The TurboQuant BreakThrough. Running Qwen3.5-35B-A3B-UD-IQ3_XXS.gguf with a Hermes Agent. Get $80K Enterprise Server Performance on a $800 House GPU.
The TurboQuant BreakThrough. Running Qwen3.5-35B-A3B-UD-IQ3_XXS.gguf with a Hermes Agent. Get $80K Enterprise Server Performance on a House GPU.


How One Single Mathematical Paper Increased LLM Performance by 600%.
- This is big, not just a little big but really, really REALLY flipping big. What used to require an Enterprise Grade Server with 2xH100 GPU compute and $80,000 can now be run on a House GPU for under $1000. Seriously.
- The implications are absolutely astounding. It enabled a home user to get access to 9 million tokens of compute generation daily - cost $0. People paying for Claude don't need it - at all.
- This has literally just came out a few days prior to this article, and as this is being written, usages for this new TurboQuant algorithm are still filtering backwards through the LLM model space.
- It brought serious level compute to the total masses. No longer do you need a DGI Spark, or a 4x3090 home cluster with a $1500 TR40 Server. Just one good decent 16 GB or less GPU card. What was the domain and moat of large enterprises is now available to anyone with gaming compute.
- You will need a custom fork the 'Turboquant' Fork of llama-cpp. We have written a full guide, follow it, try it then come back here.
 thinkmeltprotonmail.com
thinkmeltprotonmail.com
Have it installed and working per the guide? Now it gets interesting. The model in the above guide accelerated the kv-cache, but models were already coming out that accelerted the entire model! Consider:

Download this model to your present working directory with:
hf download Manojb/Qwen3.5-35B-A3B-UD-IQ3_XXS.gguf --local-dir .This thing is powerful, we were able to get the following on a 4080 w/ 16GB of VRAM.
262K Contexts, 105 Tokens/s, and 35B MoE (Mixture of Experts!)
So you can run it with powerful settings.
- If it runs out of RAM, just lower the -c 262144 to a lower number like 65536 etc.
- An example run setup:
/usr/bin/llama-server -m /home/c/PythonProject/TurboResearcher/models/Qwen3.5-35B-A3B-UD-IQ3_XXS.gguf --host 192.168.1.3 --n-gpu-layers -1 --flash-attn on --cache-type-k q8_0 --cache-type-v turbo3 -c 262144 --temp 0.7
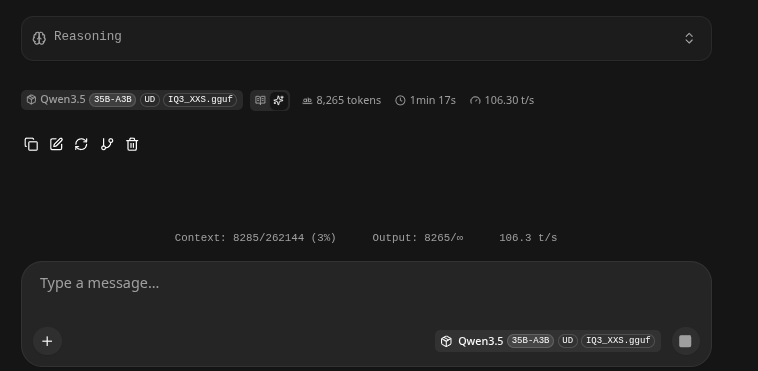
By itself this is a very powerful LLM, SOTA level. Game changing level, now lets add Hermes that will connect it to the internet and activate its tooling:
- Tooling lets it look stuff up.
- Tooling activates your agentic workflows
- Tooling lets your LLM test it's own software to make sure it works.
- Tooling lets your LLM browse on the internet for you..
- Tooling lets you connect to it via Telegram, Discord, or other service and control it from a phone - anywhere in the world.
Setting up Hermes
curl -fsSL https://raw.githubusercontent.com/NousResearch/hermes-agent/main/scripts/install.sh | bashYou simply point it to your Lllama-cpp, which is usually on port 8080, by setting a custom LLM.
192.168.1.3:8080- Quick Setup:

- More Providers:
- Custom Endpoint
- Type in the IP:8080 where you are running Llama-cpp: In our case we had already added it.
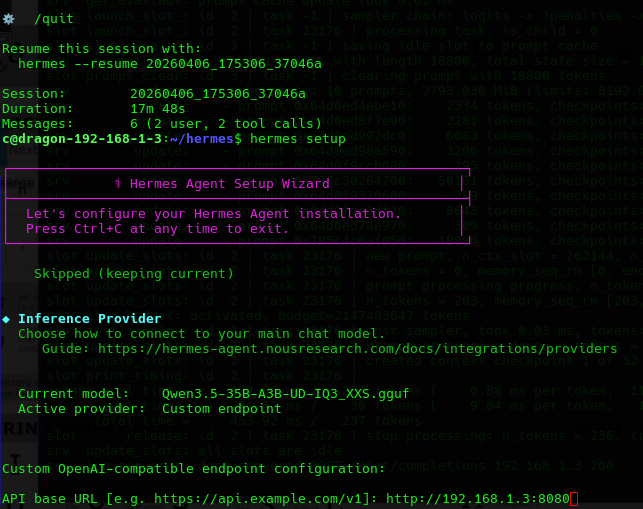
- From here you can add connectors to control your system from anywhere via discord, telegram and various other chat interfaces..
Once it is installed it will show up as:
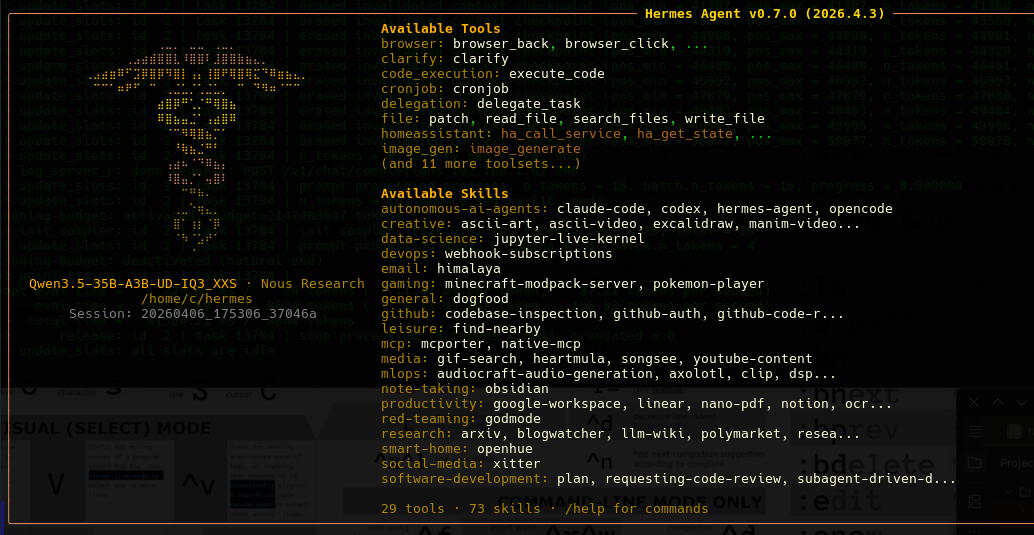
- Enabling chat and a zillion features.
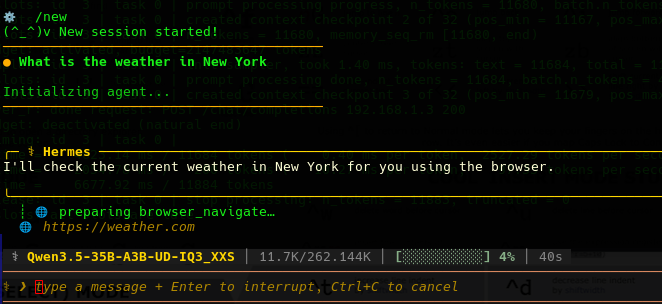
Type /new you will start a new session. For instance:
What is the weather in New York.- Remember LLM's operate in isolation, they are a nucleus of mathematical weights, however tooling allows it and shows it that it can connect and do things.
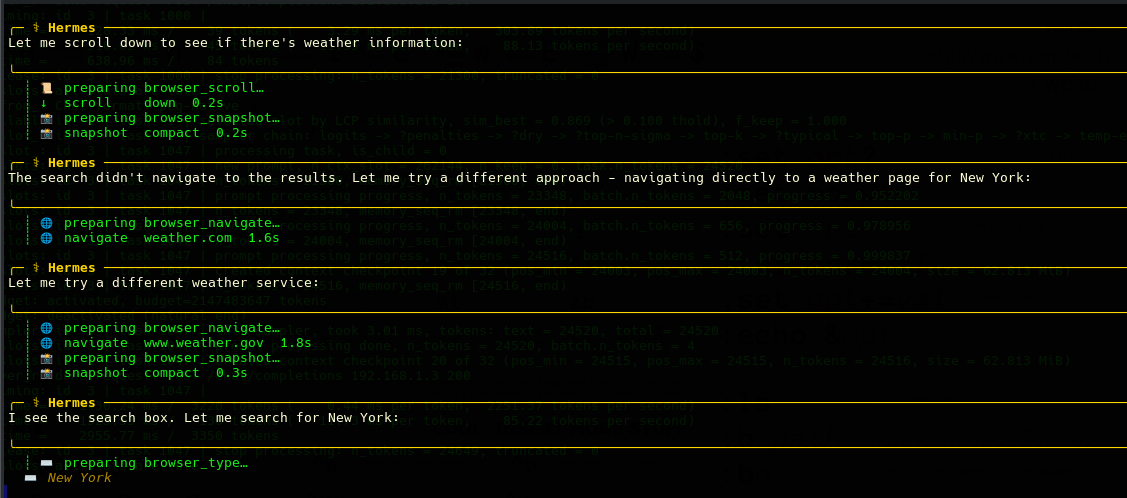
- What is amazing here is the LLM is trying things, using the tool and looking up various web sites until it is able to confidently get an answer:
- It find the answer!
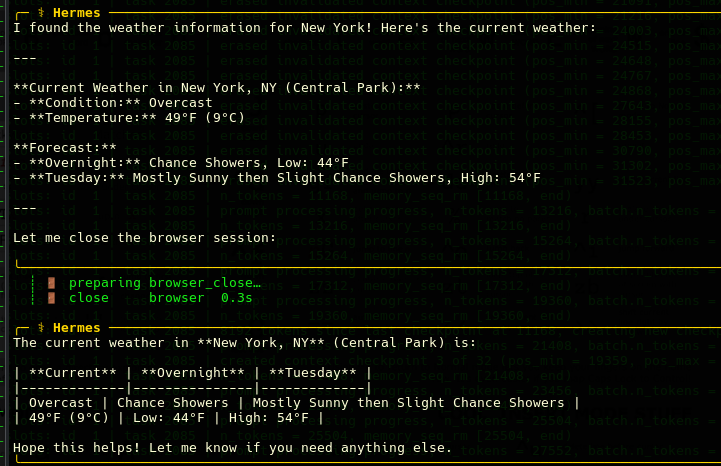
Why is this BIG BIG BIG?
- The cost is $0 + 1 House GPU. You are getting the capabilities near that of a World Class SOTA LLM for pennies!
Next up we do a much deeper dive into our tool exporation capabilities!
