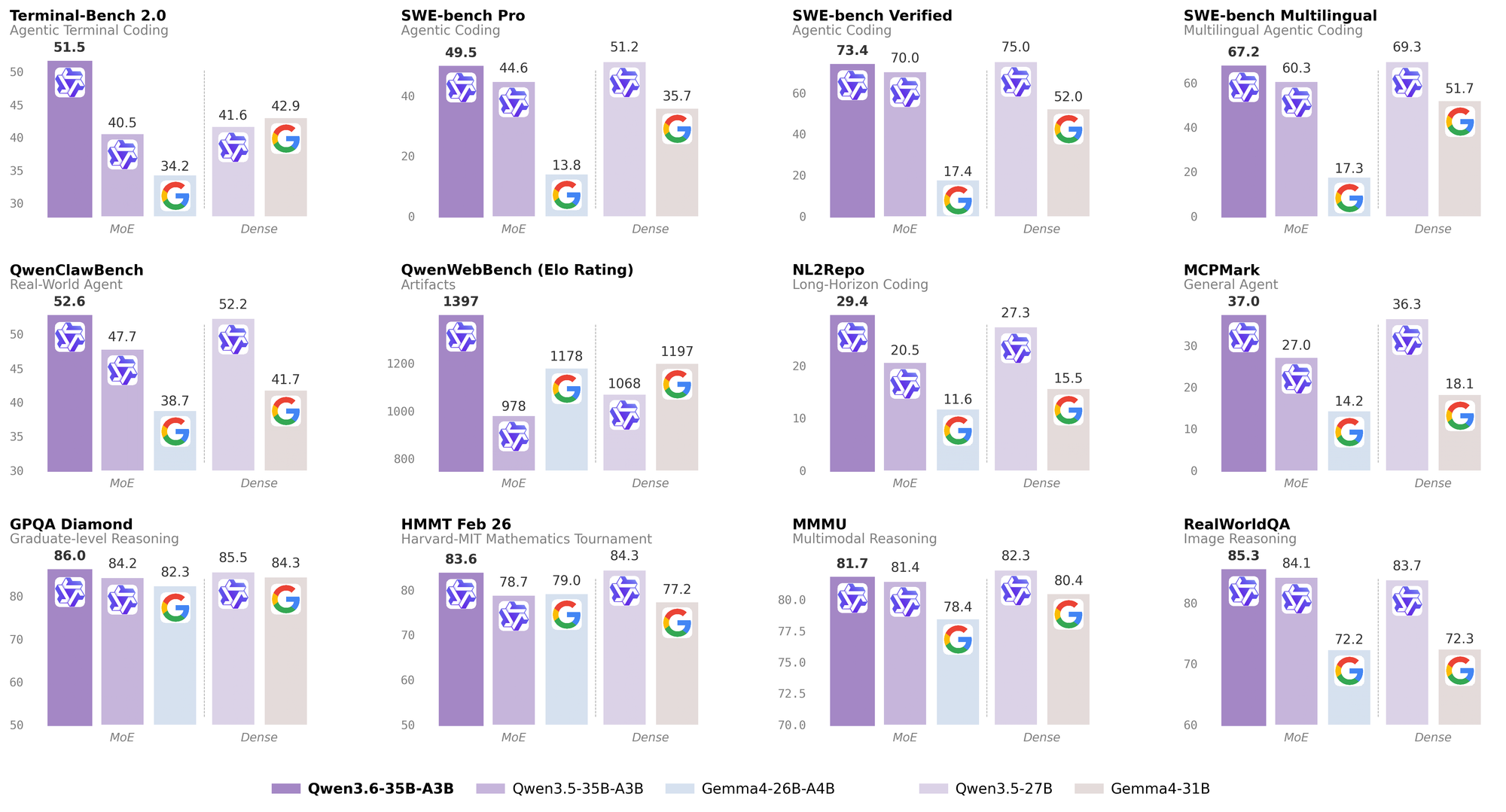
Scoring in at 51.5 in Terminal-Bench 2.0 looks very well suited as a strong contender for managing your server instances, scoring handsomely above Gemma and Google which is in our interests.
We gave it the following prompt, if it is actually that good to see if it could one-shot GoAccess a Logging service. We gave it all the Agentic tools (Context Manager, Python, Web Lookup etc, asked it to benchmark it's work and then finish with a Code Drop.)
Here are the results. Our System Specifications is modest.
- Ryzen 9 3900 12-core/24 Thread. (128 GB RAM)
- Nivida 4080ti w/16 GB.
Our Run Configuration is Using TensorBalance / TurboQuant Forked Llama.cpp if you want to build your own (here). If you want to build the agentic tools to run inside your own docker container - check out our (downloads)
- We were running the 6-bit GGUF slight off a full 8 (Q6)
Our Run Config
/usr/bin/llama-server --jinja \
-m /home/c/models/Qwen3.6-35B-A3B-UD-Q6_K_XL.gguf \
--host 192.168.1.3 \
--n-gpu-layers 999 \
--flash-attn on \
--override-tensor "\.ffn_.*_exps\.weight=CPU" \
--cache-type-k turbo3 \
--cache-type-v turbo3 \
-c 512000 \
--temp 0.7Our Prompt
Go find GoAccess Traffic Analyzer, Analyze it into a project using the project manager into several tasks to replicate it. Every time you create a task or job inside the project manager save it. Work on each task and test them in python. When you are done save the project manager and send a code dropOur Result
- 63 Reasoning Cycles intermixed with approximately 30 python code cycles.
- The LLM make little look ups to the Internet working mostly locally however it did go find it (we did not specify where to even look for it.)
Performance
- It averaged 22.9 Tokens/s over a Context Window of 62,770 Tokens
- It worked by itself for about 45 Minutes.

- It did not complete the Code Drop - it delivered after a second ask. We use a custom Context Manager so that it can retrieve its work and or break it up - and if you want a full guide for adding it to your llm its opensource. (here)
Code Drop
- Came out very nicely, producing a project structure of 6 folders.
- The code a 31 KB export, html came in at 21 KB of production.
- Multiple Class Performance
The model clearly delineated the task into groups and performed well, writing clean code without hinting. Again it ran dozens of cycles to clean it's own code an example Class it built for the URLAnalyzer.
from collections import Counter, defaultdict
from typing import Dict, List, Tuple
from log_parser import LogEntry
from urllib.parse import urlparse
class URLAnalyzer:
"""Analyzes URLs and paths from parsed log entries."""
def __init__(self, entries: List[LogEntry]):
self.entries = entries
self.path_counter = Counter()
self.path_bytes: Dict[str, int] = defaultdict(int)
self.path_status: Dict[str, Counter] = defaultdict(Counter)
self.method_counter = Counter()
self.extension_counter = Counter()
self.directory_counter = Counter()
self._analyze()
def _analyze(self):
"""Perform URL analysis."""
for entry in self.entries:
self.path_counter[entry.path] += 1
self.path_bytes[entry.path] += entry.response_size
self.path_status[entry.path][entry.status_code] += 1
self.method_counter[entry.method] += 1
# Extract file extension
parsed = urlparse(entry.path)
path = parsed.path
if '.' in path:
ext = path.split('.')[-1].split('?')[0]
self.extension_counter[ext] += 1
# Extract directory
if path != '/':
parts = path.strip('/').split('/')
directory = '/' + '/'.join(parts[:-1]) if len(parts) > 1 else '/'
self.directory_counter[directory] += 1
def get_top_paths(self, n: int = 10) -> List[Tuple[str, int]]:
"""Get top N most requested paths."""
return self.path_counter.most_common(n)
def get_top_bytes_paths(self, n: int = 10) -> List[Tuple[str, int]]:
"""Get top N paths by bytes transferred."""
return sorted(
[(path, bytes) for path, bytes in self.path_bytes.items()],
key=lambda x: x[1],
reverse=True
)[:n]
def get_path_details(self, path: str) -> Dict:
"""Get detailed statistics for a specific path."""
if path not in self.path_counter:
return {}
return {
'path': path,
'total_requests': self.path_counter[path],
'total_bytes': self.path_bytes[path],
'status_codes': dict(self.path_status[path]),
'avg_response_size': self.path_bytes[path] / self.path_counter[path]
}
def get_extension_distribution(self) -> Dict[str, int]:
"""Get distribution of file extensions."""
return dict(self.extension_counter.most_common())
def get_directory_distribution(self, n: int = 10) -> Dict[str, int]:
"""Get distribution of directories."""
return dict(self.directory_counter.most_common(n))
def get_method_distribution(self) -> Dict[str, int]:
"""Get distribution of HTTP methods."""
return dict(self.method_counter.most_common())
def get_static_vs_dynamic(self) -> Dict[str, int]:
"""Categorize paths as static or dynamic."""
static_extensions = {'html', 'css', 'js', 'png', 'jpg', 'jpeg', 'gif', 'svg', 'ico', 'pdf', 'txt'}
static_count = 0
dynamic_count = 0
for entry in self.entries:
parsed = urlparse(entry.path)
path = parsed.path
if '.' in path:
ext = path.split('.')[-1].split('?')[0]
if ext.lower() in static_extensions:
static_count += 1
else:
dynamic_count += 1
else:
dynamic_count += 1
return {
'Static': static_count,
'Dynamic': dynamic_count
}
def get_api_endpoints(self) -> List[Tuple[str, int]]:
"""Identify API endpoints (paths starting with /api/)."""
api_paths = Counter()
for entry in self.entries:
if entry.path.startswith('/api/'):
api_paths[entry.path] += 1
return api_paths.most_common()
def get_404_paths(self) -> List[Tuple[str, int]]:
"""Get paths that returned 404 errors."""
not_found = []
for path, statuses in self.path_status.items():
if statuses.get(404, 0) > 0:
not_found.append((path, statuses[404]))
return sorted(not_found, key=lambda x: x[1], reverse=True)
def generate_report(self) -> str:
"""Generate a text report of URL analysis."""
report = []
report.append("=" * 70)
report.append("URL ANALYSIS REPORT")
report.append("=" * 70)
# Top paths
report.append("\n--- Top 20 Requested Paths ---")
for path, count in self.get_top_paths(20):
report.append(f" {path:40s} {count:6d} requests")
# Top bytes
report.append("\n--- Top 10 Paths by Bytes ---")
for path, bytes in self.get_top_bytes_paths(10):
report.append(f" {path:40s} {bytes:>10,} bytes")
# Method distribution
report.append("\n--- HTTP Method Distribution ---")
methods = self.get_method_distribution()
total = sum(methods.values())
for method, count in methods.items():
pct = (count / total * 100) if total > 0 else 0
report.append(f" {method:10s}: {count:6d} ({pct:5.1f}%)")
# Extension distribution
report.append("\n--- File Extension Distribution ---")
extensions = self.get_extension_distribution()
for ext, count in extensions.items():
report.append(f" .{ext:10s}: {count:6d}")
# Static vs Dynamic
report.append("\n--- Static vs Dynamic Content ---")
static_dynamic = self.get_static_vs_dynamic()
for content_type, count in static_dynamic.items():
report.append(f" {content_type:10s}: {count:6d}")
# API endpoints
report.append("\n--- API Endpoints ---")
api_endpoints = self.get_api_endpoints()
for path, count in api_endpoints:
report.append(f" {path:40s} {count:6d} requests")
# 404 paths
report.append("\n--- 404 Not Found Paths ---")
not_found = self.get_404_paths()
for path, count in not_found[:10]:
report.append(f" {path:40s} {count:6d} errors")
return '\n'.join(report)Conclusion
- We are very impressed. We did not feel the need for this model to get a 'SOTA assist'
- This was a poorly defined prompt that didn't specify how to replicate GoAccess where most production projects would be managing their LLM tightly.
- The conclusion is absolute in our opinion you can use these LLMs as a powerful assisting tool for basic building needs.
- Speed is respectable and that's the big +, We are really running on minimal equipment for the LLM world, just a stock 4080 GPU with the tensors layers split between that and the RAM
Save your Context and Come Back
This process manager is very powerful in that your LLM can now save it's work and spread it across many contexts.
 thinkmeltprotonmail.com
thinkmeltprotonmail.com
Get your LLM coding all Night! LLMQP
This LLM will enable you to queue multiple prompts which will execute one after another.
thinkmeltprotonmail.com
