MTP / TurboQuant Forked Llama.cpp
We hot compile one of the first combo MTP / TurboQuant forks in the world!


When Turboquant hit it was BIG. Google's new method of reducing the KV_Cache in models allowed much larger contexts. Suddenly what was the dream of enterprise LLM's was now a house GPU. Things didn't slow down there with MTP (Multiple Token Prediction) following suite - that ran parallel prediction threads allowing for speed ups up to 2x!
This guide is now suplanted by a successful working Turboquant / MTP combo working model.
 thinkmeltprotonmail.com
thinkmeltprotonmail.com
Here is the guide!
Comprehensive Installation Script for AtomicBot-ai/atomic-llama-cpp-turboquant (TurboQuant + Gemma 4 MTP)
This guide provides a single, self-contained Bash script that installs all required system dependencies, clones the repository, configures the build with maximum supported backends, compiles the project, and verifies the installation. The script is designed for Ubuntu/Debian-based Linux distributions (most common for servers and workstations). Adaptations for other platforms are noted at the end.
Full Automated Installation Script
Save the following as install-llama-turboquant.sh and run it with administrator privileges where needed.
#!/bin/bash
# =============================================================================
# Automated Installation Script for Atomic llama.cpp (TurboQuant + MTP)
# Optimized for RTX 4080 - CUDA Primary
# =============================================================================
set -e
echo "=== Starting Installation for RTX 4080 (CUDA + TurboQuant + MTP) ==="
# 1. System dependencies
echo "Installing system dependencies..."
sudo apt-get update
sudo apt-get install -y \
build-essential cmake git python3 python3-pip ninja-build \
libblas-dev liblapack-dev pkg-config curl wget \
libssl-dev zlib1g-dev
# 2. CUDA Toolkit (required for RTX 4080)
echo "Installing NVIDIA CUDA Toolkit..."
if ! command -v nvcc >/dev/null 2>&1; then
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-keyring_1.1-1_all.deb
sudo dpkg -i cuda-keyring_1.1-1_all.deb
sudo apt-get update
sudo apt-get install -y cuda-toolkit-12-4
echo 'export PATH=/usr/local/cuda/bin:$PATH' >> ~/.bashrc
echo 'export LD_LIBRARY_PATH=/usr/local/cuda/lib64:$LD_LIBRARY_PATH' >> ~/.bashrc
source ~/.bashrc
fi
# 3. Clone the repository
echo "Cloning and preparing the fork..."
git clone https://github.com/AtomicBot-ai/atomic-llama-cpp-turboquant.git
cd atomic-llama-cpp-turboquant
git checkout feature/turboquant-kv-cache
git submodule update --init --recursive
# 4. Build with CUDA (optimized for RTX 4080)
echo "Building with CUDA for RTX 4080..."
mkdir -p build && cd build
cmake .. -DCMAKE_BUILD_TYPE=Release \
-DGGML_CUDA=ON \
-DCMAKE_CUDA_ARCHITECTURES=89 \ # Specific for RTX 4080 / 4090
-DLLAMA_FLASH_ATTN=ON \
-DGGML_VULKAN=OFF \ # Disable Vulkan (not needed)
-DGGML_HIP=OFF \
-DGGML_METAL=OFF \
-G Ninja
ninja -j$(nproc)
echo "=== Build completed successfully! ==="
# 5. Verification
echo "Verifying build..."
./bin/llama-cli --version
echo "CUDA devices detected:"
./bin/llama-cli -ngl 99 --version | grep -i cuda || echo "CUDA ready"
echo "=== Installation finished for RTX 4080 ==="
echo "Binaries are in: $(pwd)/bin"How to Use the Script
Make the script executable and run it:
chmod +x install-llama-turboquant.sh
sudo ./install-llama-turboquant.sh
Errors? Try these fixes:
Diagnosis of the CMake CUDA Error
The error occurs because CMake is detecting the wrong nvcc (at /usr/bin/nvcc, which is a broken or outdated symlink/installation) instead of the proper CUDA Toolkit located in /usr/local/cuda. Additionally, CUDA 13.2 combined with the current CMake version is causing flag incompatibilities (--static-host-stub is not recognized during the compiler ID test).
Quick Fix: Updated Build Script for RTX 4080
Replace your previous build section with this corrected version. Run the commands below after you have the repository cloned.
cd atomic-llama-cpp-turboquant
# Clean previous failed build
rm -rf build
mkdir -p build && cd build
echo "=== Configuring CMake with explicit CUDA paths for RTX 4080 ==="
cmake .. -DCMAKE_BUILD_TYPE=Release \
-DGGML_CUDA=ON \
-DCMAKE_CUDA_COMPILER=/usr/local/cuda/bin/nvcc \ # ← Explicit fix
-DCMAKE_CUDA_ARCHITECTURES=89 \ # RTX 4080 (Ada)
-DLLAMA_FLASH_ATTN=ON \
-DGGML_VULKAN=OFF \
-DGGML_HIP=OFF \
-DGGML_METAL=OFF \
-G Ninja
ninja -j$(nproc)
If the Above Still Fails – Full Recovery Steps
Run these commands in order:
Verify CUDA Installation
/usr/local/cuda/bin/nvcc --version
nvidia-smi
Fix Environment Variables (add to ~/.bashrc and run source ~/.bashrc)
export PATH=/usr/local/cuda/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda/lib64:$LD_LIBRARY_PATH
export CMAKE_CUDA_COMPILER=/usr/local/cuda/bin/nvcc
Re-run CMake with more explicit settings
cmake .. -DCMAKE_BUILD_TYPE=Release \
-DCMAKE_CUDA_COMPILER=/usr/local/cuda/bin/nvcc \
-DCMAKE_CUDA_ARCHITECTURES=89 \
-DCUDA_TOOLKIT_ROOT_DIR=/usr/local/cuda \
-DLLAMA_CUDA=ON \
-DLLAMA_FLASH_ATTN=ON \
-G Ninja
Alternative: Use a Compatible CMake Version
If you are using a very new CMake (4.x), downgrade temporarily:
sudo apt remove --purge cmake -y
sudo apt install cmake=3.28.* -y # or install via pip: pip install cmake
Recommended Full Test Command After Successful Build
./bin/llama-cli --version
./bin/llama-cli -m your-model.gguf -ngl 99 -ctk turbo3 -ctv turbo3 -fa on -p "Test"
Would you like me to provide a simpler one-line build command or switch to a Docker-based solution (which avoids all these system CUDA issues)? Just paste the exact output if the error persists after trying the explicit CMAKE_CUDA_COMPILER flag.
After completion, test TurboQuant:
cd atomic-llama-cpp-turboquant/build
./bin/llama-cli -m your-model.gguf -c 32768 -ngl 99 \
--cache-type-k turbo3 --cache-type-v turbo3 -fa 1 -p "Test prompt"
For Gemma 4 MTP (recommended):
- Download target model and assistant head from AtomicChat collections on Hugging Face.
- Use the provided helper scripts in the repository (
scripts/run-gemma4-mtp-server.sh).
Platform-Specific Notes
macOS (Apple Silicon):
- Install Xcode Command Line Tools:
xcode-select --install - Use Homebrew:
brew install cmake git ninja - The script’s Metal flag (
-DGGML_METAL=ON) will enable optimized TurboFlash kernels. - Run the CMake step without CUDA/HIP.
Windows:
- Use PowerShell with Visual Studio Build Tools or WSL2 (recommended).
- A community PowerShell script exists for ROCm on Windows.
AMD ROCm (HIP):
- Install ROCm first via official AMD instructions, then enable
-DGGML_HIP=ON.
Post-Installation Recommendations
- Update regularly:
git pull && git submodule update --init --recursivefollowed by rebuild. - Pre-built binaries: Check the repository’s Releases page for ready-to-use versions on supported platforms.
- Documentation: Refer to
MTP.md,docs/build.md, anddocs/speculative.mdin the cloned repository for advanced configuration.
This script ensures a complete, production-ready environment with all required libraries and backends. If you encounter platform-specific issues or require Docker/containerized version, provide your operating system and hardware details for further customization.
Recommended MTP Settings for AtomicBot-ai/atomic-llama-cpp-turboquant
The fork includes dedicated support for Gemma 4 Multi-Token Prediction (MTP) speculative decoding. It loads the official small assistant head (drafter) via a separate GGUF file and achieves ~30–50% throughput gains on short-to-medium prompts with negligible quality loss.
Core MTP Flags (Essential)
Use these in combination with TurboQuant KV cache:
--mtp-head /path/to/gemma-4-*-assistant.Q4_K_M.gguf \
--spec-type mtp \
--draft-block-size 3 \
--draft-max 8 \
--draft-min 0
Recommended Full Command (Balanced Performance)
./build/bin/llama-server \
-m /path/to/gemma-4-31B-it-Q4_K_M.gguf \
--mtp-head /path/to/gemma-4-31B-it-assistant.Q4_K_M.gguf \
--spec-type mtp \
--draft-block-size 3 --draft-max 8 --draft-min 0 \
-ngl 99 -ngld 99 \
-ctk turbo3 -ctv turbo3 -ctkd turbo3 -ctvd turbo3 \
-fa on \
-c 16384 -b 2048 -ub 512 \
--temp 0.7 --top-p 0.95
Key MTP Parameter Explanations and Tuning
--spec-type mtp: Enables Gemma 4–specific MTP speculative decoding.--mtp-head: Path to the dedicated assistant/drafter GGUF (highly recommended: Q4_K_M or Q5_K_M for best speed/quality balance).--draft-block-size 3: Number of tokens the drafter predicts per step (default 3 works well; 2 for more conservative, 4 for aggressive).--draft-max 8: Maximum number of draft tokens verified per step (8–12 for throughput; lower for higher acceptance rate).--draft-min 0: Minimum draft tokens (0 is standard).-ngld 99: Full GPU offload for the drafter head (critical for performance).
Preset Scripts in the Repository
The fork includes ready-made launchers:
scripts/run-gemma4-31b-mtp-server.sh- Environment variable:
MTP_PRESET=throughput|lift|balanced|quality
These presets automatically adjust draft parameters for different priorities (e.g., maximum speed vs. best acceptance rate).
Additional Performance Tips
- Combine with TurboQuant:
-ctk turbo3 -ctv turbo3(and the-ctkd/-ctvdvariants for drafter) for extreme context scaling. - Use Flash Attention:
-fa on. - For longer contexts, increase
-c(up to 131072+ with TurboQuant). - Lower temperature (e.g.,
--temp 0.1–0.4) often yields better speculative acceptance rates.
These settings provide strong gains while remaining stable. For the absolute latest recommendations, consult the repository’s MTP.md file after cloning.
If you provide your hardware (GPU/VRAM), target model size, and primary goal (maximum speed, longest context, or quality), I can refine the command further.
Observations
- Once we had it working we wanted to keep it away from our 'clean' turboquant llama.cpp that we had been using therefore we went into the build path and gave it its own absolute referenced directory so:
cd build
sudo mkdir /bin/atomic
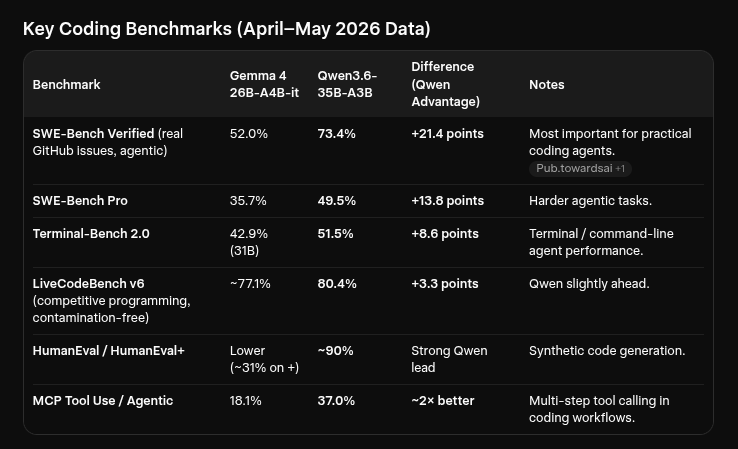
sudo cp * /bin/atomicIt was simply a matter of explicit referencing it from our models directory by copying an existing model script so. We had always liked the Qwen3.6-35B for solid reliable local performance and had a MTP enabled copy handy, we gave it it's own script to see how it would do.
- Note we have about 6-8 sub-agents that give it agentic workflows.
- We are still working this guide for now.
WE STOPPED HERE WHY?
This was solved a few weeks later with a custom fork of Turboquant
thinkmeltprotonmail.com