3-bit Unsloth Dynamic GGUF Outperforms models like Claude-4-Opus (Thinking) with a score of 75.6% on the Aider Polyglot Benchmark
3-bit Unsloth Dynamic GGUF Outperforms models like Claude-4-Opus (thinking) with a score of 75.6% on the Aider Polyglot benchmark


Seriously. Going by the post: https://x.com/UnslothAI/status/1965797776387879378 we quickly realize that we can get some serious LLM performance on low-end video cards. Let's try it out. Using Grok 4 to write a pilot was simple:
The NVIDIA RTX 3060 Ti has 8 GB of VRAM, which is a limiting factor for running large language models (LLMs) like DeepSeek-V3.1. The post highlights that the 3-bit Unsloth Dynamic GGUF outperforms models like Claude-4-Opus (thinking) with a score of 75.6% on the Aider Polyglot benchmark, and the 1-bit version shrinks the model from 671 GB to 192 GB (a 75% reduction in size). However, even the 3-bit or 1-bit quantized versions are still memory-intensive, so we need to optimize for the 8 GB VRAM constraint.
Unsloth AI's documentation and the X post suggest using techniques like 4-bit or dynamic quantization, along with offloading parts of the model to system RAM or using gradient checkpointing, to fit models onto GPUs with limited memory. Since the 3-bit GGUF is not directly mentioned as being optimized for 8 GB in the post, we'll assume it requires further optimization (e.g., using Unsloth's FastLanguageModel with 4-bit loading as a starting point, then adjusting for 3-bit if possible).
We always recommend at least the community edition of Pycharm. It just works.
 thinkmeltprotonmail.com
thinkmeltprotonmail.com
Prerequisites
- Install Unsloth: Ensure you have the Unsloth library installed. You can install it via pip: bash
pip install unslothFor RTX 3060 Ti, ensure you have the latest NVIDIA drivers and CUDA toolkit installed, as Unsloth leverages CUDA for GPU acceleration.
- Model Access: The 3-bit DeepSeek-V3.1 GGUF is available via Hugging Face. You'll need to download it from the unsloth/DeepSeek-V3.1-GGUF repository. Check the Hugging Face page for the exact 3-bit file (e.g., a file with "3-bit" in the name).
- System RAM: Since 8 GB VRAM is insufficient for the full model, you may need at least 16-32 GB of system RAM to offload parts of the model.
Python Script to Run 3-bit Unsloth DeepSeek-V3.1 on RTX 3060 Ti (This did Not Work on the 3060ti the Fix Followed)
Below is a Python script tailored to load and run the 3-bit Unsloth Dynamic DeepSeek-V3.1 GGUF model on your RTX 3060 Ti. This script uses Unsloth's FastLanguageModel with 4-bit quantization as a base (since 3-bit GGUF support might require custom handling), and includes optimizations to fit within 8 GB VRAM.
from unsloth import FastLanguageModel, FastTokenizer
import torch
from transformers import TextGenerationPipeline
# Set device to GPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# Model and tokenizer setup
model_name = "unsloth/DeepSeek-V3.1-GGUF" # Adjust to the exact 3-bit GGUF file if available
max_seq_length = 2048 # Adjust based on your needs
# Load the model with 4-bit quantization (fallback for 8 GB VRAM) and enable optimizations
model, tokenizer = FastLanguageModel.from_pretrained(
model_name=model_name,
max_seq_length=max_seq_length,
load_in_4bit=True, # Start with 4-bit to fit 8 GB, adjust to 3-bit if supported
load_in_8bit=False,
dtype=torch.float16, # Use half-precision to save memory
device_map="auto", # Automatically offload to CPU/RAM if needed
use_gradient_checkpointing=True, # Reduces VRAM usage at the cost of speed
)
# Apply LoRA for further optimization (optional, reduces memory footprint)
model = FastLanguageModel.get_peft_model(
model,
r=8, # Low rank for LoRA to save memory
target_modules=["q_proj", "k_proj", "v_proj", "o_proj"],
lora_alpha=16,
lora_dropout=0,
bias="none",
)
# Initialize text generation pipeline
generator = TextGenerationPipeline(model=model, tokenizer=tokenizer, device=0)
# Example input
prompt = "Hello, how can I assist you today?"
# Generate text
inputs = tokenizer(prompt, return_tensors="pt").to(device)
outputs = model.generate(
**inputs,
max_length=100,
num_return_sequences=1,
temperature=0.7,
top_p=0.95,
)
# Decode and print the output
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(generated_text)
# Clean up
del model, tokenizer, inputs, outputs
torch.cuda.empty_cache()Optimizations and Notes
- 4-bit Quantization as Fallback: The script uses load_in_4bit=True because the 3-bit GGUF might not be directly supported by FastLanguageModel out of the box. If a 3-bit GGUF file is available on Hugging Face, you may need to manually load it using llama.cpp or adjust the script to handle custom quantization (consult Unsloth's documentation for 3-bit support).
- Memory Management:
- device_map="auto" offloads parts of the model to system RAM, which is critical for the 3060 Ti's 8 GB VRAM.
- use_gradient_checkpointing=True trades computation time for memory savings.
- LoRA (Low-Rank Adaptation) reduces the memory footprint further.
- VRAM Check: The RTX 3060 Ti's 8 GB VRAM is tight for even a 4-bit quantized model. The 3-bit GGUF should theoretically fit better, but you may need to monitor VRAM usage with nvidia-smi and adjust max_seq_length or batch size if you encounter out-of-memory errors.
- Alternative Approach: If the above script fails due to memory constraints, consider using llama.cpp with the 3-bit GGUF file directly. Unsloth's documentation suggests compatibility with llama.cpp, and you can follow their guide to compile and run it:
- Clone llama.cpp from GitHub.
- Download the 3-bit GGUF file from Hugging Face.
- Run inference with llama-cli.
Limitations and Next Steps
- 3-bit Support: The script assumes 4-bit as a starting point. If Unsloth provides explicit 3-bit GGUF loading in their library by now (check their latest documentation or Hugging Face repo), update the load_in_4bit to load_in_3bit if available.
- Performance: Expect slower inference due to memory offloading and gradient checkpointing.
- Testing: Run the script and monitor VRAM usage. If it fails, reduce max_seq_length (e.g., to 512) or use a smaller model variant.
If you need further assistance or the script doesn't work as expected, please let me know the specific error, and I can refine it. Alternatively, I can offer to search for updated Unsloth documentation or community forums for 3-bit GGUF usage on 8 GB GPUs if needed!
Our Results?
We encontered errors, so you don't have to struggle to work through them:
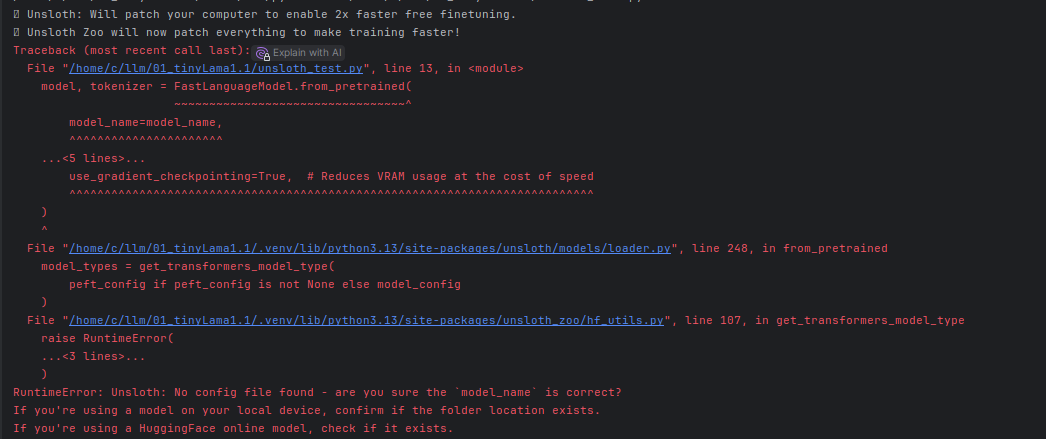
After suggesting these errors to Grok4, it then suggested we take the llama.cpp route:
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp
make
pip install llama-cpp-pythonThis took a little bit to install to a local directory:
After this Grok 4 suggested that the python script be amended as follows:
from llama_cpp import Llama
import torch
# Set device to GPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# Path to the downloaded 3-bit GGUF file
gguf_path = "/home/c/llm/01_tinyLama1.1/DeepSeek-V3.1-3bit.gguf" # Update this path
# Load the model with llama.cpp, optimized for 8 GB VRAM
llm = Llama(
model_path=gguf_path,
n_gpu_layers=35, # Use as many layers as possible on 8 GB VRAM (adjust based on testing)
n_ctx=512, # Context length, reduced for memory
f16_kv=True, # Use FP16 for key/value cache to save memory
low_vram=True, # Optimize for low VRAM
verbose=False,
)
# Example input
prompt = "Hello, how can I assist you today?"
# Generate text
output = llm(
prompt,
max_tokens=100,
temperature=0.7,
top_p=0.95,
stop=["\n"],
)
# Print the output
print(output["choices"][0]["text"])
# Clean up
del llm
torch.cuda.empty_cache()