Speed Comparisons GPU/CPU vs CPU only. Running Magistral-24B on a Budget.
Speed Comparisons GPU/CPU vs CPU only. Running Magistral-24B on a budget.


The long and the short is - if speed is relatively unimportant aka for back-mode batching - and we do not have $1000's lying around to buy hi-end A-40 card, what is the inference speed of a larger model if the entire thing runs in ram? Ironically it should be noted even Walmart sells them!
- We test a 24b model on a 32GB Ryzen 9 (12 core - 24 thread). Once on CPU only and once adding in a 3060ti.
- It should be noted that "Magistral-Small-2509-Q4_K_M.gguf'' is key the Q4 shows us that it is going to use 4-bit models.
Grok 4 gives us some boiler plate code to bootstrap the project and we use the free version of Pycharm.
 thinkmeltprotonmail.com
thinkmeltprotonmail.com
- Version 1: CPU Only Version (n_gpu_layers=0)
from huggingface_hub import hf_hub_download
from llama_cpp import Llama
import time
# Download the quantized GGUF model file from Hugging Face
repo_id = "mistralai/Magistral-Small-2509-GGUF"
filename = "Magistral-Small-2509-Q4_K_M.gguf"
model_path = hf_hub_download(repo_id=repo_id, filename=filename)
# Load the model entirely on CPU (n_gpu_layers=0 ensures no GPU offloading)
llm = Llama(
model_path=model_path,
n_gpu_layers=0, # Force CPU-only execution
n_ctx=40960, # Context window size (adjust as needed based on memory)
verbose=False # Suppress detailed logging
)
# Define a sample prompt for inference
for x in range(5):
rnow = time.perf_counter()
prompt = "Hello, how are you today?"
# Perform inference
output = llm(prompt, max_tokens=100, temperature=0.7, top_p=0.9)
# Extract and print the generated text
generated_text = output['choices'][0]['text']
gen_len = len(generated_text)
rthen = time.perf_counter()
elap = rthen - rnow
tps = gen_len / elap
print(f"{elap:0.2f}S for {gen_len} {tps}tokens. Generated response:", generated_text)- Even if you have installed a pile of previous python packages, this one required llama_cpp a 50 MB python package!
- Each time you run a new model the VERY large shards and setup will be downloaded. Expect a good 10 minute setup or more depending on model size.
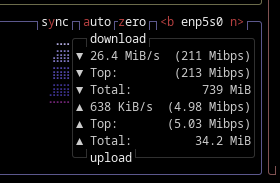
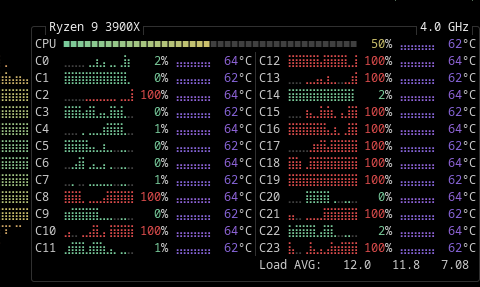
- It gave us the following times:
- 55.93s for 434 Tokens / 7.8 tps
- 46.60s for 220 Tokens / 4.7 tps
- 46.48s for 475 Tokens / 10 tps
- 46.74 for 384 Tokens / 8.2 tps
- 46.58 for 439 Tokens / 9.4 tps
8.2 Tokens Per/Second. Or roughly 29,250 Tokens Per/Hour. Tokens / 1.33 = 22,195 words/per/hour. At 13 cents per kwh factoring in a Ryzen 9 = ~ 10,000 words/penny.
Now let's add back in a 3060ti, and re-run this simulation.
Fail. It didn't use the GPU card at all! Again we get about 8.5 ish Tokens per second. Looking at the nvidia-smi (which does show up on various small < 7b LLM models - shows it didn't actually load to RAM.)
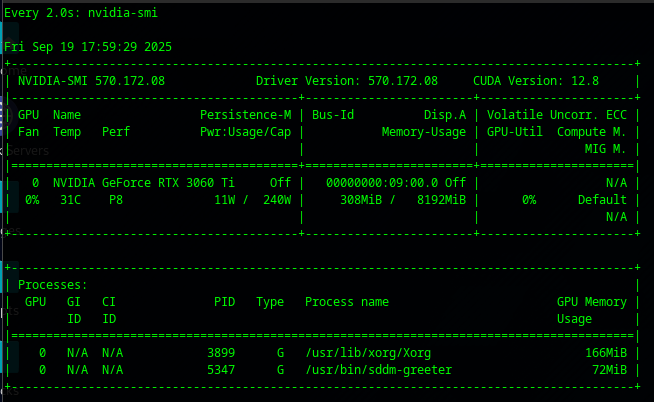
There was quite a few issues with drivers, and we worked to make sure that ensurpip was installed, and then rebooted, we also turned on verbose.
- We finally noted the following error in the verbose log:

We then switched to 8-bit Quantization, by selecting another model:
from huggingface_hub import hf_hub_download
from llama_cpp import Llama
import time
# Download the quantized GGUF model file from Hugging Face (switch to Q8_0)
repo_id = "mistralai/Magistral-Small-2509-GGUF"
filename = "Magistral-Small-2509-Q8_0.gguf" # Adjusted to Q8_0 for potential compatibility with CPU_REPACK
model_path = hf_hub_download(repo_id=repo_id, filename=filename)
# Load the model with GPU offloading
llm = Llama(
model_path=model_path,
n_gpu_layers=15, # Retain partial GPU offloading
n_ctx=4096,
verbose=True # Keep verbose to monitor if the warning persists
)
# Inference loop remains unchanged
while True:
rnow = time.perf_counter()
prompt = "Hello, how are you today?"
output = llm(prompt, max_tokens=100, temperature=0.7, top_p=0.9)
generated_text = output['choices'][0]['text']
gen_len = len(generated_text)
rthen = time.perf_counter()
elap = rthen - rnow
tps = gen_len / elap
print(f"{elap:0.2f}S for {gen_len} {tps:0.2f} tps. . Generated response:", generated_text)- Please note if you download a Q_4 (4-bit) model then decide you want to run a Q_8 (8-bit) model you get to download it all again!

- No change. At this time we did not get very good load balancing.
