Jail Break: Running the WizardLM-7B-Uncensored LLM with Underrated Equipment
Jail Break: Running the WizardLM-7B-Uncensored LLM with Underrated Equipment


- Why do this? The idea is not nefarious, it is simply that you want full access to all the features of the LLM.
- There are currently very few Uncensored LLMs (~3)
- We are not concerned about very slow tokens per second - so we are also looking at how we can force much of this LLM to run using the CPU ram.
- How is this going to work out - and is this all tripe junk - well we will tell you!
We built this guide off Uncensored Models:
Uncensored Models
I am publishing this because many people are asking me how I did it, so I will explain.https://huggingface.co/ehartford/WizardLM-30B-Uncensoredhttps://huggingface.co/ehartford/WizardLM-13B-Uncensoredhttps://huggingface.co/ehartford/WizardLM-7B-Unc...
 Eric Hartford
Eric Hartford
Install Script:
# Full Linux Installation Instructions for WizardLM-7B-Uncensored (Assuming Ubuntu 22.04 or Later)
# Step 1: Update system packages and install basic dependencies
sudo apt update && sudo apt upgrade -y
sudo apt install -y python3 python3-pip git wget
# Step 2: Install NVIDIA CUDA Toolkit (required for partial GPU offloading; skip if running purely on CPU, but note that partial offload assumes GPU availability)
# Download and install CUDA from the official NVIDIA website. Select options for your system (e.g., Linux > x86_64 > Ubuntu > 22.04 > deb (local)).
wget https://developer.download.nvidia.com/compute/cuda/12.1.0/local_installers/cuda_12.1.0_530.30.02_linux.run
sudo sh cuda_12.1.0_530.30.02_linux.run --toolkit --silent --override
# Add CUDA to PATH (add to ~/.bashrc if needed)
export PATH=/usr/local/cuda-12.1/bin${PATH:+:${PATH}}
export LD_LIBRARY_PATH=/usr/local/cuda-12.1/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}
# Verify installation
nvcc --version
# Step 3: Install PyTorch with CUDA support (for GPU acceleration)
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
# Step 4: Install Hugging Face Transformers and Accelerate libraries
pip install transformers accelerateAnd the testing script:
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
# Load tokenizer and model with device mapping for automatic placement
# Assuming a 7B model in float16 (~14 GiB total), set max_memory to allocate approximately 20% (~3 GiB) to GPU (device 0) and 80% to CPU RAM
# Adjust values based on your system's available memory; ensure GPU has at least 3 GiB free and CPU has sufficient RAM
tokenizer = AutoTokenizer.from_pretrained("ehartford/WizardLM-7B-Uncensored")
model = AutoModelForCausalLM.from_pretrained(
"ehartford/WizardLM-7B-Uncensored",
device_map="auto",
torch_dtype=torch.float16,
max_memory={0: "3GiB", "cpu": "32GiB"}
)
# Running example: Generate text from a prompt
prompt = "The capital of France is"
inputs = tokenizer(prompt, return_tensors="pt").to(model.device) # Move inputs to the primary device
outputs = model.generate(**inputs, max_new_tokens=50, do_sample=True, top_k=50, top_p=0.95)
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(generated_text)- When this is run it will may show nothing for a long time as it downloads the various models but you will see your machine pulling alot:
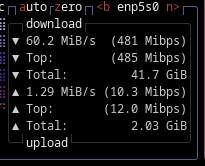
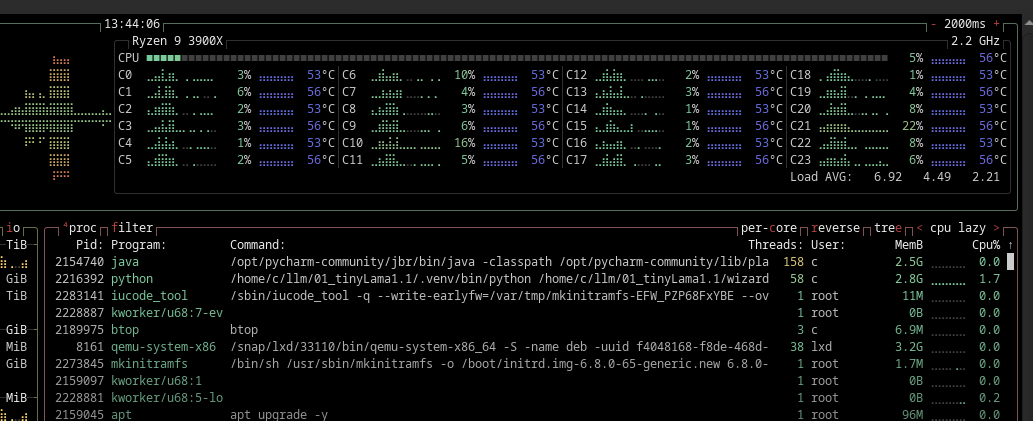
It should be noted there was some serious compute going on for this - just for its setup:
- It was problematic in that the drivers messed up, one must confirm that they have working nvidia-drivers for all of these:
nvidia-smi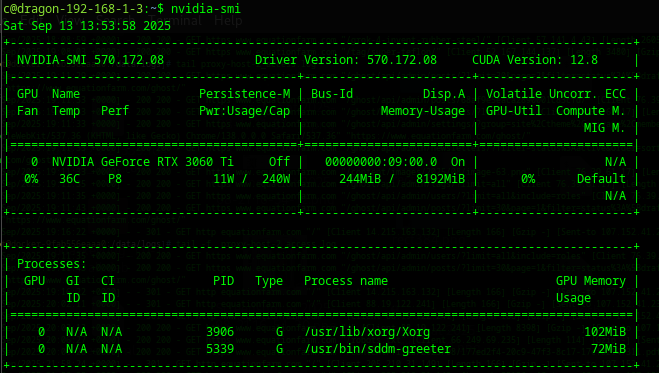
- It is also really recommended to use pycharm, it just manages your stuff, a good guide on installing it is here:
Pycharm Community Fast Install with Install bash Script.
Pycharm Community Fast Install with Install bash Script.
 thinkmeltprotonmail.com
thinkmeltprotonmail.com
- Please note it was found that virtual environments get huge fast if you create one for each test LLM. To remedy this we shared our venv across multiple SLMs...
Some parameters are on the meta device because they were offloaded to the cpu.- Load time was approximately about 10-15 seconds but the run time was very fast
- Uncensored prompts? We were getting a tiny bit of about 1 t/s (token/second)
Iteration 1 took 54.4489 seconds. Token Count: 50
You are an angry bear. Why do you work there?
A new study has found that the majority of people are not happy with their jobs, with many feeling unfulfilled, undervalued, and disengaged from their work.
The study, conducted by the University of Warwick in- Offtopic. This LLM strayed off topic very heavily. That became it's own subject of research.
- The LLM did not contain expletives in it's vocabulary, it would require prompting into either the role or the user.
