The Great AI Explosion - Transformative Development (Part 2 - Levels of Coding Automation)
In this article we go over the current leader boards that track LLM's, and METR - which is tracking the current progress of LLM's in replacing software developers.


- Highly debuted, the SWE-Bench shows us how quickly and how much AI has automated the task of a software developer (nobody is even looking at how it's replaced book writing..)
- %Resolved infers the percentage of tasks that the AI was able to complete successfully.
- Task Instances: SWE-bench includes various datasets, such as 2,294 tasks in the Full set, 500 in Verified, 300 in Lite, 517 in Multimodal, and 500 in Several sub-boards and this will metric the different types of knowledge proficiency desired, be it math, computing, language etc. Bash Only. Each task represents a GitHub issue tied to a pull request that modifies test-related files.
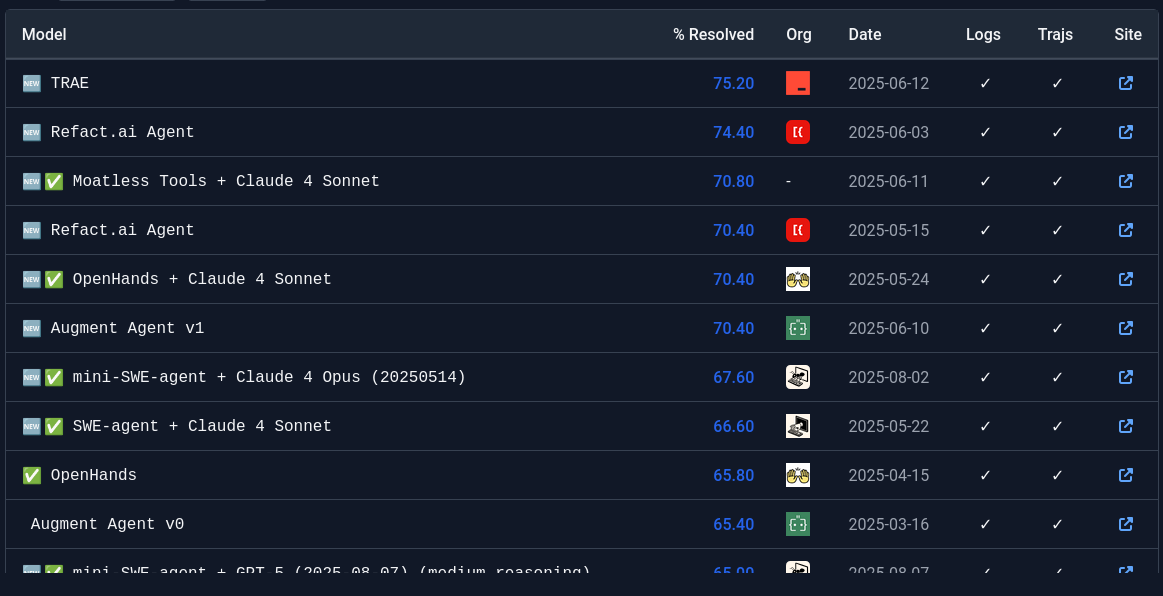
- In this instance TRAE was able to initiate pull-requests, complete the task and push back 75% of the time with copetency...
General Benchmarks:
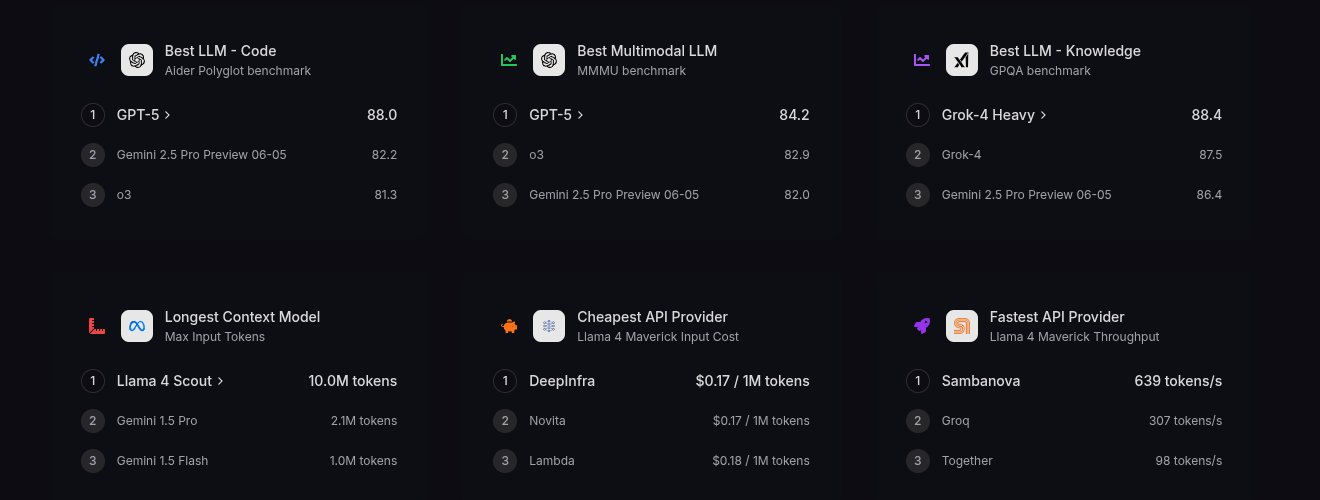
- Can be viewed at the LLM Leaderboard 2025.

- These are often more generalized LLM's that have massive training costs, massive parameter model counts, and are intended for very wide audiences.
Many smaller LLM's are free and open, and can be run on local hardware.
- GPQA - GPQA is a graduate-level benchmark testing LLMs on expert, search-resistant questions in sciences like biology and physics, measuring advanced reasoning with accuracy scores.
- MMLU - MMLU evaluates LLMs' broad knowledge across 57 subjects through multiple-choice questions, serving as a baseline for multitask understanding with zero- or few-shot accuracy.
- MMLU Pro - MMLU Pro enhances the original MMLU with harder, reasoning-focused questions to better differentiate top models' problem-solving abilities in diverse domains.
- DROP- DROP assesses reading comprehension and discrete reasoning, requiring LLMs to perform operations like arithmetic from paragraphs, scored via F1 or exact match accuracy.HumanEvalHumanEval tests code generation by having LLMs write functional Python code for 164 problems, evaluated on pass@1 success rates against unit tests.
- Multimodal - Multimodal benchmarks on llm-stats.com evaluate LLMs' integration of text with images or other data types for tasks like visual reasoning, often using datasets like MMMU.
Several sub-boards will metric the different types of knowledge proficiency desired, be it math, computing, language etc.
Introduction to Metr.org
 19 March 2025
19 March 2025
From their website:
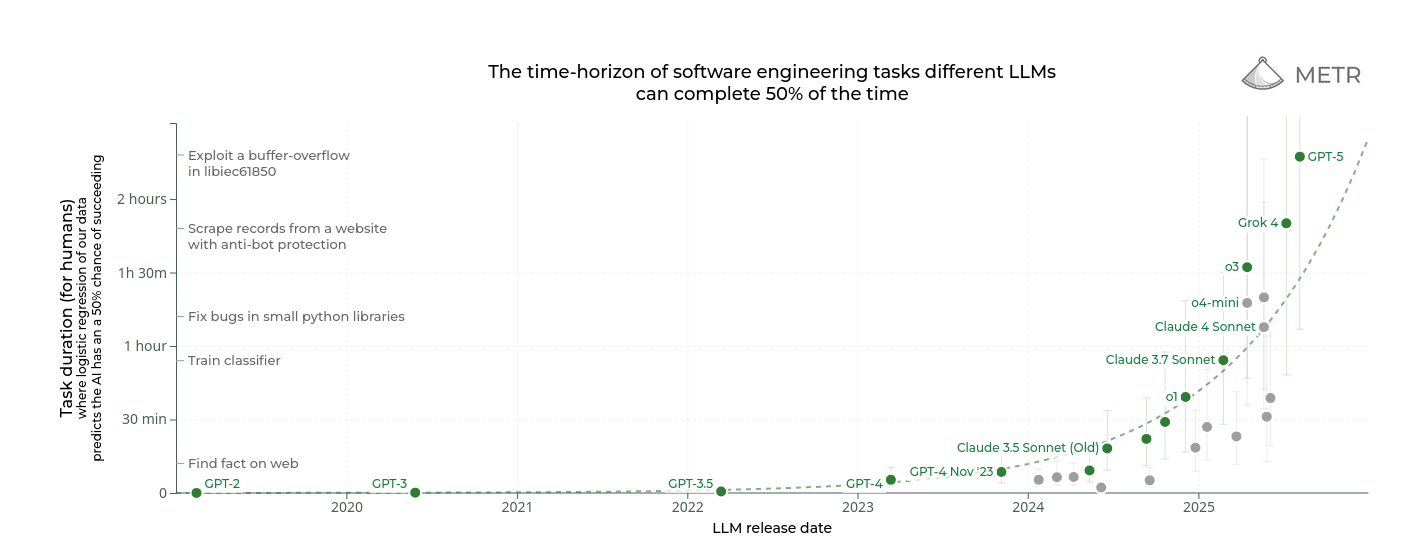
"Summary: We propose measuring AI performance in terms of the length of tasks AI agents can complete. We show that this metric has been consistently exponentially increasing over the past 6 years, with a doubling time of around 7 months. Extrapolating this trend predicts that, in under a decade, we will see AI agents that can independently complete a large fraction of software tasks that currently take humans days or weeks."
- Doubling time is 7 months. Current leading LLM's can complete tasks that took a software engineer two hours, with a 50% success rate.
- In 3-4 years LLM's should be able to successfully do the work of a software developer 90% of the time for hours on end.
- This will not replace software developers, it will replace software developers that do not use these assistive tools.
- It will result in signficant reductions in team sizes - think Pareto Principle type retention.
- It will see an exodus from software development, and I will explain why in Part III.
