Qwen3-Coder-Next-UD-Q4-K_XL.gguf on a Ryzen 9/4080ti. Run a 48GB SOTA Tensor-Balanced on a $2K set of House Parts.
We field test a Qwen3-Coder-Next-UD-Q4_K_XL.gguf


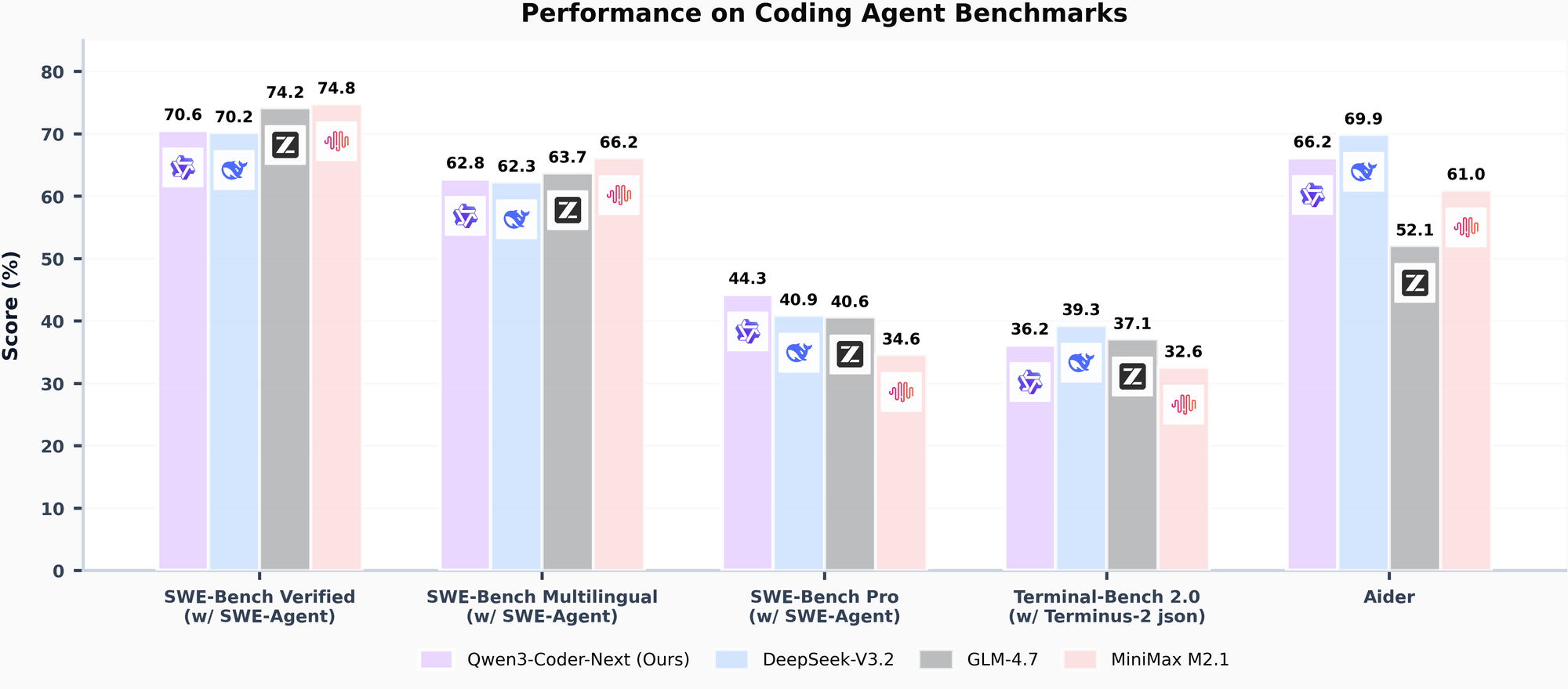
The Qwen3-Coder fork released by Unsloth just benchmarked in performance proximity with 235B sized models and is looking to have SOTA level performance for April 2026! Here is the low-down. At the time of this writing the model was so new that HuggingFace.com did not have the auto-full benchmarks out for it, but we were able to find them. Again incredible accolades to Unsloth AI, who just keep making incredible models!

The best part is you can run frontier models such as this Qwen3-Coder that are efficient, fast and reliable on under $2000 in house computer parts! Here is the setup:
/usr/bin/llama-server --jinja \
-m /home/c/models/Qwen3-Coder-Next-UD-Q4_K_XL.gguf \
--host 192.168.1.3 \
--n-gpu-layers 999 \
--flash-attn on \
--override-tensor "\.ffn_.*_exps\.weight=CPU" \
--cache-type-k turbo3 \
--cache-type-v turbo3 \
-c 262144 \
--temp 0.7
The key was right here, as the normal '--fit' actually fails on llama-cpp. what '--fit' does is the llama-server will then try to balance the model between the VRAM/CPU.. It cannot do it. However this actually worked!
--override-tensor "\.ffn_.*_exps\.weight=CPU" \This is telling the llama-cpp that heavy tensor models - load to the GPU, light layers keep on the CPU. This overcame the RAM/VRAM bottleneck plauging setups everywhere and people were spending $1000's to buy unified VRAM systems such as Mac Pros.
An Even Faster Configuration suggested by:
https://x.com/iam_shanmukhaWe were able to get up to 33 Tokens/s.
/usr/bin/llama-server --jinja \
-m /home/c/models/Qwen3.6-35B-A3B-UD-Q6_K_XL.gguf \
--host 192.168.1.3 \
--fit on \
--flash-attn on \
--spec-type ngram-mod \
--spec-ngram-size-n 24 \
--n-cpu-moe-draft 39 \
-t 14 \
--chat-template-kwargs '{"preserve_thinking":true}' \
--cache-type-k turbo3 \
--cache-type-v turbo4 \
-c 512000 \
--temp 0.7Turbo3 is an Advanced Quant Fork of Llama-cpp!
- Did you notice the non-normal --cache-type-k turbo3 / --cache-type-v turbo3? Those are the bleeding edge as of March 2026 TurboQuant forks.
- Full credit to 'The Tom' who graciously created one of the TurboQuant forks!
 TheTom
TheTomWould you Like a Detailed Guide for a Custom Compiled Llama-ccp TurboQuant Fork?
Here is a full self-compiling guide where a 112B used the same TensorBalance method to fit it, ran on a 16GB GPU, and ran the rest in RAM. Incredibly it was good - and usable with a respectable 12.8 Tokens/s!
 thinkmeltprotonmail.com
thinkmeltprotonmail.com
You will need the specialized llama-cpp fork TurboQuant w/ that override-tensor configuration. In our case wow. 25.48 t/s as we ask it to one-shot an Asteroids game that is 3x more complex.

Is it powerful? We asked it to one-shot an entire Asteroids game, then asked it to one-shot a game that was 3x more complex. It got a majority of it right.
If you would like a PILE of agentic tools OPENSOURCE from mysql, to docker, to context managers they are here:
thinkmeltprotonmail.com

