Running the LLM Ring-Mini 2.0 16B on Ryzen 9 w/2 3060ti Nvidia GPUs.
Running the Ring-Mini 2.0 16B on Ryzen 9 w/2 3060ti Nvidia GPUs.


- The idea is can one run reasonably thinking, and accurate LLM's from the home and have somewhat decent token speed, and somewhat decent inference.?
- We take a look at just that and here is what it came up with:
- The model is located here
Our python code block:
import time
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "inclusionAI/Ring-mini-2.0"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto",
trust_remote_code=True
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
while True:
rnow = time.perf_counter()
prompt = "Give me a short introduction to large language models."
messages = [
{"role": "system", "content": "You are Ring, an assistant created by inclusionAI"},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=True
)
model_inputs = tokenizer([text], return_tensors="pt", return_token_type_ids=False).to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=8192
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
rthen = time.perf_counter()
elap = rthen - rnow
rcount = response.split(' ')
rcount_len = len(rcount)
print(f'{elap:0.2f}seconds for {rcount_len} words.. {elap/rcount_len:0.2f}wps \n {response}')- The first time running these takes some time as all the shards and models must be downloaded. It can take 10-25 minutes for the large models to download.
- This code is designed to simply repeatedly ask the same query over and over again and hopefully get different results.
- We like the reasoning option. In a 16B package we are very happy.
- There are real limits as soon as you start talking on your PCIe bus, transfers between the GPU and CPU are expensive.
- 348.69seconds for 565 words.. 0.62wps - First output.
Okay, the user asked for a short introduction to large language models. Let me start by recalling what I know. LLMs are AI systems trained on massive datasets to understand and generate human-like text. They use deep learning, especially transformer architectures.
Hmm, the user might be new to AI, so I should avoid jargon. But since they asked for an introduction, they probably want a clear, concise overview. Maybe they're a student, a professional looking to understand tech trends, or someone curious about AI. Their main need is a foundational understanding without getting overwhelmed.
I should cover key points: what LLMs are, how they work (training data, neural networks), their capabilities (text generation, translation, etc.), and their impact. Also, mention challenges like bias and resource use.
Wait, the user said "short," so I need to be brief. But not too brief to miss essentials. Structure it in sections: definition, how they work, uses, pros/cons. Use simple terms. Avoid markdown as per the rules.
Check if there are common misconceptions. For example, some think LLMs are conscious, but they're tools. Clarify that. Also, note that they learn patterns, not true understanding.
Include real-world applications to make it relatable. Chatbots, content creation, etc. But balance with limitations to set realistic expectations.
Make sure the tone is neutral and informative. Since I'm Ring, maintain a helpful, approachable style. End with a note on their transformative role in tech.
Double-check facts: training data size (terabytes to petabytes), model sizes (billions of parameters), inference vs. training. Avoid technical deep dives unless necessary.
Finally, keep it engaging. Use examples like writing emails or summarizing articles. That should cover the user's needs and any underlying curiosity about how LLMs affect daily life.
</think>
Here's a concise introduction to Large Language Models (LLMs):
**Large Language Models (LLMs) are advanced artificial intelligence systems trained on massive amounts of text data to understand, generate, and manipulate human language.** They use deep learning (specifically transformer architectures) to learn patterns, relationships, and nuances in language from their training data.
**Key characteristics:**
1. **Scale:** They have billions (or more) of parameters (internal variables), making them extremely complex.
2. **Capabilities:** They can perform tasks like text generation (writing stories, emails, code), translation, summarization, question answering, and even basic reasoning *based on patterns learned from data*.
3. **Training:** They are trained on vast datasets (like web text, books, articles) using techniques like self-supervised learning, where the model learns to predict the next word in a sequence.
4. **Inference:** Once trained, they can be used to generate or analyze text when given an input prompt.
**Why they matter:**
* **Revolutionize Interaction:** Enable natural, conversational AI (chatbots, virtual assistants).
* **Automate Content:** Assist in writing, editing, and content creation.
* **Enhance Research:** Aid in data analysis, scientific discovery, and code generation.
* **Drive Innovation:** Power new applications across industries (healthcare, education, customer service, creative tools).
**Challenges:**
* **Bias & Fairness:** Can inherit biases from training data.
* **Hallucinations:** May generate incorrect or nonsensical information.
* **Resource Intensity:** Require significant computational power and data for training.
* **Interpretability:** Understanding *why* a model makes a specific decision can be difficult.
- 347.24seconds for 565 words.. 0.61wps - second output
Okay, the user asked for a short introduction to large language models. Let me start by recalling what I know. LLMs are AI systems trained on massive datasets to understand and generate human-like text. They use deep learning, especially transformer architectures.
Hmm, the user might be new to AI, so I should avoid jargon. But since they asked for an introduction, they probably want a clear, concise overview. Maybe they're a student, a professional looking to understand tech trends, or someone curious about AI. Their main need is a foundational understanding without getting overwhelmed.
I should cover key points: what LLMs are, how they work (training data, neural networks), their capabilities (text generation, translation, etc.), and their impact. Also, mention challenges like bias and resource use.
Wait, the user said "short," so I need to be brief. But not too brief to miss essentials. Structure it in sections: definition, how they work, uses, pros/cons. Use simple terms. Avoid markdown as per the rules.
Check if there are common misconceptions. For example, some think LLMs are conscious, but they're tools. Clarify that. Also, note that they learn patterns, not true understanding.
Include real-world applications to make it relatable. Chatbots, content creation, etc. But balance with limitations to set realistic expectations.
Make sure the tone is neutral and informative. Since I'm Ring, maintain a helpful, approachable style. End with a note on their transformative role in tech.
Double-check facts: training data size (terabytes to petabytes), model sizes (billions of parameters), inference vs. training. Avoid technical deep dives unless necessary.
Finally, keep it engaging. Use examples like writing emails or summarizing articles. That should cover the user's needs and any underlying curiosity about how LLMs affect daily life.
</think>
Here's a concise introduction to Large Language Models (LLMs):
**Large Language Models (LLMs) are advanced artificial intelligence systems trained on massive amounts of text data to understand, generate, and manipulate human language.** They use deep learning (specifically transformer architectures) to learn patterns, relationships, and nuances in language from their training data.
**Key characteristics:**
1. **Scale:** They have billions (or more) of parameters (internal variables), making them extremely complex.
2. **Capabilities:** They can perform tasks like text generation (writing stories, emails, code), translation, summarization, question answering, and even basic reasoning *based on patterns learned from data*.
3. **Training:** They are trained on vast datasets (like web text, books, articles) using techniques like self-supervised learning, where the model learns to predict the next word in a sequence.
4. **Inference:** Once trained, they can be used to generate or analyze text when given an input prompt.
**Why they matter:**
* **Revolutionize Interaction:** Enable natural, conversational AI (chatbots, virtual assistants).
* **Automate Content:** Assist in writing, editing, and content creation.
* **Enhance Research:** Aid in data analysis, scientific discovery, and code generation.
* **Drive Innovation:** Power new applications across industries (healthcare, education, customer service, creative tools).
**Challenges:**
* **Bias & Fairness:** Can inherit biases from training data.
* **Hallucinations:** May generate incorrect or nonsensical information.
* **Resource Intensity:** Require significant computational power and data for training.
* **Interpretability:** Understanding *why* a model makes a specific decision can be difficult.
**In short:** LLMs are powerful language understanding and generation tools that learn from huge text datasets, enabling a wide range of AI applications but also presenting important ethical and technical challenges. They represent a major leap in AI's ability to interact with human language.
Notes: We get the exact same information from asking the same question twice. However it did a reasonably good job.
- 0.62 wps = ~ 53,000 words per day. It would effectively be a machine writing for you about ~105 500 word articles per day.
Here are some screenshots of the nvidia-smi.
- We can see it was using about 40/47W on the two 3060tis and they were typically utilizing about 6000 MB each.
- We can see an additional 26 GB was used on the CPU.
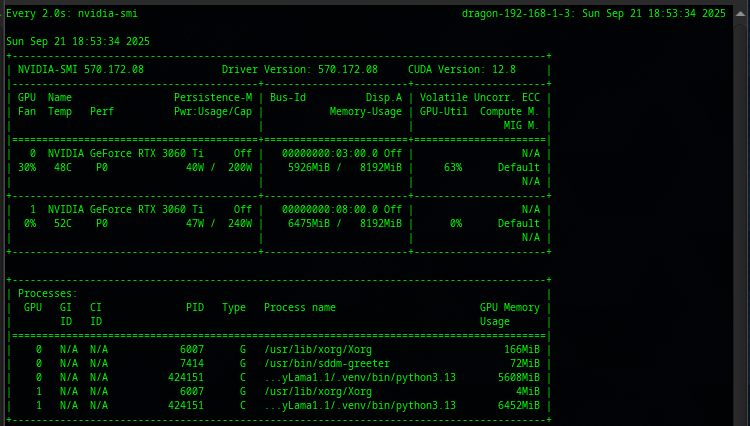
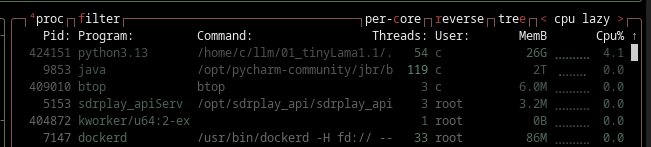
- Again the same thing happens repeatedly. The moment that your LLM offloads to the CPU you will see a dramatic performance drop.
- It was expected that this model would run without CPU offloading. Again it did not. It is still being looked for to find a model that acutally uses both GPU's but does not use the CPU..
