higgs-audio Part 1: Roll Your Own Audio Books. Run This LLM on a 1660ti 6 GB Video Card on a Laptop - Actually... no.
In this guide we download, run and study the higgs-audio LLM, trying on a 1660ti Laptop. We eventually get it to work. But it's slow! We then modifiy the generation.py to run on dual 3060ti on a R9.


- Full disclosure - even though I worked for about 1/2 day on this - I did not get this LLM to work under all kinds of settings. Just use it as a reference.
We are going to be looking at a higgs-audio github repository from:
 boson-ai
boson-aiIf you do not have git installed;
sudo apt install git -yOnce you have your git installed, we can pull this repository:
git clone https://github.com/boson-ai/higgs-audio.gitWe will make an environment for this, and activate it:
cd higgs-audio
python3 -m venv venv
cd venv/bin
source activateIf you have errors on the following command:
pip install -r requirements.txtThen migrate into the ./venv/bin/ and do this instead:
./python3 -m pip install ../../requirements.txt- This is explicitly forcing the local python from the venv to call and install the 'requirements.txt' from 2 directories above it.
- It is a BIG install aka torch is 899 MB alone! There are another GB at least of files, maybe get a coffee..

Because doing all this from the command line is just messy lets bring in a free Pycharm Community, a full-free IDE - the rest of this guide will work from inside Pycharm:
 thinkmeltprotonmail.com
thinkmeltprotonmail.com
- If you have a remote server you can pull Pycharm and it will work really well over a ssh with simply:
ssh -Y yourid@yourserver
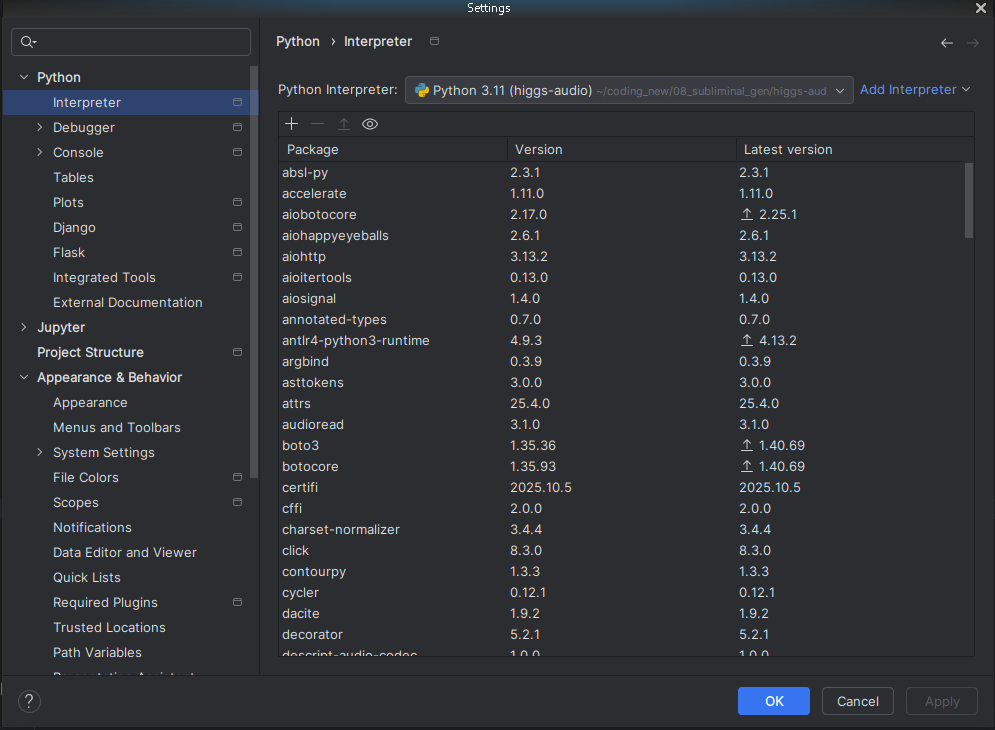
pycharmUnder your settings you can set your python interpretator as:
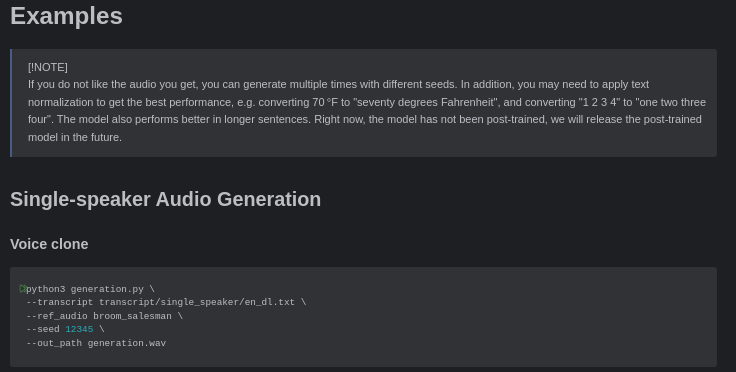
If you open your README.md inside your examples it will show you how to run it as in:
So all we do is copy the options to the inside of the run enviroment for generate.py as in:
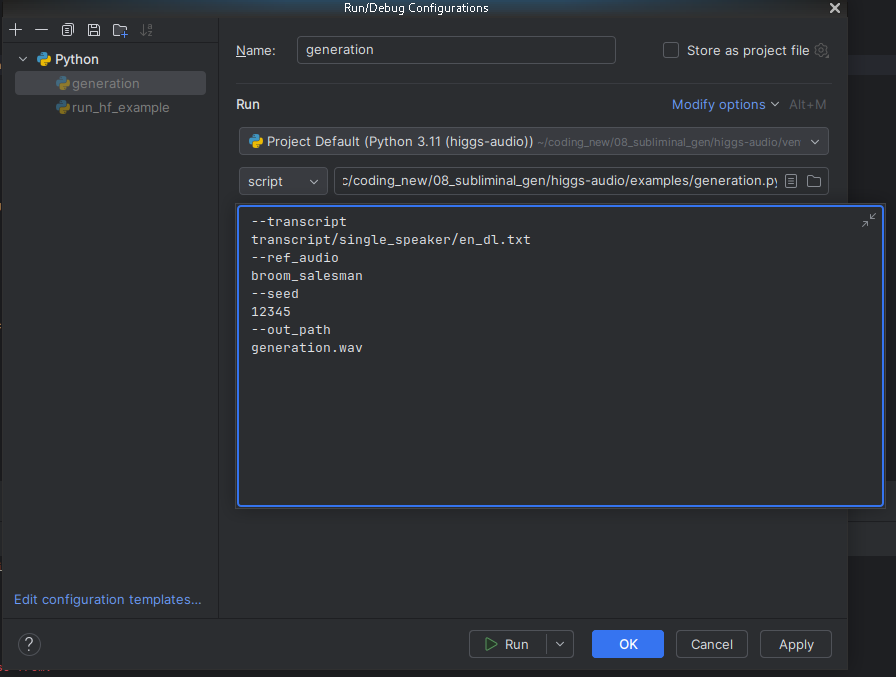
--transcript transcript/single_speaker/en_dl.txt
--ref_audio broom_salesman
--seed 12345
--out_path generation.wav- NOTE - Running LLMs is not always the most trivial thing you want at least a higher-end gaming rig, these things need compute! On a 8-core 16-thread laptop just installing and pre-walking the software before running generator.py was 10 minutes of waiting.
First time you run an LLM is ALWAYS a significant download as in:
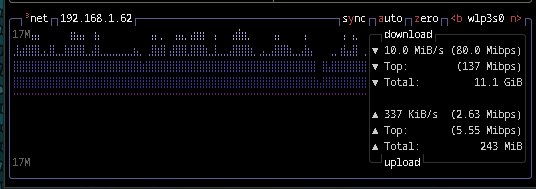
You can see the full generation that Pycharm is actually doing (in case your manual scripts do not work)
/home/c/coding_new/08_subliminal_gen/higgs-audio/venv/bin/python /home/c/coding_new/08_subliminal_gen/higgs-audio/examples/generation.py --transcript transcript/single_speaker/en_dl.txt --ref_audio broom_salesman --seed 12345 --out_path generation.wav
The audio being read:
Hey, everyone! Welcome back to Tech Talk Tuesdays.
It’s your host, Alex, and today, we’re diving into a topic that’s become absolutely crucial in the tech world — deep learning.
And let’s be honest, if you’ve been even remotely connected to tech, AI, or machine learning lately, you know that deep learning is everywhere.
So here’s the big question: Do you want to understand how deep learning works?
How to use it to build powerful models that can predict, automate, and transform industries?
Well, today, I’ve got some exciting news for you.
We’re going to talk about a course that I highly recommend: Dive into Deep Learning.
It’s not just another course; it’s an entire experience that will take you from a beginner to someone who is well-versed in deep learning techniques.And this is the output:
- It is slow: The standard generation.py will generate errors as it cannot run as it is configured on a 1660ti with only 6GB of VRAM, you may need to paste this modified one in:
- NOTE this takes a LONG time to run on a 1660ti, like 1/2 hour + to read a single paragraph. So it is really recommended unless you have a computer idling somewhere that you can forget about for a couple days, it is recommended that you get as much GPU juice as you can muster. It may still error we post the lastest fixes at the bottom
"""Example script for generating audio using HiggsAudio."""
import click
import soundfile as sf
import langid
import jieba
import os
import re
import copy
import torchaudio
import tqdm
import yaml
from loguru import logger
from boson_multimodal.serve.serve_engine import HiggsAudioServeEngine, HiggsAudioResponse
from boson_multimodal.data_types import Message, ChatMLSample, AudioContent, TextContent
from boson_multimodal.model.higgs_audio import HiggsAudioConfig, HiggsAudioModel
from boson_multimodal.data_collator.higgs_audio_collator import HiggsAudioSampleCollator
from boson_multimodal.audio_processing.higgs_audio_tokenizer import load_higgs_audio_tokenizer
from boson_multimodal.dataset.chatml_dataset import (
ChatMLDatasetSample,
prepare_chatml_sample,
)
from boson_multimodal.model.higgs_audio.utils import revert_delay_pattern
from typing import List
from transformers import AutoConfig, AutoTokenizer
from transformers.cache_utils import StaticCache
from typing import Optional
from dataclasses import asdict
import torch
CURR_DIR = os.path.dirname(os.path.abspath(__file__))
AUDIO_PLACEHOLDER_TOKEN = "<|__AUDIO_PLACEHOLDER__|>"
MULTISPEAKER_DEFAULT_SYSTEM_MESSAGE = """You are an AI assistant designed to convert text into speech.
If the user's message includes a [SPEAKER*] tag, do not read out the tag and generate speech for the following text, using the specified voice.
If no speaker tag is present, select a suitable voice on your own."""
def normalize_chinese_punctuation(text):
"""
Convert Chinese (full-width) punctuation marks to English (half-width) equivalents.
"""
# Mapping of Chinese punctuation to English punctuation
chinese_to_english_punct = {
",": ", ", # comma
"。": ".", # period
":": ":", # colon
";": ";", # semicolon
"?": "?", # question mark
"!": "!", # exclamation mark
"(": "(", # left parenthesis
")": ")", # right parenthesis
"【": "[", # left square bracket
"】": "]", # right square bracket
"《": "<", # left angle quote
"》": ">", # right angle quote
"“": '"', # left double quotation
"”": '"', # right double quotation
"‘": "'", # left single quotation
"’": "'", # right single quotation
"、": ",", # enumeration comma
"—": "-", # em dash
"…": "...", # ellipsis
"·": ".", # middle dot
"「": '"', # left corner bracket
"」": '"', # right corner bracket
"『": '"', # left double corner bracket
"』": '"', # right double corner bracket
}
# Replace each Chinese punctuation with its English counterpart
for zh_punct, en_punct in chinese_to_english_punct.items():
text = text.replace(zh_punct, en_punct)
return text
def prepare_chunk_text(
text, chunk_method: Optional[str] = None, chunk_max_word_num: int = 100, chunk_max_num_turns: int = 1
):
"""Chunk the text into smaller pieces. We will later feed the chunks one by one to the model.
Parameters
----------
text : str
The text to be chunked.
chunk_method : str, optional
The method to use for chunking. Options are "speaker", "word", or None. By default, we won't use any chunking and
will feed the whole text to the model.
chunk_max_word_num : int, optional
The maximum number of words for each chunk when "word" chunking method is used, by default 100
chunk_max_num_turns : int, optional
The maximum number of turns for each chunk when "speaker" chunking method is used,
Returns
-------
List[str]
The list of text chunks.
"""
if chunk_method is None:
return [text]
elif chunk_method == "speaker":
lines = text.split("\n")
speaker_chunks = []
speaker_utterance = ""
for line in lines:
line = line.strip()
if line.startswith("[SPEAKER") or line.startswith("<|speaker_id_start|>"):
if speaker_utterance:
speaker_chunks.append(speaker_utterance.strip())
speaker_utterance = line
else:
if speaker_utterance:
speaker_utterance += "\n" + line
else:
speaker_utterance = line
if speaker_utterance:
speaker_chunks.append(speaker_utterance.strip())
if chunk_max_num_turns > 1:
merged_chunks = []
for i in range(0, len(speaker_chunks), chunk_max_num_turns):
merged_chunk = "\n".join(speaker_chunks[i : i + chunk_max_num_turns])
merged_chunks.append(merged_chunk)
return merged_chunks
return speaker_chunks
elif chunk_method == "word":
# TODO: We may improve the logic in the future
# For long-form generation, we will first divide the text into multiple paragraphs by splitting with "\n\n"
# After that, we will chunk each paragraph based on word count
language = langid.classify(text)[0]
paragraphs = text.split("\n\n")
chunks = []
for idx, paragraph in enumerate(paragraphs):
if language == "zh":
# For Chinese, we will chunk based on character count
words = list(jieba.cut(paragraph, cut_all=False))
for i in range(0, len(words), chunk_max_word_num):
chunk = "".join(words[i : i + chunk_max_word_num])
chunks.append(chunk)
else:
words = paragraph.split(" ")
for i in range(0, len(words), chunk_max_word_num):
chunk = " ".join(words[i : i + chunk_max_word_num])
chunks.append(chunk)
chunks[-1] += "\n\n"
return chunks
else:
raise ValueError(f"Unknown chunk method: {chunk_method}")
def _build_system_message_with_audio_prompt(system_message):
contents = []
while AUDIO_PLACEHOLDER_TOKEN in system_message:
loc = system_message.find(AUDIO_PLACEHOLDER_TOKEN)
contents.append(TextContent(system_message[:loc]))
contents.append(AudioContent(audio_url=""))
system_message = system_message[loc + len(AUDIO_PLACEHOLDER_TOKEN) :]
if len(system_message) > 0:
contents.append(TextContent(system_message))
ret = Message(
role="system",
content=contents,
)
return ret
class HiggsAudioModelClient:
def __init__(
self,
model_path,
audio_tokenizer,
device=None,
device_id=None,
max_new_tokens=2048,
kv_cache_lengths: List[int] = [1024, 4096, 8192], # Multiple KV cache sizes,
use_static_kv_cache=False,
):
# Use explicit device if provided, otherwise try CUDA/MPS/CPU
if device_id is not None:
device = f"cuda:{device_id}"
self._device = device
else:
if device is not None:
self._device = device
else: # We get to choose the device
# Prefer CUDA over MPS (Apple Silicon GPU) over CPU if available
if torch.cuda.is_available():
self._device = "cuda:0"
elif torch.backends.mps.is_available():
self._device = "mps"
else:
self._device = "cpu"
logger.info(f"Using device: {self._device}")
# Detect VRAM and adjust settings for low-VRAM GPUs (e.g., 6 GB)
vram_gb = None
device_map = self._device
torch_dtype = torch.bfloat16
audio_tokenizer_device = self._device
if "cuda" in self._device:
device_idx = int(self._device.split(":")[-1])
vram_gb = torch.cuda.get_device_properties(device_idx).total_memory / (1024 ** 3)
logger.info(f"Detected GPU VRAM: {vram_gb:.2f} GB")
if vram_gb <= 6:
use_static_kv_cache = False
device_map = "auto" # Offload to CPU if GPU memory overflows
torch_dtype = torch.float16 # Fallback for unsupported bfloat16 on older GPUs
audio_tokenizer_device = "cpu" # Load tokenizer on CPU to save GPU memory
logger.info("Low VRAM detected (<= 6 GB); enabling auto device mapping, float16, and CPU tokenizer fallback.")
if isinstance(audio_tokenizer, str):
self._audio_tokenizer = load_higgs_audio_tokenizer(audio_tokenizer, device=audio_tokenizer_device)
else:
self._audio_tokenizer = audio_tokenizer
self._model = HiggsAudioModel.from_pretrained(
model_path,
device_map=device_map,
torch_dtype=torch_dtype,
)
self._model.eval()
self._kv_cache_lengths = kv_cache_lengths
self._use_static_kv_cache = use_static_kv_cache
self._tokenizer = AutoTokenizer.from_pretrained(model_path)
self._config = AutoConfig.from_pretrained(model_path)
self._max_new_tokens = max_new_tokens
self._collator = HiggsAudioSampleCollator(
whisper_processor=None,
audio_in_token_id=self._config.audio_in_token_idx,
audio_out_token_id=self._config.audio_out_token_idx,
audio_stream_bos_id=self._config.audio_stream_bos_id,
audio_stream_eos_id=self._config.audio_stream_eos_id,
encode_whisper_embed=self._config.encode_whisper_embed,
pad_token_id=self._config.pad_token_id,
return_audio_in_tokens=self._config.encode_audio_in_tokens,
use_delay_pattern=self._config.use_delay_pattern,
round_to=1,
audio_num_codebooks=self._config.audio_num_codebooks,
)
self.kv_caches = None
if use_static_kv_cache:
self._init_static_kv_cache()
def _init_static_kv_cache(self):
cache_config = copy.deepcopy(self._model.config.text_config)
cache_config.num_hidden_layers = self._model.config.text_config.num_hidden_layers
if self._model.config.audio_dual_ffn_layers:
cache_config.num_hidden_layers += len(self._model.config.audio_dual_ffn_layers)
# A list of KV caches for different lengths
self.kv_caches = {
length: StaticCache(
config=cache_config,
max_batch_size=1,
max_cache_len=length,
device=self._model.device,
dtype=self._model.dtype,
)
for length in sorted(self._kv_cache_lengths)
}
# Capture CUDA graphs for each KV cache length
if "cuda" in self._device:
logger.info(f"Capturing CUDA graphs for each KV cache length")
self._model.capture_model(self.kv_caches.values())
def _prepare_kv_caches(self):
for kv_cache in self.kv_caches.values():
kv_cache.reset()
@torch.inference_mode()
def generate(
self,
messages,
audio_ids,
chunked_text,
generation_chunk_buffer_size,
temperature=1.0,
top_k=50,
top_p=0.95,
ras_win_len=7,
ras_win_max_num_repeat=2,
seed=123,
*args,
**kwargs,
):
if ras_win_len is not None and ras_win_len <= 0:
ras_win_len = None
sr = 24000
audio_out_ids_l = []
generated_audio_ids = []
generation_messages = []
for idx, chunk_text in tqdm.tqdm(
enumerate(chunked_text), desc="Generating audio chunks", total=len(chunked_text)
):
generation_messages.append(
Message(
role="user",
content=chunk_text,
)
)
chatml_sample = ChatMLSample(messages=messages + generation_messages)
input_tokens, _, _, _ = prepare_chatml_sample(chatml_sample, self._tokenizer)
postfix = self._tokenizer.encode(
"<|start_header_id|>assistant<|end_header_id|>\n\n", add_special_tokens=False
)
input_tokens.extend(postfix)
logger.info(f"========= Chunk {idx} Input =========")
logger.info(self._tokenizer.decode(input_tokens))
context_audio_ids = audio_ids + generated_audio_ids
curr_sample = ChatMLDatasetSample(
input_ids=torch.LongTensor(input_tokens),
label_ids=None,
audio_ids_concat=torch.concat([ele.cpu() for ele in context_audio_ids], dim=1)
if context_audio_ids
else None,
audio_ids_start=torch.cumsum(
torch.tensor([0] + [ele.shape[1] for ele in context_audio_ids], dtype=torch.long), dim=0
)
if context_audio_ids
else None,
audio_waveforms_concat=None,
audio_waveforms_start=None,
audio_sample_rate=None,
audio_speaker_indices=None,
)
batch_data = self._collator([curr_sample])
batch = asdict(batch_data)
for k, v in batch.items():
if isinstance(v, torch.Tensor):
batch[k] = v.contiguous().to(self._device)
if self._use_static_kv_cache:
self._prepare_kv_caches()
# Generate audio
outputs = self._model.generate(
**batch,
max_new_tokens=self._max_new_tokens,
use_cache=True,
do_sample=True,
temperature=temperature,
top_k=top_k,
top_p=top_p,
past_key_values_buckets=self.kv_caches,
ras_win_len=ras_win_len,
ras_win_max_num_repeat=ras_win_max_num_repeat,
stop_strings=["<|end_of_text|>", "<|eot_id|>"],
tokenizer=self._tokenizer,
seed=seed,
)
step_audio_out_ids_l = []
for ele in outputs[1]:
audio_out_ids = ele
if self._config.use_delay_pattern:
audio_out_ids = revert_delay_pattern(audio_out_ids)
step_audio_out_ids_l.append(audio_out_ids.clip(0, self._audio_tokenizer.codebook_size - 1)[:, 1:-1])
audio_out_ids = torch.concat(step_audio_out_ids_l, dim=1)
audio_out_ids_l.append(audio_out_ids)
generated_audio_ids.append(audio_out_ids)
generation_messages.append(
Message(
role="assistant",
content=AudioContent(audio_url=""),
)
)
if generation_chunk_buffer_size is not None and len(generated_audio_ids) > generation_chunk_buffer_size:
generated_audio_ids = generated_audio_ids[-generation_chunk_buffer_size:]
generation_messages = generation_messages[(-2 * generation_chunk_buffer_size) :]
logger.info(f"========= Final Text output =========")
logger.info(self._tokenizer.decode(outputs[0][0]))
concat_audio_out_ids = torch.concat(audio_out_ids_l, dim=1)
# Fix MPS compatibility: detach and move to CPU before decoding
if concat_audio_out_ids.device.type == "mps":
concat_audio_out_ids_cpu = concat_audio_out_ids.detach().cpu()
else:
concat_audio_out_ids_cpu = concat_audio_out_ids
concat_wv = self._audio_tokenizer.decode(concat_audio_out_ids_cpu.unsqueeze(0))[0, 0]
text_result = self._tokenizer.decode(outputs[0][0])
return concat_wv, sr, text_result
def prepare_generation_context(scene_prompt, ref_audio, ref_audio_in_system_message, audio_tokenizer, speaker_tags):
"""Prepare the context for generation.
The context contains the system message, user message, assistant message, and audio prompt if any.
"""
system_message = None
messages = []
audio_ids = []
if ref_audio is not None:
num_speakers = len(ref_audio.split(","))
speaker_info_l = ref_audio.split(",")
voice_profile = None
if any([speaker_info.startswith("profile:") for speaker_info in ref_audio.split(",")]):
ref_audio_in_system_message = True
if ref_audio_in_system_message:
speaker_desc = []
for spk_id, character_name in enumerate(speaker_info_l):
if character_name.startswith("profile:"):
if voice_profile is None:
with open(f"{CURR_DIR}/voice_prompts/profile.yaml", "r", encoding="utf-8") as f:
voice_profile = yaml.safe_load(f)
character_desc = voice_profile["profiles"][character_name[len("profile:") :].strip()]
speaker_desc.append(f"SPEAKER{spk_id}: {character_desc}")
else:
speaker_desc.append(f"SPEAKER{spk_id}: {AUDIO_PLACEHOLDER_TOKEN}")
if scene_prompt:
system_message = (
"Generate audio following instruction."
"\n\n"
f"<|scene_desc_start|>\n{scene_prompt}\n\n" + "\n".join(speaker_desc) + "\n<|scene_desc_end|>"
)
else:
system_message = (
"Generate audio following instruction.\n\n"
+ f"<|scene_desc_start|>\n"
+ "\n".join(speaker_desc)
+ "\n<|scene_desc_end|>"
)
system_message = _build_system_message_with_audio_prompt(system_message)
else:
if scene_prompt:
system_message = Message(
role="system",
content=f"Generate audio following instruction.\n\n<|scene_desc_start|>\n{scene_prompt}\n<|scene_desc_end|>",
)
voice_profile = None
for spk_id, character_name in enumerate(ref_audio.split(",")):
if not character_name.startswith("profile:"):
prompt_audio_path = os.path.join(f"{CURR_DIR}/voice_prompts", f"{character_name}.wav")
prompt_text_path = os.path.join(f"{CURR_DIR}/voice_prompts", f"{character_name}.txt")
assert os.path.exists(prompt_audio_path), (
f"Voice prompt audio file {prompt_audio_path} does not exist."
)
assert os.path.exists(prompt_text_path), f"Voice prompt text file {prompt_text_path} does not exist."
with open(prompt_text_path, "r", encoding="utf-8") as f:
prompt_text = f.read().strip()
audio_tokens = audio_tokenizer.encode(prompt_audio_path)
audio_ids.append(audio_tokens)
if not ref_audio_in_system_message:
messages.append(
Message(
role="user",
content=f"[SPEAKER{spk_id}] {prompt_text}" if num_speakers > 1 else prompt_text,
)
)
messages.append(
Message(
role="assistant",
content=AudioContent(
audio_url=prompt_audio_path,
),
)
)
else:
if len(speaker_tags) > 1:
# By default, we just alternate between male and female voices
speaker_desc_l = []
for idx, tag in enumerate(speaker_tags):
if idx % 2 == 0:
speaker_desc = f"feminine"
else:
speaker_desc = f"masculine"
speaker_desc_l.append(f"{tag}: {speaker_desc}")
speaker_desc = "\n".join(speaker_desc_l)
scene_desc_l = []
if scene_prompt:
scene_desc_l.append(scene_prompt)
scene_desc_l.append(speaker_desc)
scene_desc = "\n\n".join(scene_desc_l)
system_message = Message(
role="system",
content=f"{MULTISPEAKER_DEFAULT_SYSTEM_MESSAGE}\n\n<|scene_desc_start|>\n{scene_desc}\n<|scene_desc_end|>",
)
else:
system_message_l = ["Generate audio following instruction."]
if scene_prompt:
system_message_l.append(f"<|scene_desc_start|>\n{scene_prompt}\n<|scene_desc_end|>")
system_message = Message(
role="system",
content="\n\n".join(system_message_l),
)
if system_message:
messages.insert(0, system_message)
return messages, audio_ids
@click.command()
@click.option(
"--model_path",
type=str,
default="bosonai/higgs-audio-v2-generation-3B-base",
help="Output wav file path.",
)
@click.option(
"--audio_tokenizer",
type=str,
default="bosonai/higgs-audio-v2-tokenizer",
help="Audio tokenizer path, if not set, use the default one.",
)
@click.option(
"--max_new_tokens",
type=int,
default=2048,
help="The maximum number of new tokens to generate.",
)
@click.option(
"--transcript",
type=str,
default="transcript/single_speaker/en_dl.txt",
help="The prompt to use for generation. If not set, we will use a default prompt.",
)
@click.option(
"--scene_prompt",
type=str,
default=f"{CURR_DIR}/scene_prompts/quiet_indoor.txt",
help="The scene description prompt to use for generation. If not set, or set to `empty`, we will leave it to empty.",
)
@click.option(
"--temperature",
type=float,
default=1.0,
help="The value used to module the next token probabilities.",
)
@click.option(
"--top_k",
type=int,
default=50,
help="The number of highest probability vocabulary tokens to keep for top-k-filtering.",
)
@click.option(
"--top_p",
type=float,
default=0.95,
help="If set to float < 1, only the most probable tokens with probabilities that add up to top_p or higher are kept for generation.",
)
@click.option(
"--ras_win_len",
type=int,
default=7,
help="The window length for RAS sampling. If set to 0 or a negative value, we won't use RAS sampling.",
)
@click.option(
"--ras_win_max_num_repeat",
type=int,
default=2,
help="The maximum number of times to repeat the RAS window. Only used when --ras_win_len is set.",
)
@click.option(
"--ref_audio",
type=str,
default=None,
help="The voice prompt to use for generation. If not set, we will let the model randomly pick a voice. "
"For multi-speaker generation, you can specify the prompts as `belinda,chadwick` and we will use the voice of belinda as SPEAKER0 and the voice of chadwick as SPEAKER1.",
)
@click.option(
"--ref_audio_in_system_message",
is_flag=True,
default=False,
help="Whether to include the voice prompt description in the system message.",
show_default=True,
)
@click.option(
"--chunk_method",
default=None,
type=click.Choice([None, "speaker", "word"]),
help="The method to use for chunking the prompt text. Options are 'speaker', 'word', or None. By default, we won't use any chunking and will feed the whole text to the model.",
)
@click.option(
"--chunk_max_word_num",
default=200,
type=int,
help="The maximum number of words for each chunk when 'word' chunking method is used. Only used when --chunk_method is set to 'word'.",
)
@click.option(
"--chunk_max_num_turns",
default=1,
type=int,
help="The maximum number of turns for each chunk when 'speaker' chunking method is used. Only used when --chunk_method is set to 'speaker'.",
)
@click.option(
"--generation_chunk_buffer_size",
default=None,
type=int,
help="The maximal number of chunks to keep in the buffer. We will always keep the reference audios, and keep `max_chunk_buffer` chunks of generated audio.",
)
@click.option(
"--seed",
default=None,
type=int,
help="Random seed for generation.",
)
@click.option(
"--device_id",
type=int,
default=None,
help="The device to run the model on.",
)
@click.option(
"--out_path",
type=str,
default="generation.wav",
)
@click.option(
"--use_static_kv_cache",
type=int,
default=1,
help="Whether to use static KV cache for faster generation. Only works when using GPU.",
)
@click.option(
"--device",
type=click.Choice(["auto", "cuda", "mps", "none"]),
default="auto",
help="Device to use: 'auto' (pick best available), 'cuda', 'mps', or 'none' (CPU only).",
)
def main(
model_path,
audio_tokenizer,
max_new_tokens,
transcript,
scene_prompt,
temperature,
top_k,
top_p,
ras_win_len,
ras_win_max_num_repeat,
ref_audio,
ref_audio_in_system_message,
chunk_method,
chunk_max_word_num,
chunk_max_num_turns,
generation_chunk_buffer_size,
seed,
device_id,
out_path,
use_static_kv_cache,
device,
):
# specifying a device_id implies CUDA
if device_id is None:
if device == "auto":
if torch.cuda.is_available():
device_id = 0
device = "cuda:0"
elif torch.backends.mps.is_available():
device_id = None # MPS doesn't use device IDs like CUDA
device = "mps"
else:
device_id = None
device = "cpu"
elif device == "cuda":
device_id = 0
device = "cuda:0"
elif device == "mps":
device_id = None
device = "mps"
else:
device_id = None
device = "cpu"
else:
device = f"cuda:{device_id}"
# For MPS, use CPU for audio tokenizer due to embedding operation limitations
audio_tokenizer_device = "cpu" if device == "mps" else device
audio_tokenizer = load_higgs_audio_tokenizer(audio_tokenizer, device=audio_tokenizer_device)
# Disable static KV cache on MPS since it relies on CUDA graphs
if device == "mps" and use_static_kv_cache:
use_static_kv_cache = False
model_client = HiggsAudioModelClient(
model_path=model_path,
audio_tokenizer=audio_tokenizer,
device=device,
device_id=device_id,
max_new_tokens=max_new_tokens,
use_static_kv_cache=use_static_kv_cache,
)
pattern = re.compile(r"\[(SPEAKER\d+)\]")
if os.path.exists(transcript):
logger.info(f"Loading transcript from {transcript}")
with open(transcript, "r", encoding="utf-8") as f:
transcript = f.read().strip()
if scene_prompt is not None and scene_prompt != "empty" and os.path.exists(scene_prompt):
with open(scene_prompt, "r", encoding="utf-8") as f:
scene_prompt = f.read().strip()
else:
scene_prompt = None
speaker_tags = sorted(set(pattern.findall(transcript)))
# Perform some basic normalization
transcript = normalize_chinese_punctuation(transcript)
# Other normalizations (e.g., parentheses and other symbols. Will be improved in the future)
transcript = transcript.replace("(", " ")
transcript = transcript.replace(")", " ")
transcript = transcript.replace("°F", " degrees Fahrenheit")
transcript = transcript.replace("°C", " degrees Celsius")
for tag, replacement in [
("[laugh]", "<SE>[Laughter]</SE>"),
("[humming start]", "<SE_s>[Humming]</SE_s>"),
("[humming end]", "<SE_e>[Humming]</SE_e>"),
("[music start]", "<SE_s>[Music]</SE_s>"),
("[music end]", "<SE_e>[Music]</SE_e>"),
("[music]", "<SE>[Music]</SE>"),
("[sing start]", "<SE_s>[Singing]</SE_s>"),
("[sing end]", "<SE_e>[Singing]</SE_e>"),
("[applause]", "<SE>[Applause]</SE>"),
("[cheering]", "<SE>[Cheering]</SE>"),
("[cough]", "<SE>[Cough]</SE>"),
]:
transcript = transcript.replace(tag, replacement)
lines = transcript.split("\n")
transcript = "\n".join([" ".join(line.split()) for line in lines if line.strip()])
transcript = transcript.strip()
if not any([transcript.endswith(c) for c in [".", "!", "?", ",", ";", '"', "'", "</SE_e>", "</SE>"]]):
transcript += "."
messages, audio_ids = prepare_generation_context(
scene_prompt=scene_prompt,
ref_audio=ref_audio,
ref_audio_in_system_message=ref_audio_in_system_message,
audio_tokenizer=audio_tokenizer,
speaker_tags=speaker_tags,
)
chunked_text = prepare_chunk_text(
transcript,
chunk_method=chunk_method,
chunk_max_word_num=chunk_max_word_num,
chunk_max_num_turns=chunk_max_num_turns,
)
logger.info("Chunks used for generation:")
for idx, chunk_text in enumerate(chunked_text):
logger.info(f"Chunk {idx}:")
logger.info(chunk_text)
logger.info("-----")
concat_wv, sr, text_output = model_client.generate(
messages=messages,
audio_ids=audio_ids,
chunked_text=chunked_text,
generation_chunk_buffer_size=generation_chunk_buffer_size,
temperature=temperature,
top_k=top_k,
top_p=top_p,
ras_win_len=ras_win_len,
ras_win_max_num_repeat=ras_win_max_num_repeat,
seed=seed,
)
sf.write(out_path, concat_wv, sr)
logger.info(f"Wav file is saved to '{out_path}' with sample rate {sr}")
if __name__ == "__main__":
main()You will see a progress as:

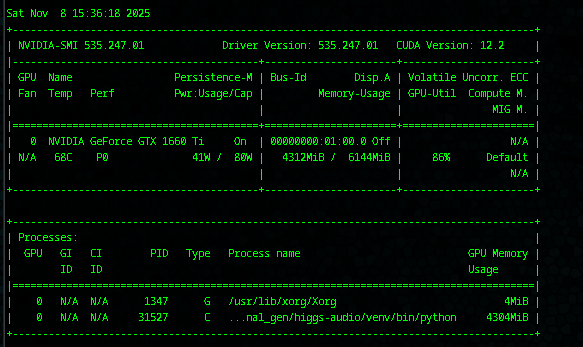
And this time it worked as you could see significant loading onto the GPU, while at the same time almost no load to the CPU:
More last fixes for even more aggressive memory optimization:
"""Example script for generating audio using HiggsAudio."""
import click
import soundfile as sf
import langid
import jieba
import os
import re
import copy
import torchaudio
import tqdm
import yaml
from loguru import logger
from boson_multimodal.serve.serve_engine import HiggsAudioServeEngine, HiggsAudioResponse
from boson_multimodal.data_types import Message, ChatMLSample, AudioContent, TextContent
from boson_multimodal.model.higgs_audio import HiggsAudioConfig, HiggsAudioModel
from boson_multimodal.data_collator.higgs_audio_collator import HiggsAudioSampleCollator
from boson_multimodal.audio_processing.higgs_audio_tokenizer import load_higgs_audio_tokenizer
from boson_multimodal.dataset.chatml_dataset import (
ChatMLDatasetSample,
prepare_chatml_sample,
)
from boson_multimodal.model.higgs_audio.utils import revert_delay_pattern
from typing import List
from transformers import AutoConfig, AutoTokenizer
from transformers.cache_utils import StaticCache
from typing import Optional
from dataclasses import asdict
import torch
# Set environment variable for better memory allocation
os.environ["PYTORCH_CUDA_ALLOC_CONF"] = "expandable_segments:True"
CURR_DIR = os.path.dirname(os.path.abspath(__file__))
AUDIO_PLACEHOLDER_TOKEN = "<|__AUDIO_PLACEHOLDER__|>"
MULTISPEAKER_DEFAULT_SYSTEM_MESSAGE = """You are an AI assistant designed to convert text into speech.
If the user's message includes a [SPEAKER*] tag, do not read out the tag and generate speech for the following text, using the specified voice.
If no speaker tag is present, select a suitable voice on your own."""
def normalize_chinese_punctuation(text):
"""
Convert Chinese (full-width) punctuation marks to English (half-width) equivalents.
"""
# Mapping of Chinese punctuation to English punctuation
chinese_to_english_punct = {
",": ", ", # comma
"。": ".", # period
":": ":", # colon
";": ";", # semicolon
"?": "?", # question mark
"!": "!", # exclamation mark
"(": "(", # left parenthesis
")": ")", # right parenthesis
"【": "[", # left square bracket
"】": "]", # right square bracket
"《": "<", # left angle quote
"》": ">", # right angle quote
"“": '"', # left double quotation
"”": '"', # right double quotation
"‘": "'", # left single quotation
"’": "'", # right single quotation
"、": ",", # enumeration comma
"—": "-", # em dash
"…": "...", # ellipsis
"·": ".", # middle dot
"「": '"', # left corner bracket
"」": '"', # right corner bracket
"『": '"', # left double corner bracket
"』": '"', # right double corner bracket
}
# Replace each Chinese punctuation with its English counterpart
for zh_punct, en_punct in chinese_to_english_punct.items():
text = text.replace(zh_punct, en_punct)
return text
def prepare_chunk_text(
text, chunk_method: Optional[str] = None, chunk_max_word_num: int = 100, chunk_max_num_turns: int = 1
):
"""Chunk the text into smaller pieces. We will later feed the chunks one by one to the model.
Parameters
----------
text : str
The text to be chunked.
chunk_method : str, optional
The method to use for chunking. Options are "speaker", "word", or None. By default, we won't use any chunking and
will feed the whole text to the model.
replace_speaker_tag_with_special_tags : bool, optional
Whether to replace speaker tags with special tokens, by default False
If the flag is set to True, we will replace [SPEAKER0] with <|speaker_id_start|>SPEAKER0<|speaker_id_end|>
chunk_max_word_num : int, optional
The maximum number of words for each chunk when "word" chunking method is used, by default 100
chunk_max_num_turns : int, optional
The maximum number of turns for each chunk when "speaker" chunking method is used,
Returns
-------
List[str]
The list of text chunks.
"""
if chunk_method is None:
return [text]
elif chunk_method == "speaker":
lines = text.split("\n")
speaker_chunks = []
speaker_utterance = ""
for line in lines:
line = line.strip()
if line.startswith("[SPEAKER") or line.startswith("<|speaker_id_start|>"):
if speaker_utterance:
speaker_chunks.append(speaker_utterance.strip())
speaker_utterance = line
else:
if speaker_utterance:
speaker_utterance += "\n" + line
else:
speaker_utterance = line
if speaker_utterance:
speaker_chunks.append(speaker_utterance.strip())
if chunk_max_num_turns > 1:
merged_chunks = []
for i in range(0, len(speaker_chunks), chunk_max_num_turns):
merged_chunk = "\n".join(speaker_chunks[i : i + chunk_max_num_turns])
merged_chunks.append(merged_chunk)
return merged_chunks
return speaker_chunks
elif chunk_method == "word":
# TODO: We may improve the logic in the future
# For long-form generation, we will first divide the text into multiple paragraphs by splitting with "\n\n"
# After that, we will chunk each paragraph based on word count
language = langid.classify(text)[0]
paragraphs = text.split("\n\n")
chunks = []
for idx, paragraph in enumerate(paragraphs):
if language == "zh":
# For Chinese, we will chunk based on character count
words = list(jieba.cut(paragraph, cut_all=False))
for i in range(0, len(words), chunk_max_word_num):
chunk = "".join(words[i : i + chunk_max_word_num])
chunks.append(chunk)
else:
words = paragraph.split(" ")
for i in range(0, len(words), chunk_max_word_num):
chunk = " ".join(words[i : i + chunk_max_word_num])
chunks.append(chunk)
chunks[-1] += "\n\n"
return chunks
else:
raise ValueError(f"Unknown chunk method: {chunk_method}")
def _build_system_message_with_audio_prompt(system_message):
contents = []
while AUDIO_PLACEHOLDER_TOKEN in system_message:
loc = system_message.find(AUDIO_PLACEHOLDER_TOKEN)
contents.append(TextContent(system_message[:loc]))
contents.append(AudioContent(audio_url=""))
system_message = system_message[loc + len(AUDIO_PLACEHOLDER_TOKEN) :]
if len(system_message) > 0:
contents.append(TextContent(system_message))
ret = Message(
role="system",
content=contents,
)
return ret
class HiggsAudioModelClient:
def __init__(
self,
model_path,
audio_tokenizer,
device=None,
device_id=None,
max_new_tokens=2048,
kv_cache_lengths: List[int] = [1024, 4096, 8192], # Multiple KV cache sizes,
use_static_kv_cache=False,
):
# Detect number of GPUs
num_gpus = torch.cuda.device_count()
logger.info(f"Detected {num_gpus} GPUs.")
# Use device_map="auto" for multi-GPU support
if num_gpus > 1:
device_map = "auto"
use_static_kv_cache = False # Static KV cache may not work well with multi-GPU
logger.info("Using multi-GPU setup with device_map='auto'.")
else:
device_map = device if device else ("cuda:0" if torch.cuda.is_available() else "cpu")
# Use float16 for reduced memory usage on 3060 Ti
torch_dtype = torch.float16
# Load audio tokenizer on CPU to save VRAM
audio_tokenizer_device = "cpu"
logger.info("Loading audio tokenizer on CPU to conserve VRAM.")
if isinstance(audio_tokenizer, str):
self._audio_tokenizer = load_higgs_audio_tokenizer(audio_tokenizer, device=audio_tokenizer_device)
else:
self._audio_tokenizer = audio_tokenizer
self._model = HiggsAudioModel.from_pretrained(
model_path,
device_map=device_map,
torch_dtype=torch_dtype,
)
self._model.eval()
self._kv_cache_lengths = kv_cache_lengths
self._use_static_kv_cache = use_static_kv_cache
self._tokenizer = AutoTokenizer.from_pretrained(model_path)
self._config = AutoConfig.from_pretrained(model_path)
self._max_new_tokens = max_new_tokens
self._collator = HiggsAudioSampleCollator(
whisper_processor=None,
audio_in_token_id=self._config.audio_in_token_idx,
audio_out_token_id=self._config.audio_out_token_idx,
audio_stream_bos_id=self._config.audio_stream_bos_id,
audio_stream_eos_id=self._config.audio_stream_eos_id,
encode_whisper_embed=self._config.encode_whisper_embed,
pad_token_id=self._config.pad_token_id,
return_audio_in_tokens=self._config.encode_audio_in_tokens,
use_delay_pattern=self._config.use_delay_pattern,
round_to=1,
audio_num_codebooks=self._config.audio_num_codebooks,
)
self.kv_caches = None
if use_static_kv_cache:
self._init_static_kv_cache()
def _init_static_kv_cache(self):
cache_config = copy.deepcopy(self._model.config.text_config)
cache_config.num_hidden_layers = self._model.config.text_config.num_hidden_layers
if self._model.config.audio_dual_ffn_layers:
cache_config.num_hidden_layers += len(self._model.config.audio_dual_ffn_layers)
# A list of KV caches for different lengths
self.kv_caches = {
length: StaticCache(
config=cache_config,
max_batch_size=1,
max_cache_len=length,
device=self._model.device,
dtype=self._model.dtype,
)
for length in sorted(self._kv_cache_lengths)
}
# Capture CUDA graphs for each KV cache length
if torch.cuda.is_available():
logger.info(f"Capturing CUDA graphs for each KV cache length")
self._model.capture_model(self.kv_caches.values())
def _prepare_kv_caches(self):
for kv_cache in self.kv_caches.values():
kv_cache.reset()
@torch.inference_mode()
def generate(
self,
messages,
audio_ids,
chunked_text,
generation_chunk_buffer_size,
temperature=1.0,
top_k=50,
top_p=0.95,
ras_win_len=7,
ras_win_max_num_repeat=2,
seed=123,
*args,
**kwargs,
):
if ras_win_len is not None and ras_win_len <= 0:
ras_win_len = None
sr = 24000
audio_out_ids_l = []
generated_audio_ids = []
generation_messages = []
for idx, chunk_text in tqdm.tqdm(
enumerate(chunked_text), desc="Generating audio chunks", total=len(chunked_text)
):
generation_messages.append(
Message(
role="user",
content=chunk_text,
)
)
chatml_sample = ChatMLSample(messages=messages + generation_messages)
input_tokens, _, _, _ = prepare_chatml_sample(chatml_sample, self._tokenizer)
postfix = self._tokenizer.encode(
"<|start_header_id|>assistant<|end_header_id|>\n\n", add_special_tokens=False
)
input_tokens.extend(postfix)
logger.info(f"========= Chunk {idx} Input =========")
logger.info(self._tokenizer.decode(input_tokens))
context_audio_ids = audio_ids + generated_audio_ids
curr_sample = ChatMLDatasetSample(
input_ids=torch.LongTensor(input_tokens),
label_ids=None,
audio_ids_concat=torch.concat([ele.cpu() for ele in context_audio_ids], dim=1)
if context_audio_ids
else None,
audio_ids_start=torch.cumsum(
torch.tensor([0] + [ele.shape[1] for ele in context_audio_ids], dtype=torch.long), dim=0
)
if context_audio_ids
else None,
audio_waveforms_concat=None,
audio_waveforms_start=None,
audio_sample_rate=None,
audio_speaker_indices=None,
)
batch_data = self._collator([curr_sample])
batch = asdict(batch_data)
for k, v in batch.items():
if isinstance(v, torch.Tensor):
batch[k] = v.contiguous()
if self._use_static_kv_cache:
self._prepare_kv_caches()
# Generate audio
outputs = self._model.generate(
**batch,
max_new_tokens=self._max_new_tokens,
use_cache=True,
do_sample=True,
temperature=temperature,
top_k=top_k,
top_p=top_p,
past_key_values_buckets=self.kv_caches,
ras_win_len=ras_win_len,
ras_win_max_num_repeat=ras_win_max_num_repeat,
stop_strings=["<|end_of_text|>", "<|eot_id|>"],
tokenizer=self._tokenizer,
seed=seed,
)
step_audio_out_ids_l = []
for ele in outputs[1]:
audio_out_ids = ele
if self._config.use_delay_pattern:
audio_out_ids = revert_delay_pattern(audio_out_ids)
step_audio_out_ids_l.append(audio_out_ids.clip(0, self._audio_tokenizer.codebook_size - 1)[:, 1:-1])
audio_out_ids = torch.concat(step_audio_out_ids_l, dim=1)
audio_out_ids_l.append(audio_out_ids)
generated_audio_ids.append(audio_out_ids)
generation_messages.append(
Message(
role="assistant",
content=AudioContent(audio_url=""),
)
)
if generation_chunk_buffer_size is not None and len(generated_audio_ids) > generation_chunk_buffer_size:
generated_audio_ids = generated_audio_ids[-generation_chunk_buffer_size:]
generation_messages = generation_messages[(-2 * generation_chunk_buffer_size) :]
logger.info(f"========= Final Text output =========")
logger.info(self._tokenizer.decode(outputs[0][0]))
concat_audio_out_ids = torch.concat(audio_out_ids_l, dim=1)
# Fix MPS compatibility: detach and move to CPU before decoding
if concat_audio_out_ids.device.type == "mps":
concat_audio_out_ids_cpu = concat_audio_out_ids.detach().cpu()
else:
concat_audio_out_ids_cpu = concat_audio_out_ids
concat_wv = self._audio_tokenizer.decode(concat_audio_out_ids_cpu.unsqueeze(0))[0, 0]
text_result = self._tokenizer.decode(outputs[0][0])
return concat_wv, sr, text_result
def prepare_generation_context(scene_prompt, ref_audio, ref_audio_in_system_message, audio_tokenizer, speaker_tags):
"""Prepare the context for generation.
The context contains the system message, user message, assistant message, and audio prompt if any.
"""
system_message = None
messages = []
audio_ids = []
if ref_audio is not None:
num_speakers = len(ref_audio.split(","))
speaker_info_l = ref_audio.split(",")
voice_profile = None
if any([speaker_info.startswith("profile:") for speaker_info in ref_audio.split(",")]):
ref_audio_in_system_message = True
if ref_audio_in_system_message:
speaker_desc = []
for spk_id, character_name in enumerate(speaker_info_l):
if character_name.startswith("profile:"):
if voice_profile is None:
with open(f"{CURR_DIR}/voice_prompts/profile.yaml", "r", encoding="utf-8") as f:
voice_profile = yaml.safe_load(f)
character_desc = voice_profile["profiles"][character_name[len("profile:") :].strip()]
speaker_desc.append(f"SPEAKER{spk_id}: {character_desc}")
else:
speaker_desc.append(f"SPEAKER{spk_id}: {AUDIO_PLACEHOLDER_TOKEN}")
if scene_prompt:
system_message = (
"Generate audio following instruction."
"\n\n"
f"<|scene_desc_start|>\n{scene_prompt}\n\n" + "\n".join(speaker_desc) + "\n<|scene_desc_end|>"
)
else:
system_message = (
"Generate audio following instruction.\n\n"
+ f"<|scene_desc_start|>\n"
+ "\n".join(speaker_desc)
+ "\n<|scene_desc_end|>"
)
system_message = _build_system_message_with_audio_prompt(system_message)
else:
if scene_prompt:
system_message = Message(
role="system",
content=f"Generate audio following instruction.\n\n<|scene_desc_start|>\n{scene_prompt}\n<|scene_desc_end|>",
)
voice_profile = None
for spk_id, character_name in enumerate(ref_audio.split(",")):
if not character_name.startswith("profile:"):
prompt_audio_path = os.path.join(f"{CURR_DIR}/voice_prompts", f"{character_name}.wav")
prompt_text_path = os.path.join(f"{CURR_DIR}/voice_prompts", f"{character_name}.txt")
assert os.path.exists(prompt_audio_path), (
f"Voice prompt audio file {prompt_audio_path} does not exist."
)
assert os.path.exists(prompt_text_path), f"Voice prompt text file {prompt_text_path} does not exist."
with open(prompt_text_path, "r", encoding="utf-8") as f:
prompt_text = f.read().strip()
audio_tokens = audio_tokenizer.encode(prompt_audio_path)
audio_ids.append(audio_tokens)
if not ref_audio_in_system_message:
messages.append(
Message(
role="user",
content=f"[SPEAKER{spk_id}] {prompt_text}" if num_speakers > 1 else prompt_text,
)
)
messages.append(
Message(
role="assistant",
content=AudioContent(
audio_url=prompt_audio_path,
),
)
)
else:
if len(speaker_tags) > 1:
# By default, we just alternate between male and female voices
speaker_desc_l = []
for idx, tag in enumerate(speaker_tags):
if idx % 2 == 0:
speaker_desc = f"feminine"
else:
speaker_desc = f"masculine"
speaker_desc_l.append(f"{tag}: {speaker_desc}")
speaker_desc = "\n".join(speaker_desc_l)
scene_desc_l = []
if scene_prompt:
scene_desc_l.append(scene_prompt)
scene_desc_l.append(speaker_desc)
scene_desc = "\n\n".join(scene_desc_l)
system_message = Message(
role="system",
content=f"{MULTISPEAKER_DEFAULT_SYSTEM_MESSAGE}\n\n<|scene_desc_start|>\n{scene_desc}\n<|scene_desc_end|>",
)
else:
system_message_l = ["Generate audio following instruction."]
if scene_prompt:
system_message_l.append(f"<|scene_desc_start|>\n{scene_prompt}\n<|scene_desc_end|>")
system_message = Message(
role="system",
content="\n\n".join(system_message_l),
)
if system_message:
messages.insert(0, system_message)
return messages, audio_ids
@click.command()
@click.option(
"--model_path",
type=str,
default="bosonai/higgs-audio-v2-generation-3B-base",
help="Output wav file path.",
)
@click.option(
"--audio_tokenizer",
type=str,
default="bosonai/higgs-audio-v2-tokenizer",
help="Audio tokenizer path, if not set, use the default one.",
)
@click.option(
"--max_new_tokens",
type=int,
default=2048,
help="The maximum number of new tokens to generate.",
)
@click.option(
"--transcript",
type=str,
default="transcript/single_speaker/en_dl.txt",
help="The prompt to use for generation. If not set, we will use a default prompt.",
)
@click.option(
"--scene_prompt",
type=str,
default=f"{CURR_DIR}/scene_prompts/quiet_indoor.txt",
help="The scene description prompt to use for generation. If not set, or set to `empty`, we will leave it to empty.",
)
@click.option(
"--temperature",
type=float,
default=1.0,
help="The value used to module the next token probabilities.",
)
@click.option(
"--top_k",
type=int,
default=50,
help="The number of highest probability vocabulary tokens to keep for top-k-filtering.",
)
@click.option(
"--top_p",
type=float,
default=0.95,
help="If set to float < 1, only the most probable tokens with probabilities that add up to top_p or higher are kept for generation.",
)
@click.option(
"--ras_win_len",
type=int,
default=7,
help="The window length for RAS sampling. If set to 0 or a negative value, we won't use RAS sampling.",
)
@click.option(
"--ras_win_max_num_repeat",
type=int,
default=2,
help="The maximum number of times to repeat the RAS window. Only used when --ras_win_len is set.",
)
@click.option(
"--ref_audio",
type=str,
default=None,
help="The voice prompt to use for generation. If not set, we will let the model randomly pick a voice. "
"For multi-speaker generation, you can specify the prompts as `belinda,chadwick` and we will use the voice of belinda as SPEAKER0 and the voice of chadwick as SPEAKER1.",
)
@click.option(
"--ref_audio_in_system_message",
is_flag=True,
default=False,
help="Whether to include the voice prompt description in the system message.",
show_default=True,
)
@click.option(
"--chunk_method",
default=None,
type=click.Choice([None, "speaker", "word"]),
help="The method to use for chunking the prompt text. Options are 'speaker', 'word', or None. By default, we won't use any chunking and will feed the whole text to the model.",
)
@click.option(
"--chunk_max_word_num",
default=200,
type=int,
help="The maximum number of words for each chunk when 'word' chunking method is used. Only used when --chunk_method is set to 'word'.",
)
@click.option(
"--chunk_max_num_turns",
default=1,
type=int,
help="The maximum number of turns for each chunk when 'speaker' chunking method is used. Only used when --chunk_method is set to 'speaker'.",
)
@click.option(
"--generation_chunk_buffer_size",
default=None,
type=int,
help="The maximal number of chunks to keep in the buffer. We will always keep the reference audios, and keep `max_chunk_buffer` chunks of generated audio.",
)
@click.option(
"--seed",
default=None,
type=int,
help="Random seed for generation.",
)
@click.option(
"--device_id",
type=int,
default=None,
help="The device to run the model on.",
)
@click.option(
"--out_path",
type=str,
default="generation.wav",
)
@click.option(
"--use_static_kv_cache",
type=int,
default=1,
help="Whether to use static KV cache for faster generation. Only works when using GPU.",
)
@click.option(
"--device",
type=click.Choice(["auto", "cuda", "mps", "none"]),
default="auto",
help="Device to use: 'auto' (pick best available), 'cuda', 'mps', or 'none' (CPU only).",
)
def main(
model_path,
audio_tokenizer,
max_new_tokens,
transcript,
scene_prompt,
temperature,
top_k,
top_p,
ras_win_len,
ras_win_max_num_repeat,
ref_audio,
ref_audio_in_system_message,
chunk_method,
chunk_max_word_num,
chunk_max_num_turns,
generation_chunk_buffer_size,
seed,
device_id,
out_path,
use_static_kv_cache,
device,
):
# specifying a device_id implies CUDA
if device_id is None:
if device == "auto":
if torch.cuda.is_available():
device_id = 0
device = "cuda:0"
elif torch.backends.mps.is_available():
device_id = None # MPS doesn't use device IDs like CUDA
device = "mps"
else:
device_id = None
device = "cpu"
elif device == "cuda":
device_id = 0
device = "cuda:0"
elif device == "mps":
device_id = None
device = "mps"
else:
device_id = None
device = "cpu"
else:
device = f"cuda:{device_id}"
# For MPS, use CPU for audio tokenizer due to embedding operation limitations
audio_tokenizer_device = "cpu" if device == "mps" else device
audio_tokenizer = load_higgs_audio_tokenizer(audio_tokenizer, device=audio_tokenizer_device)
# Disable static KV cache on MPS since it relies on CUDA graphs
if device == "mps" and use_static_kv_cache:
use_static_kv_cache = False
model_client = HiggsAudioModelClient(
model_path=model_path,
audio_tokenizer=audio_tokenizer,
device=device,
device_id=device_id,
max_new_tokens=max_new_tokens,
use_static_kv_cache=use_static_kv_cache,
)
pattern = re.compile(r"\[(SPEAKER\d+)\]")
if os.path.exists(transcript):
logger.info(f"Loading transcript from {transcript}")
with open(transcript, "r", encoding="utf-8") as f:
transcript = f.read().strip()
if scene_prompt is not None and scene_prompt != "empty" and os.path.exists(scene_prompt):
with open(scene_prompt, "r", encoding="utf-8") as f:
scene_prompt = f.read().strip()
else:
scene_prompt = None
speaker_tags = sorted(set(pattern.findall(transcript)))
# Perform some basic normalization
transcript = normalize_chinese_punctuation(transcript)
# Other normalizations (e.g., parentheses and other symbols. Will be improved in the future)
transcript = transcript.replace("(", " ")
transcript = transcript.replace(")", " ")
transcript = transcript.replace("°F", " degrees Fahrenheit")
transcript = transcript.replace("°C", " degrees Celsius")
for tag, replacement in [
("[laugh]", "<SE>[Laughter]</SE>"),
("[humming start]", "<SE_s>[Humming]</SE_s>"),
("[humming end]", "<SE_e>[Humming]</SE_e>"),
("[music start]", "<SE_s>[Music]</SE_s>"),
("[music end]", "<SE_e>[Music]</SE_e>"),
("[music]", "<SE>[Music]</SE>"),
("[sing start]", "<SE_s>[Singing]</SE_s>"),
("[sing end]", "<SE_e>[Singing]</SE_e>"),
("[applause]", "<SE>[Applause]</SE>"),
("[cheering]", "<SE>[Cheering]</SE>"),
("[cough]", "<SE>[Cough]</SE>"),
]:
transcript = transcript.replace(tag, replacement)
lines = transcript.split("\n")
transcript = "\n".join([" ".join(line.split()) for line in lines if line.strip()])
transcript = transcript.strip()
if not any([transcript.endswith(c) for c in [".", "!", "?", ",", ";", '"', "'", "</SE_e>", "</SE>"]]):
transcript += "."
messages, audio_ids = prepare_generation_context(
scene_prompt=scene_prompt,
ref_audio=ref_audio,
ref_audio_in_system_message=ref_audio_in_system_message,
audio_tokenizer=audio_tokenizer,
speaker_tags=speaker_tags,
)
chunked_text = prepare_chunk_text(
transcript,
chunk_method=chunk_method,
chunk_max_word_num=chunk_max_word_num,
chunk_max_num_turns=chunk_max_num_turns,
)
logger.info("Chunks used for generation:")
for idx, chunk_text in enumerate(chunked_text):
logger.info(f"Chunk {idx}:")
logger.info(chunk_text)
logger.info("-----")
concat_wv, sr, text_output = model_client.generate(
messages=messages,
audio_ids=audio_ids,
chunked_text=chunked_text,
generation_chunk_buffer_size=generation_chunk_buffer_size,
temperature=temperature,
top_k=top_k,
top_p=top_p,
ras_win_len=ras_win_len,
ras_win_max_num_repeat=ras_win_max_num_repeat,
seed=seed,
)
sf.write(out_path, concat_wv, sr)
logger.info(f"Wav file is saved to '{out_path}' with sample rate {sr}")
if __name__ == "__main__":
main()
