LM Studio 0.3.30 (Build 1) Awesome! Run LLM's At Your House Without Being A Coder. A Basic Review
LM Studio 0.3.30 (Build 1) Awesome! Run LLM's At Your House Without Being A Coder. A Basic Review


- This is a very friendly Linux / Windows based large language model Front-end / handler that can both take away the meaty potatoes of running an LLM and bring it to the masses.
- It is available at LM Studio


- It should be noted you can get some impressive results without having a $10,000 GPU cluster, many models can offer some good performance on consumer hardware.
- All LLM tests were run on a basic 'consumer grade' generic CPU/ GPU namely a R9 Ryzen 3700x 12-core 24 thread CPU with 2 - 3060ti cards and populated with 128 GB of RAM. The memory bandwidth of the system was noted as follows. The 3060ti's performed at 220GB/s internally, the RAM performed at 8/16 GB/s and the PCIe bus performed at 25 GB/s on one slot, and 8 GB/s on a second. An entire article was created here about it all, and why PCIe memory bandwidth is your #1 issue that can limit the performance of an LLM. So this is not in any fashion an 'exotic' build - outside having a second graphics card, and an unusual amount of RAM.
- Running a larger LLM in RAM is not feasible. We have tried.. It is often only 0.5 tokens a second. A token is about 1.3 words, so we are talking super slow production to run the larger LLM's in RAM only. However if you get very very small LLM's they can run very quickly with almost no GPU's at all (0.3 GB)
- LLM's are like people. Some are super smrt, some .. not so much. Explore them and know your LLM. You can get chatty ones that really verbauge, but don't seem to know a lot and only need a small amount of hardware to run. Ask them super basic questions and they will engage you. Typically though you can get powerful assistants that will assist (and usually) out perform you at about the 70B (70 Billion Parameter) mark - seriously. 20B is very good too, but 70B sized models like the Llama-Compute are work horses. It has been my experience that I can have it assisting me quickly all day, on pretty much any topic you can throw at it. So to keep costs down - many people getting into LLM's often marry 2 Nvidia 3090-ti Video cards due to their 24 GB / ram each. As long as they have a motherboard with 2 PCIe 4.0 x 16 slots it will run well, and they can 'bump' themselves up to the 70B work horse LLM's by using the 4-bit quaint modes. 4-bit quaint mode is just a highly compressed version of tokenization. There is about a 10-12% loss in performance to do this, and that is acceptable for many. Yes that is a fair bit of change quickly approaching $4,000 - $5,000 but a developer can honestly expect 50-200% increases in their own productivity, and there are zero subscriptions to pay to get it. And you own it. If you are a programmer running 1000's of API queries the token costs add up very quickly so why not try to just run it yourself?
- If you need a SOTA (State of the Art) coding or very large LLM inference, it makes sense to either just buy access at openrouter.ai or get a professional Grok 4 etc subscription.
Here is a quick reference chart of several motherboards as researched by Grok 4 that will support at a bargain price PCIe 4.0 x 16 with 2 or more slots:
"The motherboards that meet the criteria of having 4 or more PCIe 4.0 x16 slots are primarily from high-end desktop (HEDT) platforms, as standard consumer chipsets do not provide sufficient PCIe lanes to support this configuration. Based on available data from reliable sources, the following models are identified. Note that prices are approximate current values as of the query date and may vary by retailer and availability; they are drawn from recent listings on sites such as Newegg, Amazon, and eBay. Only models with confirmed pricing and specifications are included. The table is sorted by price in ascending order."
| Model | Chipset | Socket | Number of PCIe 4.0 x16 Slots | Slot Configuration Notes | Price (USD) |
|---|---|---|---|---|---|
| GIGABYTE TRX40 AORUS PRO WIFI | TRX40 | sTRX4 | 4 | Supports x16/x8/x16/x8 mode when all populated | 265 |
| ASUS ROG Strix TRX40-E Gaming | TRX40 | sTRX4 | 4 | Supports up to triple x16; fourth slot may bifurcate to x8 | 291 |
| ASUS Prime TRX40-PRO S | TRX40 | sTRX4 | 4 | Supports multi-GPU configurations with PCIe 4.0 | 542 |
| ASUS Pro WS WRX80E-SAGE SE WIFI | WRX80 | sWRX8 | 7 | Full support for multiple GPUs with 128 PCIe lanes available | 674 |
| GIGABYTE WRX80-SU8-IPMI | WRX80 | sWRX8 | 7 | Designed for workstations; supports multi-GPU setups | 839 |
These models are compatible with AMD Ryzen Threadripper processors (3000 series for TRX40 and PRO 5000 series for WRX80). If you require models from Intel platforms (such as W790, which support PCIe 5.0 slots backward-compatible with PCIe 4.0 devices) or updated pricing, additional details can be provided upon request.
- LLM model downloads are large. One model can easily be 25 GB of data, so have a decent amount of free space on your hard drive for it.
- LLMs can be intimidating, what is very nice about this software is you can run a large number of LLM's without needing to be a full API coder! Nice!
- We pulled and successfully and easily ran it over ssh -Y remotely to a server:
ssh -Y user@192.168.1.3It will appear as follows showing it to you up and running.
Getting and pulling a LLM.
- The software will automatically look at your hardware and set some 'bumpers' of LLMs that can or cannot run respectably on your computer. This is nice because left to your own vices you might spend two hours on your own to setup and run a monster LLM only to find out its killing your hardware, and stutters out some amazing stuff - but only at 0.5 tokens per second. (I already did all that getting 0.5 tps - tokens per second by trying to 'ram run' a 70b model..)
The left side has 4 options: chats / developers / my models / discover. We will cover discover first because it is the first thing you do to pull a model.
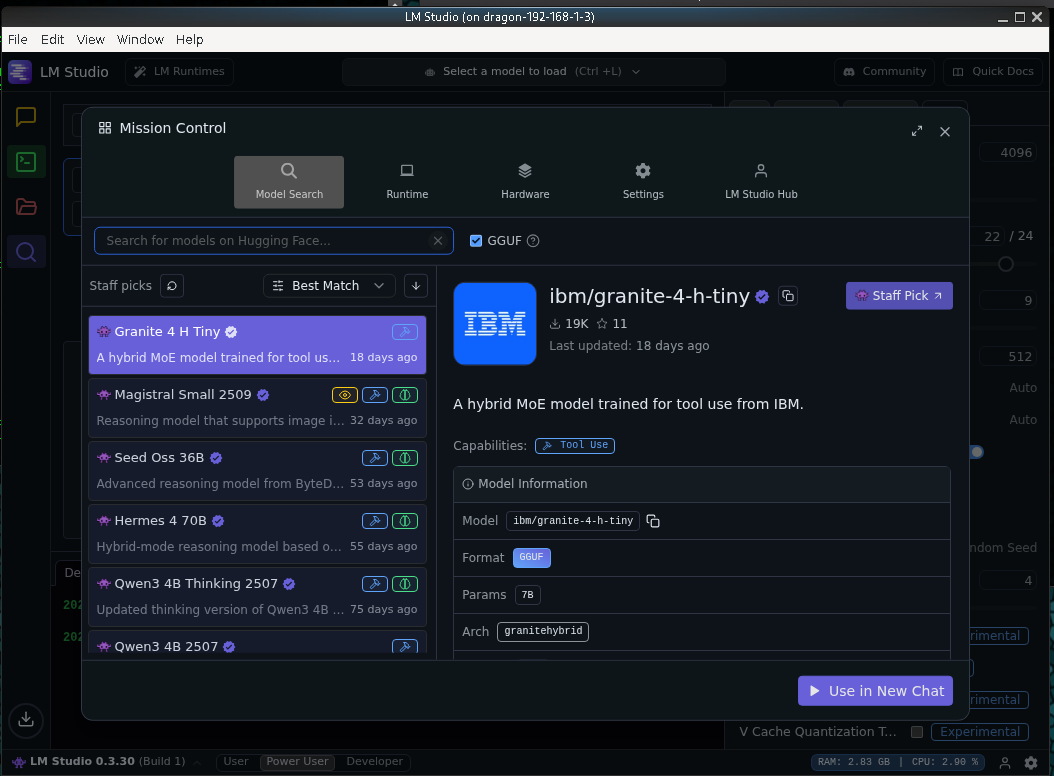
What is really nice is it will show you as you inspect each LLM if it can fully offload to your GPU. This is a big plus - because as discovered in the following article, anytime you have a memory bandwidth choke point it can severely hamper the performance of your LLM.
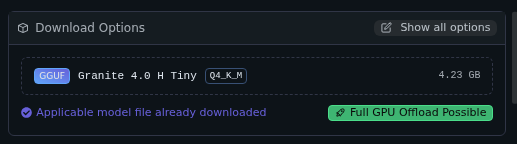
We can see 'Full GPU Offload Possible' These will run fast.
Chats: Will give you a basic chat window where you can interact with your LLM. It will show its 'thinking' window as it processes your query,
- Developer: On the left side will be the API interface points, and the right side will be your settings. This is powerful because you can get an idea of all the options available for each AI without needing to read hours of documentation as there are a lot of 'under-the-hood' settings they do not show the public.
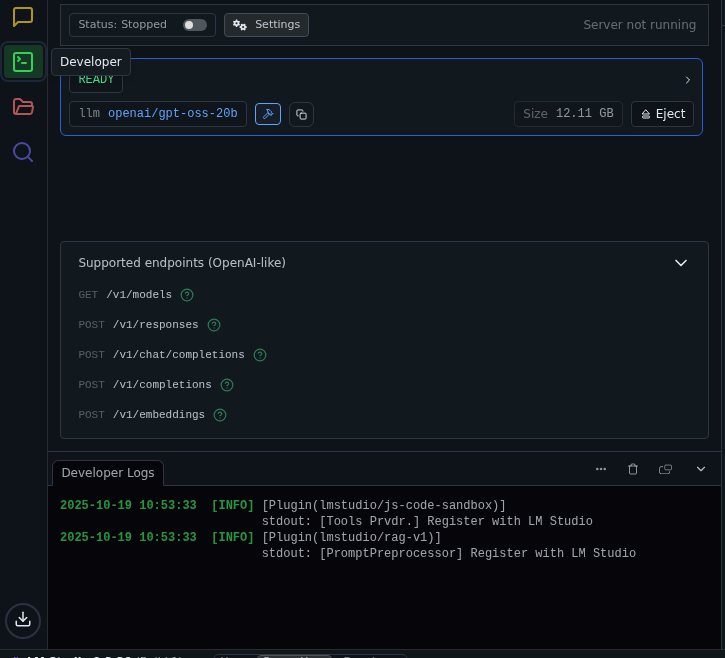
To start we will pick a super-small 1.1B model 'Tiny-Chat' or TinyLlama-1.1B-Chat-v1.0-GGUF
- As it is downloading you can also select the 'drop-down' which will show you all the available models.
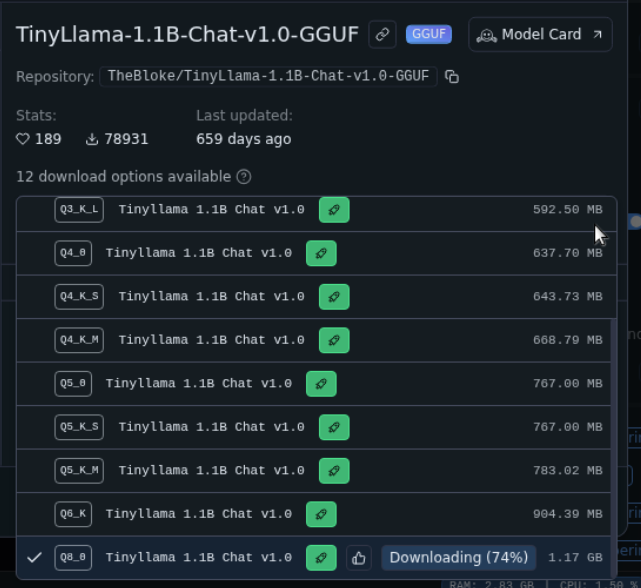
Once it is downloaded it will automatically let you open it, or you can call for it from the top button.

How are you today?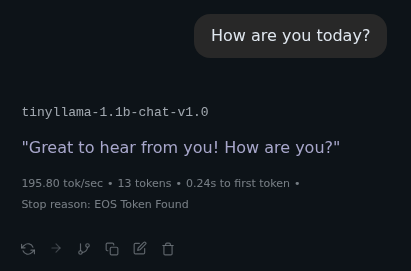
- 195.8 Tokens per second, so its FAST.
Write me a program in C to load, save, and store and array of numbers.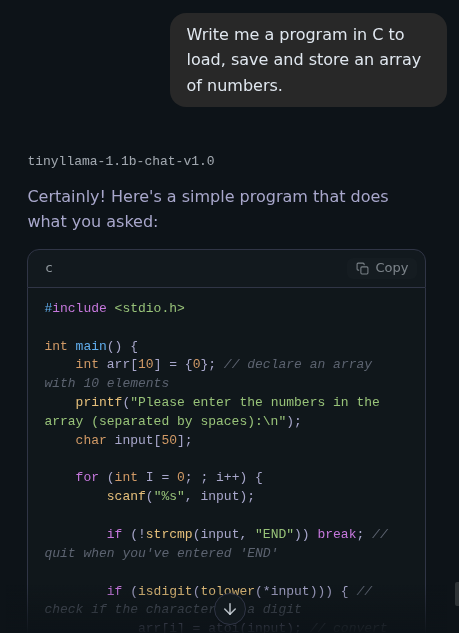
Write me a regex function to select everything between two html blocksWe are getting humbled by this 1.1b model, anyways it spit out the following:
import re
def extract_between_tags(html):
matches = []
# Find all `<th>` and </th>` tags in the HTML
for match in re.finditer('<th[^>]*>', html):
matches.append((match, 'th'))
for match, tag in matches:
# Get the content between the matched tags
content = html[tag[1]:match.end()]
matches.append((content, tag))
return matches
Once you are done - simply hit the 'eject' button like the old cassette tapes it will shut off your LLM.
On the right side of the model are its settings, this is handy because it can give you lots of options as to how much 'imagination or temperature' etc that it offers.
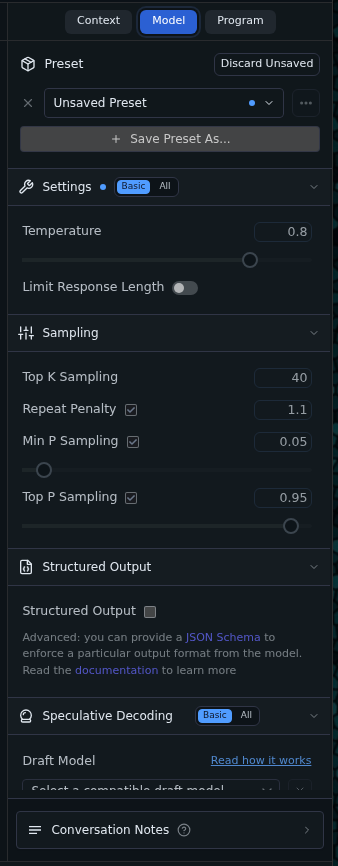
It should be noted before you read the next part you will quickly see why a lot of it is mostly hidden people, but it is there!
- Top K Sampling: Top-K sampling is a probabilistic decoding strategy employed in large language models (LLMs), including the TinyLlama model, to generate text by selecting the next token from a restricted subset of the most probable candidates. This approach mitigates the risk of producing low-quality or irrelevant outputs by limiting the model's choices during autoregressive generation, thereby balancing determinism and diversity in the resulting text.
- Repeat Penalty: The repeat penalty, commonly known as the repetition penalty, is a configurable parameter in many large language models (LLMs) designed to reduce the likelihood of generating repetitive or redundant text during inference. This option addresses a common issue in autoregressive models, where the system might otherwise produce monotonous outputs by favoring previously used tokens.
- Min-P sampling, is an advanced probabilistic decoding strategy utilized in large language models (LLMs), including the TinyLlama model, to enhance text generation by dynamically adjusting the token selection process based on a minimum probability threshold. Unlike traditional methods such as top-K or top-P sampling, which rely on fixed counts or cumulative probability cutoffs, Min-P sampling focuses on ensuring that each selected token exceeds a specified minimum probability (denoted as P_min), thereby promoting diversity while maintaining output coherence.
- Top-P sampling, also known as nucleus sampling, is a probabilistic decoding technique employed in large language models (LLMs), including the TinyLlama model, to generate text by selecting tokens from a dynamic subset defined by a cumulative probability mass. This method improves upon fixed-size approaches like top-K sampling by adapting the number of considered tokens based on their cumulative probability, thereby enhancing both diversity and coherence in the output.
Remote Accessing your LM Studio.
- What is also very nice is (even without root) LM Studio will automatically provide an API access for whatever LLM is running at that time, let's go over the basics of getting it to work. Start the LLM of your choice up:

Under the settings you can set 'Serve on Local Network'
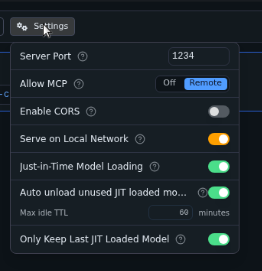
If you call the endpoint you actually won't get much as in:
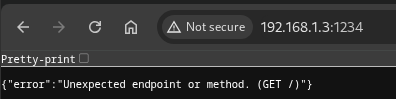
However you can easily access it as follows with the following example:
wget http://192.168.1.3:1234/v1/models
It will save to file a json which you can inspect as:
{
"data": [
{
"id": "tinyllama-1.1b-chat-v1.0",
"object": "model",
"owned_by": "organization_owner"
},
{
"id": "qwen/qwen3-4b",
"object": "model",
"owned_by": "organization_owner"
},
{
"id": "ibm/granite-4-h-tiny",
"object": "model",
"owned_by": "organization_owner"
},
{
"id": "qwen/qwen3-coder-30b",
"object": "model",
"owned_by": "organization_owner"
},
{
"id": "openai/gpt-oss-20b",
"object": "model",
"owned_by": "organization_owner"
},
{
"id": "text-embedding-nomic-embed-text-v1.5",
"object": "model",
"owned_by": "organization_owner"
}
],
"object": "list"
}What is also very powerful is it has a built-in API Query Builder simply hit the 'curl' button by the respective LLM. It will automatically populate the clipboard with an example query build.
curl http://localhost:1234/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "tinyllama-1.1b-chat-v1.0",
"messages": [
{ "role": "system", "content": "Always answer in rhymes. Today is Thursday" },
{ "role": "user", "content": "What day is it today?" }
],
"temperature": 0.7,
"max_tokens": -1,
"stream": false
}'
curl will reply back in the same query submission with a answer json:
{
"id": "chatcmpl-at2s2in18xwiqe503hvpdh",
"object": "chat.completion",
"created": 1760915456,
"model": "tinyllama-1.1b-chat-v1.0",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "It's Thursday.",
"tool_calls": []
},
"logprobs": null,
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 41,
"completion_tokens": 8,
"total_tokens": 49
},
"stats": {},
"system_fingerprint": "tinyllama-1.1b-chat-v1.0"
Summary: Document your stuff. Or if you are like many developers that HATE documenting your stuff make 'junior' do it - at least your local LLM. That's very powerful.
Prediction: In five years AI will be on your TV.
