LLM TurboQuant Example! Qwen3.5 27B Agentic Workflow Primer. Running Unlimited Token Code Bot on a $800 4080ti 16GB VRAM House GPU!! (Part 2)
Qwen3.5 27B Agentic Workflow Primer. Running Unlimited Token Code Bot on a $800 4080ti 16GB VRAM House GPU!!


If you want to read this series from the start:
 thinkmeltprotonmail.com
thinkmeltprotonmail.com
In this article we were successful in getting the TurboQuant compressed variant of Qwen3.5 running on a single 4080ti. This is a utter game changer because it allowed for a respectable, work-class and powerful LLM to run on a single house garden GPU that has 16 GB of VRAM.
- Think about that, no subscription required, a semi-sota level LLM that can exist on $800 of hardward not $80,000.
- Setting it up was a little challenging and we spent an entire day figuring it out and writing the guide, and by the end of the day it was setup and ready, for the BIG SHOW seeing if we can run a small agentic workflow.
thinkmeltprotonmail.com
Ready lets do this:
- We will start up a llm-server, and start building there, here is where it gets exciting because it will tell us the next steps in setting up the API, and from there we will build a agentic workflow tool.
- We used explicit directory references. We have found over and over again in a messy environment setup, this is atypically the easiest way.
- The above link has the full installation guide.
/usr/bin/llama-server -m /home/c/PythonProject/TurboResearcher/models/Qwen3.5-27B-TQ3_1S.gguf --host 192.168.1.3 --n-gpu-layers -1 --flash-attn on --cache-type-k q8_0 --cache-type-v turbo3-c 8192 --temp 0.7Once it is running you can browse over to its web interface - we bound it to the 192.168.1.3 address, with a browser.
http://192.168.1.3
- Now we are going to use it in a production manner all day - that is no sneaking off to the SOTA subscription to get instant answers, we want to see if we can bootstrap ourselves via this manner. In other words can it completely replace the commercial LLM's?
- llama-server gives a really nice interface that shows you as your LLM works..
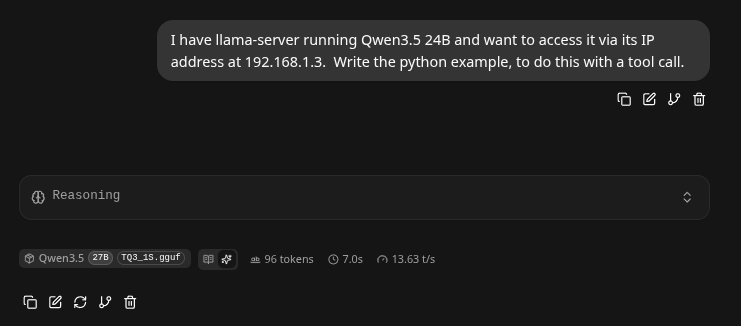
We will paste it's results.
Here's a complete Python example to connect to your llama-server running Qwen3.5 24B at 192.168.1.3 and perform a tool call using its OpenAI-compatible API:
import requests
import json
# Configuration
LLAMA_SERVER_URL = "http://192.168.1.3:8080" # Adjust port if needed
MODEL_NAME = "Qwen3.5-24B" # Adjust based on your server's model name
API_KEY = "" # Optional, if your server requires authentication
# Define the tool schema
TOOLS = [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get the current weather for a given city",
"parameters": {
"type": "object",
"properties": {
"city": {
"type": "string",
"description": "The city name"
}
},
"required": ["city"]
}
}
}
]
# Function to execute tool logic
def execute_tool(name, arguments):
if name == "get_weather":
city = arguments.get("city", "Unknown")
return f"Weather in {city}: 22°C, Sunny"
return f"Unknown tool: {name}"
# Send message to llama-server
def query_llama(messages, use_tools=False):
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {API_KEY}" if API_KEY else ""
}
payload = {
"model": MODEL_NAME,
"messages": messages,
"stream": False,
"tools": TOOLS if use_tools else None
}
try:
response = requests.post(
f"{LLAMA_SERVER_URL}/v1/chat/completions",
headers=headers,
json=payload,
timeout=30
)
response.raise_for_status()
return response.json()
except requests.exceptions.RequestException as e:
print(f"Error: {e}")
return None
# Example usage
def main():
messages = [
{"role": "user", "content": "What's the weather in Tokyo?"}
]
# First call to get tool invocation
response = query_llama(messages, use_tools=True)
if response and "choices" in response:
choice = response["choices"][0]
message = choice["message"]
if "tool_calls" in message:
for tool_call in message["tool_calls"]:
name = tool_call["function"]["name"]
args = json.loads(tool_call["function"]["arguments"])
result = execute_tool(name, args)
messages.append({"role": "assistant", "content": "", "tool_calls": [tool_call]})
messages.append({"role": "tool", "name": name, "content": result})
# Second call to get final response
final_response = query_llama(messages, use_tools=False)
if final_response:
print(final_response["choices"][0]["message"]["content"])
else:
print(message["content"])
if __name__ == "__main__":
main()
Notes:
- Server URL: Adjust the port (
8080in this example) if yourllama-serveris running on a different one. - Authentication: If your server requires an API key, set it in
API_KEY. - Tool Execution: The
execute_tool()function should be expanded based on your actual tools or external APIs. - Model Name: Ensure the model name matches what
llama-serverexposes.
Installation Requirements
pip install requests
This example demonstrates how to connect to llama-server over HTTP, send a message with tools enabled, process tool calls, and handle the final response — all compatible with OpenAI-style function calling.
Hotconfig.com Note - we only ran a 8192 contextual length, lets see if it can do it again with a 32768 context length and what it produes. The results:
/usr/bin/llama-server -m /home/c/PythonProject/TurboResearcher/models/Qwen3.5-27B-TQ3_1S.gguf --host 192.168.1.3 --n-gpu-layers -1 --flash-attn on --cache-type-k q8_0 --cache-type-v turbo3 -c 32768 --temp 0.9The back-end produces a very verbose logging, so you can see what the Qwen3.5 is doing:
./server_32768.sh
ggml_cuda_init: found 1 CUDA devices (Total VRAM: 15910 MiB):
Device 0: NVIDIA GeForce RTX 4080, compute capability 8.9, VMM: yes, VRAM: 15910 MiB
main: n_parallel is set to auto, using n_parallel = 4 and kv_unified = true
system info: n_threads = 12, n_threads_batch = 12, total_threads = 24
system_info: n_threads = 12 (n_threads_batch = 12) / 24 | CUDA : ARCHS = 890 | USE_GRAPHS = 1 | PEER_MAX_BATCH_SIZE = 128 | CPU : SSE3 = 1 | SSSE3 = 1 | AVX =1 | AVX2 = 1 | F16C = 1 | FMA = 1 | BMI2 = 1 | LLAMAFILE = 1 | OPENMP = 1 | REPACK = 1 |
Running without SSL
init: using 23 threads for HTTP server
start: binding port with default address family
main: loading model
srv load_model: loading model '/home/c/PythonProject/TurboResearcher/models/Qwen3.5-27B-TQ3_1S.gguf'
common_init_result: fitting params to device memory, for bugs during this step try to reproduce them with -fit off, or provide --verbose logs if the bug only occurs with -fit on
llama_params_fit_impl: projected to use 14453 MiB of device memory vs. 14989 MiB of free device memory
llama_params_fit_impl: cannot meet free memory target of 1024 MiB, need to reduce device memory by 487 MiB
llama_params_fit_impl: context size set by user to 32768 -> no change
llama_params_fit_impl: filling dense layers back-to-front:
llama_params_fit_impl: - CUDA0 (NVIDIA GeForce RTX 4080): 62 layers, 13867 MiB used, 1122 MiB free
llama_params_fit: successfully fit params to free device memory
llama_params_fit: fitting params to free memory took 3.05 seconds
llama_model_load_from_file_impl: using device CUDA0 (NVIDIA GeForce RTX 4080) (0000:07:00.0) - 15589 MiB free
llama_model_loader: loaded meta data with 44 key-value pairs and 851 tensors from /home/c/PythonProject/TurboResearcher/models/Qwen3.5-27B-TQ3_1S.gguf (version GGUF V3 (latest))
llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output.
llama_model_loader: - kv 0: general.architecture str = qwen35
llama_model_loader: - kv 1: general.type str = model
llama_model_loader: - kv 2: general.sampling.top_k i32 = 20
llama_model_loader: - kv 3: general.sampling.top_p f32 = 0.950000
llama_model_loader: - kv 4: general.sampling.temp f32 = 0.600000
llama_model_loader: - kv 5: general.name str = Qwen3.5 27B
llama_model_loader: - kv 6: general.basename str = Qwen3.5
llama_model_loader: - kv 7: general.size_label str = 27B
llama_model_loader: - kv 8: general.license str = apache-2.0
llama_model_loader: - kv 9: general.license.link str = https://huggingface.co/Qwen/Qwen3.5-2...
llama_model_loader: - kv 10: general.tags arr[str,1] = ["image-text-to-text"]
llama_model_loader: - kv 11: qwen35.block_count u32 = 64
llama_model_loader: - kv 12: qwen35.context_length u32 = 262144
llama_model_loader: - kv 13: qwen35.embedding_length u32 = 5120
llama_model_loader: - kv 14: qwen35.feed_forward_length u32 = 17408
llama_model_loader: - kv 15: qwen35.attention.head_count u32 = 24
llama_model_loader: - kv 16: qwen35.attention.head_count_kv u32 = 4
llama_model_loader: - kv 17: qwen35.rope.dimension_sections arr[i32,4] = [11, 11, 10, 0]
llama_model_loader: - kv 18: qwen35.rope.freq_base f32 = 10000000.000000
llama_model_loader: - kv 19: qwen35.attention.layer_norm_rms_epsilon f32 = 0.000001
llama_model_loader: - kv 20: qwen35.attention.key_length u32 = 256
llama_model_loader: - kv 21: qwen35.attention.value_length u32 = 256
llama_model_loader: - kv 22: qwen35.ssm.conv_kernel u32 = 4
llama_model_loader: - kv 23: qwen35.ssm.state_size u32 = 128
llama_model_loader: - kv 24: qwen35.ssm.group_count u32 = 16
llama_model_loader: - kv 25: qwen35.ssm.time_step_rank u32 = 48
llama_model_loader: - kv 26: qwen35.ssm.inner_size u32 = 6144
llama_model_loader: - kv 27: qwen35.full_attention_interval u32 = 4
llama_model_loader: - kv 28: qwen35.rope.dimension_count u32 = 64
llama_model_loader: - kv 29: tokenizer.ggml.model str = gpt2
llama_model_loader: - kv 30: tokenizer.ggml.pre str = qwen35
llama_model_loader: - kv 31: tokenizer.ggml.tokens arr[str,248320] = ["!", "\"", "#", "$", "%", "&", "'", ...
llama_model_loader: - kv 32: tokenizer.ggml.token_type arr[i32,248320] = [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, ...
llama_model_loader: - kv 33: tokenizer.ggml.merges arr[str,247587] = ["Ġ Ġ", "ĠĠ ĠĠ", "i n", "Ġ t",...
llama_model_loader: - kv 34: tokenizer.ggml.eos_token_id u32 = 248046
llama_model_loader: - kv 35: tokenizer.ggml.padding_token_id u32 = 248044
llama_model_loader: - kv 36: tokenizer.ggml.add_bos_token bool = false
llama_model_loader: - kv 37: tokenizer.chat_template str = {%- set image_count = namespace(value...
llama_model_loader: - kv 38: quantize.imatrix.file str = /models_out/Qwen3.5-27B-GGUF/Qwen_Qwe...
llama_model_loader: - kv 39: quantize.imatrix.dataset str = /training_dir/calibration_datav5.txt
llama_model_loader: - kv 40: quantize.imatrix.entries_count u32 = 496
llama_model_loader: - kv 41: quantize.imatrix.chunks_count u32 = 802
llama_model_loader: - kv 42: general.quantization_version u32 = 2
llama_model_loader: - kv 43: general.file_type u32 = 43
llama_model_loader: - type f32: 353 tensors
llama_model_loader: - type q6_K: 1 tensors
llama_model_loader: - type tq3_1s: 497 tensors
print_info: file format = GGUF V3 (latest)
print_info: file type = TQ3_1S - 4.0 bpw WHT-rotated 3-bit
print_info: file size = 12.91 GiB (4.12 BPW)
load: 0 unused tokens
load: printing all EOG tokens:
load: - 248044 ('<|endoftext|>')
load: - 248046 ('<|im_end|>')
load: - 248063 ('<|fim_pad|>')
load: - 248064 ('<|repo_name|>')
load: - 248065 ('<|file_sep|>')
load: special tokens cache size = 33
load: token to piece cache size = 1.7581 MB
print_info: arch = qwen35
print_info: vocab_only = 0
print_info: no_alloc = 0
print_info: n_ctx_train = 262144
print_info: n_embd = 5120
print_info: n_embd_inp = 5120
print_info: n_layer = 64
print_info: n_head = 24
print_info: n_head_kv = 4
print_info: n_rot = 64
print_info: n_swa = 0
print_info: is_swa_any = 0
print_info: n_embd_head_k = 256
print_info: n_embd_head_v = 256
print_info: n_gqa = 6
print_info: n_embd_k_gqa = 1024
print_info: n_embd_v_gqa = 1024
print_info: f_norm_eps = 0.0e+00
print_info: f_norm_rms_eps = 1.0e-06
print_info: f_clamp_kqv = 0.0e+00
print_info: f_max_alibi_bias = 0.0e+00
print_info: f_logit_scale = 0.0e+00
print_info: f_attn_scale = 0.0e+00
print_info: n_ff = 17408
print_info: n_expert = 0
print_info: n_expert_used = 0
print_info: n_expert_groups = 0
print_info: n_group_used = 0
print_info: causal attn = 1
print_info: pooling type = -1
print_info: rope type = 40
print_info: rope scaling = linear
print_info: freq_base_train = 10000000.0
print_info: freq_scale_train = 1
print_info: n_ctx_orig_yarn = 262144
print_info: rope_yarn_log_mul = 0.0000
print_info: rope_finetuned = unknown
print_info: mrope sections = [11, 11, 10, 0]
print_info: ssm_d_conv = 4
print_info: ssm_d_inner = 6144
print_info: ssm_d_state = 128
print_info: ssm_dt_rank = 48
print_info: ssm_n_group = 16
print_info: ssm_dt_b_c_rms = 0
print_info: model type = 27B
print_info: model params = 26.90 B
print_info: general.name = Qwen3.5 27B
print_info: vocab type = BPE
print_info: n_vocab = 248320
print_info: n_merges = 247587
print_info: BOS token = 11 ','
print_info: EOS token = 248046 '<|im_end|>'
print_info: EOT token = 248046 '<|im_end|>'
print_info: PAD token = 248044 '<|endoftext|>'
print_info: LF token = 198 'Ċ'
print_info: FIM PRE token = 248060 '<|fim_prefix|>'
print_info: FIM SUF token = 248062 '<|fim_suffix|>'
print_info: FIM MID token = 248061 '<|fim_middle|>'
print_info: FIM PAD token = 248063 '<|fim_pad|>'
print_info: FIM REP token = 248064 '<|repo_name|>'
print_info: FIM SEP token = 248065 '<|file_sep|>'
print_info: EOG token = 248044 '<|endoftext|>'
print_info: EOG token = 248046 '<|im_end|>'
print_info: EOG token = 248063 '<|fim_pad|>'
print_info: EOG token = 248064 '<|repo_name|>'
print_info: EOG token = 248065 '<|file_sep|>'
print_info: max token length = 256
load_tensors: loading model tensors, this can take a while... (mmap = true, direct_io = false)
load_tensors: offloading output layer to GPU
load_tensors: offloading 61 repeating layers to GPU
load_tensors: offloaded 62/65 layers to GPU
load_tensors: CPU_Mapped model buffer size = 1155.04 MiB
load_tensors: CUDA0 model buffer size = 12067.18 MiB
..........................................................................................
common_init_result: added <|endoftext|> logit bias = -inf
common_init_result: added <|im_end|> logit bias = -inf
common_init_result: added <|fim_pad|> logit bias = -inf
common_init_result: added <|repo_name|> logit bias = -inf
common_init_result: added <|file_sep|> logit bias = -inf
llama_context: constructing llama_context
llama_context: n_seq_max = 4
llama_context: n_ctx = 32768
llama_context: n_ctx_seq = 32768
llama_context: n_batch = 2048
llama_context: n_ubatch = 512
llama_context: causal_attn = 1
llama_context: flash_attn = enabled
llama_context: kv_unified = true
llama_context: freq_base = 10000000.0
llama_context: freq_scale = 1
llama_context: n_ctx_seq (32768) < n_ctx_train (262144) -- the full capacity of the model will not be utilized
llama_context: CUDA_Host output buffer size = 3.79 MiB
llama_kv_cache: CUDA0 KV buffer size = 744.00 MiB
llama_kv_cache: size = 744.00 MiB ( 32768 cells, 16 layers, 4/1 seqs), K (q8_0): 544.00 MiB, V (turbo3): 200.00 MiB
llama_kv_cache: upstream attention rotation disabled (TurboQuant uses kernel-level WHT)
llama_kv_cache: attn_rot_k = 0
llama_kv_cache: attn_rot_v = 0
llama_memory_recurrent: CPU RS buffer size = 37.41 MiB
llama_memory_recurrent: CUDA0 RS buffer size = 561.09 MiB
llama_memory_recurrent: size = 598.50 MiB ( 4 cells, 64 layers, 4 seqs), R (f32): 22.50 MiB, S (f32): 576.00 MiB
sched_reserve: reserving ...
sched_reserve: resolving fused Gated Delta Net support:
sched_reserve: fused Gated Delta Net (autoregressive) enabled
sched_reserve: layer 0 is assigned to device CPU but the fused Gated Delta Net tensor is assigned to device CUDA0 (usually due to missing support)
sched_reserve: fused Gated Delta Net (chunked) not supported, set to disabled
sched_reserve: CUDA0 compute buffer size = 495.00 MiB
sched_reserve: CUDA_Host compute buffer size = 94.49 MiB
sched_reserve: graph nodes = 8329 (with bs=512), 3769 (with bs=1)
sched_reserve: graph splits = 53 (with bs=512), 8 (with bs=1)
sched_reserve: reserve took 91.39 ms, sched copies = 1
common_init_from_params: warming up the model with an empty run - please wait ... (--no-warmup to disable)
srv load_model: initializing slots, n_slots = 4
common_speculative_is_compat: the target context does not support partial sequence removal
srv load_model: speculative decoding not supported by this context
slot load_model: id 0 | task -1 | new slot, n_ctx = 32768
slot load_model: id 1 | task -1 | new slot, n_ctx = 32768
slot load_model: id 2 | task -1 | new slot, n_ctx = 32768
slot load_model: id 3 | task -1 | new slot, n_ctx = 32768
srv load_model: prompt cache is enabled, size limit: 8192 MiB
srv load_model: use `--cache-ram 0` to disable the prompt cache
srv load_model: for more info see https://github.com/ggml-org/llama.cpp/pull/16391
srv init: init: idle slots will be saved to prompt cache and cleared upon starting a new task
init: chat template, example_format: '<|im_start|>systemWe run the query again:
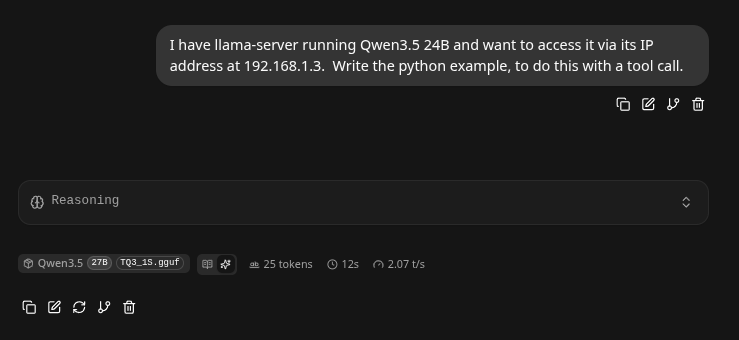
- We have increased temperature to 0.9 and this has significantly slowed the thinking portion of the Qwen...
- Examining the nvidia-smi shows the work is still fully on the GPU..
c@dragon-192-168-1-3:~$ nvidia-smi
Sun Apr 5 06:05:51 2026
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 580.126.09 Driver Version: 580.126.09 CUDA Version: 13.0 |
+-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA GeForce RTX 4080 Off | 00000000:07:00.0 On | N/A |
| 0% 39C P2 75W / 340W | 14483MiB / 16376MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| 0 N/A N/A 4195 G /usr/lib/xorg/Xorg 36MiB |
| 0 N/A N/A 123266 C /usr/bin/llama-server 14400MiB |
+-----------------------------------------------------------------------------------------+Here is the result - 2.0 Token/s it took about 9 minutes to produce a very similar answer:
Here's a complete Python example to connect to your llama-server running Qwen3.5 24B at IP 192.168.1.3 and perform a tool call using the server's API:
Prerequisites
Install required packages:
pip install requests
Ensure llama-server is running and accepting connections on http://192.168.1.3:8080 (or your configured port).
Python Example
import json
import requests
from typing import List, Dict, Any
# Llama-server endpoint
API_URL = "http://192.168.1.3:8080"
# Define tool schema (as per JSON Schema for tools)
tools = [{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get weather information for a city",
"parameters": {
"type": "object",
"properties": {
"city": {
"type": "string",
"description": "The city name"
}
},
"required": ["city"]
}
}
}]
# Mock tool handler
def execute_tool(name: str, arguments: Dict[str, Any]) -> str:
if name == "get_weather":
city = arguments.get("city", "Unknown")
return f"Weather in {city}: Sunny, 25°C"
return f"Unknown tool: {name}"
# Call Llama-server API
def call_llama_api(prompt: str, tools: List[Dict] = None, history: List = None) -> Dict:
headers = {"Content-Type": "application/json"}
data = {
"prompt": prompt,
"options": {
"temperature": 0.7,
"top_p": 0.9,
"num_predict": 256
},
"tools": tools,
"messages": history if history else []
}
response = requests.post(f"{API_URL}/completion", json=data, headers=headers)
if response.status_code == 200:
return response.json()
else:
raise Exception(f"API error: {response.status_code} - {response.text}")
# Tool call handling loop
def chat_with_tools(user_input: str):
messages = [{"role": "user", "content": user_input}]
llm_response = call_llama_api("", tools, [{"role": "user", "content": user_input}])
# If the model returns a tool call
if "tool_calls" in llm_response:
for tool_call in llm_response["tool_calls"]:
name = tool_call["name"]
args = json.loads(tool_call["arguments"])
result = execute_tool(name, args)
# Add tool result and prompt again
messages.append({"role": "assistant", "content": "", "tool_calls": [tool_call]})
messages.append({"role": "tool", "name": name, "content": result})
llm_response = call_llama_api("", tools, messages)
# Extract and print final response
content = llm_response.get("content", "No response.")
print(content)
# Example usage
if __name__ == "__main__":
chat_with_tools("What's the weather in London?")
Notes
- Port: Adjust
8080if your server uses a different port. - Tool Handling: The
execute_toolfunction must be expanded for real use-cases. - Authentication: Add headers (e.g.,
Authorization) if your server requires it. - Streaming: For long responses, consider using
stream=Trueinrequests.post.
This setup lets you use Qwen3.5 24B via llama-server to invoke tools like get_weather dynamically, following best practices for function calling in Python.
User note: Context Length dramatically slowed when we went to 32768. Even though the GPU showed an additional 2GB of unused VRAM inside nvidia-smi we know that we can expect the following:
- Break your coding task up into small steps.
Next up Part 3 where we realize we can save about $900/month in LLM costs if we can figure out how to put our LLM to 24 hr/day work.
thinkmeltprotonmail.com
