The Hunt for the Perfect 8b - Try -01 Gemma4-12 v2 Inspection.. Can we get a powerhouse LLM inside a 8GB.. You decide.
We review a mucle-tuned powerhouse of a homeLLM. The rocking 8GB Gemma4-v2 tuned for coders and agentic tasks.


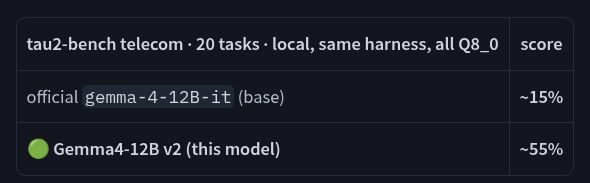
We saw this post and it piqued our interest. A production-assistant level LLM that claimed it finally worked really well on a 8GB VRAM cards aka 3060ti? This would make mass-adoption reachable. Now a $200 GPU could be working for you, if it can do decent tool-calling and support kv-cache (Turboquant) it could be the next game-changer in the LLM revolutions!

- Benchmarked 360% higher than standard Gemma4 (claimed)
- Tuned for agentic / coding tasks.
- Runs on a 3060ti..
Pre-Install Supports
If you need a full walk-through guide to installing one of the world's most advanced setups in llama.cpp this guide will carefully walk you through the whole process.
- Learn how to build and manager your own LLM and all the drivers and GPU supports.
 thinkmeltprotonmail.com
thinkmeltprotonmail.com
Some direct model links:
| File / Quant | Size | Recommended For | Direct wget Command |
|---|---|---|---|
| Q3_K_M (Main) | ~5.7 GB | Great for 8 GB VRAM | wget https://huggingface.co/yuxinlu1/gemma-4-12B-agentic-fable5-composer2.5-v2-3.5x-tau2-GGUF/resolve/main/gemma4-v2-Q3_K_M.gguf -O /home/c/models/gemma4-v2-Q3_K_M.gguf |
| Q4_K_M (Main) | ~6.87 GB | Recommended Sweet Spot | wget https://huggingface.co/yuxinlu1/gemma-4-12B-agentic-fable5-composer2.5-v2-3.5x-tau2-GGUF/resolve/main/gemma4-v2-Q4_K_M.gguf -O /home/c/models/gemma4-v2-Q4_K_M.gguf |
| Q6_K (Main) | ~9.11 GB | Near-lossless quality | wget https://huggingface.co/yuxinlu1/gemma-4-12B-agentic-fable5-composer2.5-v2-3.5x-tau2-GGUF/resolve/main/gemma4-v2-Q6_K.gguf -O /home/c/models/gemma4-v2-Q6_K.gguf |
| Q8_0 (Main) | ~11.8 GB | Full quality (higher VRAM) | wget https://huggingface.co/yuxinlu1/gemma-4-12B-agentic-fable5-composer2.5-v2-3.5x-tau2-GGUF/resolve/main/gemma4-v2-Q8_0.gguf -O /home/c/models/gemma4-v2-Q8_0.gguf |
| Q8_0 (MTP Draft) | 465 MB | Recommended for MTP Best balance |
wget https://huggingface.co/yuxinlu1/gemma-4-12B-agentic-fable5-composer2.5-v2-3.5x-tau2-GGUF/resolve/main/MTP/gemma-4-12B-it-MTP-Q8_0.gguf -O /home/c/models/MTP/gemma-4-12B-it-MTP-Q8_0.gguf |
| F16 (MTP Draft) | 862 MB | Highest precision | wget https://huggingface.co/yuxinlu1/gemma-4-12B-agentic-fable5-composer2.5-v2-3.5x-tau2-GGUF/resolve/main/MTP/gemma-4-12B-it-MTP-F16.gguf -O /home/c/models/MTP/gemma-4-12B-it-MTP-F16.gguf |
| BF16 (MTP Draft) | 862 MB | Good precision + compatibility | wget https://huggingface.co/yuxinlu1/gemma-4-12B-agentic-fable5-composer2.5-v2-3.5x-tau2-GGUF/resolve/main/MTP/gemma-4-12B-it-MTP-BF16.gguf -O /home/c/models/MTP/gemma-4-12B-it-MTP-BF16.gguf |
3060ti Configurations - 64K Maximum Context Q3_K_M (3-bit Quantization)
- We tested this on a 4080, but screenshot it to see how it actually fit..
- It rolled into a repetitive loop so we added
--repeat-penalty 1.12
/usr/bin/llama-server \
--jinja \
-m /home/c/models/gemma4-v2-Q3_K_M.gguf \
--ctx-size 65536 \
--n-gpu-layers 99 \
--cache-type-k turbo3 \
--cache-type-v turbo3 \
--no-mmap \
-fa on \
--parallel 1 \
--batch-size 512 \
--ubatch-size 512 \
--threads 12 \
--repeat-penalty 1.12 \
--temp 1.0 --top-p 0.95 --top-k 64 \
--host 0.0.0.0 --port 8080Results - About 7196 MB on load / BLASTING at 71 Tokens/s out (on a 4080)
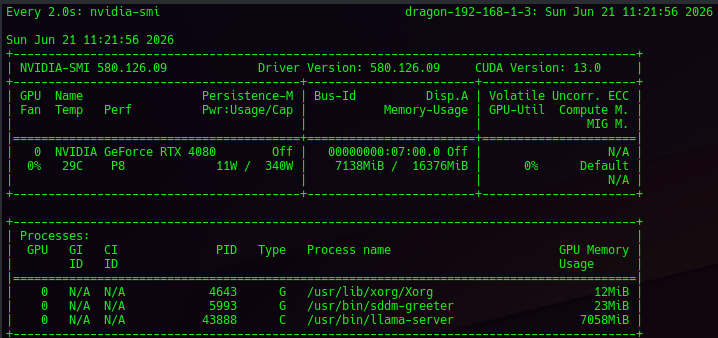
Note - tool calling did not work, or was really problematic. We really tried a bunch of stuff. Summary great for local assistantant lookups. It's very good.
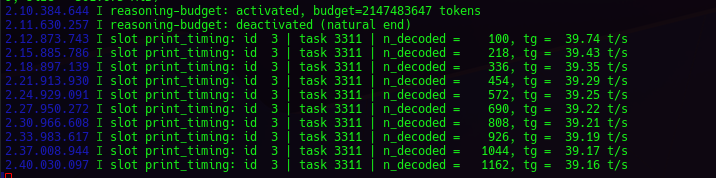
Standard Configuration - Gemma4-v2-Q8_0 without MTP (40 Token's/s) - Not Bad!
- We recycled the following configuration, tuned it up a bit, and since this is a smaller model it left lots of room
- It worked very well with
turbo3 \ turbo4quantization and integrated cleanly withmtp(Multiple Token Prediction) - It presented some breaks and errors. So it's not quite there.
/usr/bin/llama-server --jinja \
-m /home/c/models/gemma4-v2-Q8_0.gguf \
--ctx-size 16384 \
--n-gpu-layers 99 \
--no-mmap -fa on \
--jinja \
--temp 1.0 --top-p 0.95 --top-k 64 \
--host 0.0.0.0 --port 8080 \
--cache-type-k turbo3 \
--cache-type-v turbo4
--context-shift \
--spec-type draft-mtp \
--spect-draft-n-max 4
- It ran at about 40 T/s, but was the tool calling fixed??
We are using powerful agentic tools that are completely opensource - check them out!
Conclusion.
This is a very good local llm, but we tried extensively to get any tooling calls to work. It either seemed to hallucinate a lot - or did not make the tooling calls at all. With no tooling enabled at all it seemed to work quite well. However with no tools given to it - it would produce very good quality assistant suggestions very quickly - at about 70 tokens/s which is fluid and capable for most people's needs!
We are still looking!
