LLM Image Generation on Dual 3060ti Video Cards Using stability_ai.
With Stability_ai we are able to generate beautiful images at about 18 seconds / shot using 2 -3060ti cards in a balanced load.


Start here:
- First time running will take about 15 minutes it pulls about 40 GB+ of data for the LLM.
- prompt = "A majestic lion jumping from a big stone at night"

Next you will clearly want to get some pycharm going so:
 thinkmeltprotonmail.com
thinkmeltprotonmail.com
The single GPU configuration will look as:
import os
import torch
from diffusers import DiffusionPipeline, AutoencoderKL
import datetime
import xformers
# Set environment variable for better memory management (updated for deprecation)
os.environ["PYTORCH_ALLOC_CONF"] = "expandable_segments:True,max_split_size_mb:128"
# Load custom FP16-compatible VAE
vae = AutoencoderKL.from_pretrained(
"madebyollin/sdxl-vae-fp16-fix",
torch_dtype=torch.float16,
use_safetensors=True
)
# Load both base & refiner with device_map for multi-GPU distribution and max_memory limit
max_memory = {0: "8GiB", 1: "8GiB"}
base = DiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0",
vae=vae,
torch_dtype=torch.float16,
variant="fp16",
use_safetensors=True,
device_map="balanced",
max_memory=max_memory
)
base.reset_device_map()
base.enable_sequential_cpu_offload()
base.enable_attention_slicing()
base.enable_vae_slicing()
base.enable_vae_tiling()
base.enable_xformers_memory_efficient_attention() # Comment out if xFormers is not installed
refiner = DiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-refiner-1.0",
text_encoder_2=base.text_encoder_2,
vae=base.vae,
torch_dtype=torch.float16,
use_safetensors=True,
variant="fp16",
device_map="balanced",
max_memory=max_memory
)
refiner.reset_device_map()
refiner.enable_sequential_cpu_offload()
refiner.enable_attention_slicing()
refiner.enable_vae_slicing()
refiner.enable_vae_tiling()
refiner.enable_xformers_memory_efficient_attention() # Comment out if xFormers is not installed
# Define how many steps and what % of steps to be run on each experts (80/20) here
n_steps = 40
high_noise_frac = 0.8
prompt = "A majestic lion jumping from a big stone at night"
# Clear cache before running
torch.cuda.empty_cache()
# Run base
image = base(
prompt=prompt,
num_inference_steps=n_steps,
denoising_end=high_noise_frac,
output_type="latent",
height=768,
width=768,
).images
# Clear cache before refiner
torch.cuda.empty_cache()
# Run refiner
print(f"Starting image generations.. ")
for x in range(10):
rnow = datetime.datetime.now()
image = refiner(
prompt=prompt,
num_inference_steps=n_steps,
denoising_start=high_noise_frac,
image=image,
height=768,
width=125,
).images[0]
try:
image_name = f'x_{x:02d}.png'
image.save(image_name)
rthen = datetime.datetime.now()
delta = rthen - rnow
print(f"Created image {image_name} elasped time: {delta}")
except Exception as e:
print(f"Error: {e}")Note: There is an error in this code in that images 2+ will be the same, here is some modified code that will utilize two GPU's and rebuild the seed each time, to make each image took approximately 18 seconds:
import os
import torch
from diffusers import DiffusionPipeline, AutoencoderKL
from transformers import CLIPTextModelWithProjection
import datetime
import xformers
import random
# Set environment variable for better memory management (updated for deprecation)
os.environ["PYTORCH_ALLOC_CONF"] = "expandable_segments:True,max_split_size_mb:128"
# Load custom FP16-compatible VAE for base
vae_base = AutoencoderKL.from_pretrained(
"madebyollin/sdxl-vae-fp16-fix",
torch_dtype=torch.float16,
use_safetensors=True
)
# Load custom FP16-compatible VAE for refiner (separate instance)
vae_refiner = AutoencoderKL.from_pretrained(
"madebyollin/sdxl-vae-fp16-fix",
torch_dtype=torch.float16,
use_safetensors=True
)
# Load base pipeline
base = DiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0",
vae=vae_base,
torch_dtype=torch.float16,
variant="fp16",
use_safetensors=True
)
base.enable_model_cpu_offload(gpu_id=0)
base.enable_attention_slicing()
base.enable_vae_slicing()
base.enable_vae_tiling()
base.enable_xformers_memory_efficient_attention() # Comment out if xFormers is not installed
# Load separate text_encoder_2 for refiner
text_encoder_2 = CLIPTextModelWithProjection.from_pretrained(
"stabilityai/stable-diffusion-xl-refiner-1.0",
subfolder="text_encoder_2",
torch_dtype=torch.float16,
use_safetensors=True,
variant="fp16"
)
# Load refiner pipeline with separate text_encoder_2 and vae
refiner = DiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-refiner-1.0",
text_encoder_2=text_encoder_2,
vae=vae_refiner,
torch_dtype=torch.float16,
use_safetensors=True,
variant="fp16"
)
refiner.enable_model_cpu_offload(gpu_id=1)
refiner.enable_attention_slicing()
refiner.enable_vae_slicing()
refiner.enable_vae_tiling()
refiner.enable_xformers_memory_efficient_attention() # Comment out if xFormers is not installed
# Define how many steps and what % of steps to be run on each experts (80/20) here
n_steps = 40
high_noise_frac = 0.8
prompt = "A majestic lion jumping from a big stone at night"
refiner_device = torch.device("cuda:1")
# Run refiner in loop with different seeds for variation
print(f"Starting image generations.. ")
for x in range(10):
rnow = datetime.datetime.now()
# Clear cache before running
torch.cuda.empty_cache()
# Generate a random seed for this iteration
seed = random.randint(0, 2**32 - 1)
# Run base with seed
generator_base = torch.Generator(device="cuda:0").manual_seed(seed)
image_latents = base(
prompt=prompt,
num_inference_steps=n_steps,
denoising_end=high_noise_frac,
output_type="latent",
height=768,
width=768,
generator=generator_base,
).images
# Move latent to CPU first, then to refiner's device to avoid any device mismatch
latent_image = image_latents[0].cpu().to(refiner_device)
# Clear cache before refiner
torch.cuda.empty_cache()
# Run refiner with same seed for reproducibility
generator_refiner = torch.Generator(device=refiner_device).manual_seed(seed)
image = refiner(
prompt=prompt,
num_inference_steps=n_steps,
denoising_start=high_noise_frac,
image=latent_image.unsqueeze(0), # Ensure it's a batch of 1
height=768,
width=768,
generator=generator_refiner,
).images[0]
try:
image_name = f'x_{x:02d}.png'
image.save(image_name)
rthen = datetime.datetime.now()
delta = rthen - rnow
print(f"Created image {image_name} elasped time: {delta}")
except Exception as e:
print(f"Error: {e}")
Outputs run as:
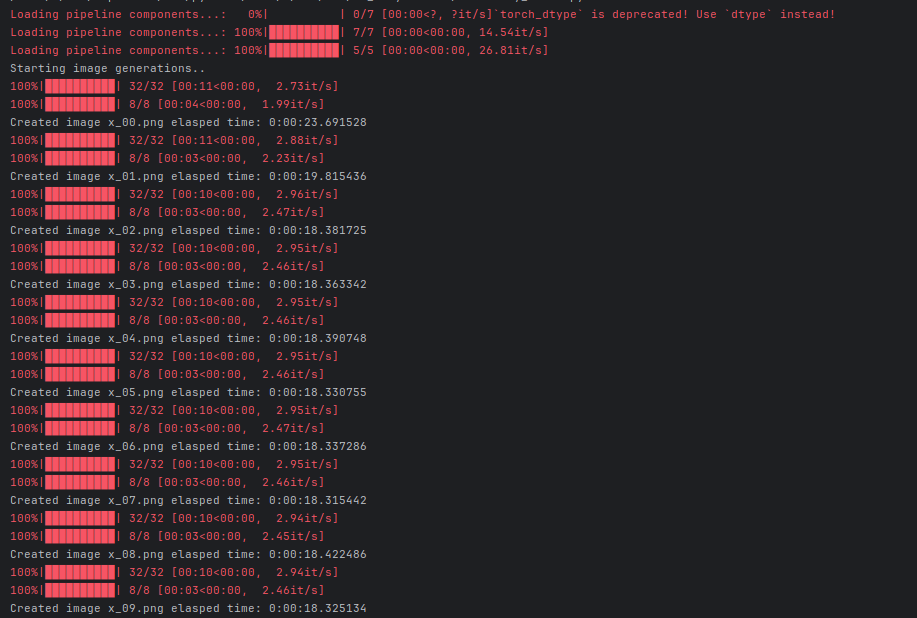



Etc..
At this point the cost to generate these beautiful images is effectively 18 seconds of power for about 400w load (if you add the GPU + CPU). So roughly about 33 images / penny. Very good.
Note: Scaling did not work at this time as in banner generation of say 160 x 768 type images, and is currently an object of study...
