Easy LLM: Maya 1 Text-to-Speech Hits it out of the Park on an Easy-to-Use LLM.
We do a quick review and are very positively surprised at how quickly this LLM will generate .wav files in the tone and incantation that you describe to it.


We initially spent close to half a day attempting to get higgs-audio to work in any fashion. Typically this would go back and forth between asking Grok 4 to amend it's code, and then giving it a trial. We never saw so many issues with it. Well after that we tried to give Maya 1 a try, and it worked very well!
- It load balanced automatically to two GPU's without needing to get into the broccoli cycles of code tweaking back and froth from Grok 4.
- The voice to be generated could simply be described for instance in the code the following was done twice, and the LLM did a pretty good job of it
description = "Realistic male voice in the 30s age with american accent. Normal pitch, warm timbre, conversational pacing."
description = "Realistic female voice with lower pitch"
text = "Hello! This is Maya1 <laugh_harder> the best open source voice AI model with emotions."- It ran quickly and appreciably. We give this two-thumbs up for being very easy to run at the home front.

We literally cut-n-pasted the python as it is described, and it ran very well
#!/usr/bin/env python3
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
from snac import SNAC
import soundfile as sf
import numpy as np
CODE_START_TOKEN_ID = 128257
CODE_END_TOKEN_ID = 128258
CODE_TOKEN_OFFSET = 128266
SNAC_MIN_ID = 128266
SNAC_MAX_ID = 156937
SNAC_TOKENS_PER_FRAME = 7
SOH_ID = 128259
EOH_ID = 128260
SOA_ID = 128261
BOS_ID = 128000
TEXT_EOT_ID = 128009
def build_prompt(tokenizer, description: str, text: str) -> str:
"""Build formatted prompt for Maya1."""
soh_token = tokenizer.decode([SOH_ID])
eoh_token = tokenizer.decode([EOH_ID])
soa_token = tokenizer.decode([SOA_ID])
sos_token = tokenizer.decode([CODE_START_TOKEN_ID])
eot_token = tokenizer.decode([TEXT_EOT_ID])
bos_token = tokenizer.bos_token
formatted_text = f'<description="{description}"> {text}'
prompt = (
soh_token + bos_token + formatted_text + eot_token +
eoh_token + soa_token + sos_token
)
return prompt
def extract_snac_codes(token_ids: list) -> list:
"""Extract SNAC codes from generated tokens."""
try:
eos_idx = token_ids.index(CODE_END_TOKEN_ID)
except ValueError:
eos_idx = len(token_ids)
snac_codes = [
token_id for token_id in token_ids[:eos_idx]
if SNAC_MIN_ID <= token_id <= SNAC_MAX_ID
]
return snac_codes
def unpack_snac_from_7(snac_tokens: list) -> list:
"""Unpack 7-token SNAC frames to 3 hierarchical levels."""
if snac_tokens and snac_tokens[-1] == CODE_END_TOKEN_ID:
snac_tokens = snac_tokens[:-1]
frames = len(snac_tokens) // SNAC_TOKENS_PER_FRAME
snac_tokens = snac_tokens[:frames * SNAC_TOKENS_PER_FRAME]
if frames == 0:
return [[], [], []]
l1, l2, l3 = [], [], []
for i in range(frames):
slots = snac_tokens[i*7:(i+1)*7]
l1.append((slots[0] - CODE_TOKEN_OFFSET) % 4096)
l2.extend([
(slots[1] - CODE_TOKEN_OFFSET) % 4096,
(slots[4] - CODE_TOKEN_OFFSET) % 4096,
])
l3.extend([
(slots[2] - CODE_TOKEN_OFFSET) % 4096,
(slots[3] - CODE_TOKEN_OFFSET) % 4096,
(slots[5] - CODE_TOKEN_OFFSET) % 4096,
(slots[6] - CODE_TOKEN_OFFSET) % 4096,
])
return [l1, l2, l3]
def main():
# Load the best open source voice AI model
print("\n[1/3] Loading Maya1 model...")
model = AutoModelForCausalLM.from_pretrained(
"maya-research/maya1",
torch_dtype=torch.bfloat16,
device_map="auto",
trust_remote_code=True
)
tokenizer = AutoTokenizer.from_pretrained(
"maya-research/maya1",
trust_remote_code=True
)
print(f"Model loaded: {len(tokenizer)} tokens in vocabulary")
# Load SNAC audio decoder (24kHz)
print("\n[2/3] Loading SNAC audio decoder...")
snac_model = SNAC.from_pretrained("hubertsiuzdak/snac_24khz").eval()
if torch.cuda.is_available():
snac_model = snac_model.to("cuda")
print("SNAC decoder loaded")
# Design your voice with natural language
description = "Realistic male voice in the 30s age with american accent. Normal pitch, warm timbre, conversational pacing."
text = "Hello! This is Maya1 <laugh_harder> the best open source voice AI model with emotions."
print("\n[3/3] Generating speech...")
print(f"Description: {description}")
print(f"Text: {text}")
# Create prompt with proper formatting
prompt = build_prompt(tokenizer, description, text)
# Debug: Show prompt details
print(f"\nPrompt preview (first 200 chars):")
print(f" {repr(prompt[:200])}")
print(f" Prompt length: {len(prompt)} chars")
# Generate emotional speech
inputs = tokenizer(prompt, return_tensors="pt")
print(f" Input token count: {inputs['input_ids'].shape[1]} tokens")
if torch.cuda.is_available():
inputs = {k: v.to("cuda") for k, v in inputs.items()}
with torch.inference_mode():
outputs = model.generate(
**inputs,
max_new_tokens=2048, # Increase to let model finish naturally
min_new_tokens=28, # At least 4 SNAC frames
temperature=0.4,
top_p=0.9,
repetition_penalty=1.1, # Prevent loops
do_sample=True,
eos_token_id=CODE_END_TOKEN_ID, # Stop at end of speech token
pad_token_id=tokenizer.pad_token_id,
)
# Extract generated tokens (everything after the input prompt)
generated_ids = outputs[0, inputs['input_ids'].shape[1]:].tolist()
print(f"Generated {len(generated_ids)} tokens")
# Debug: Check what tokens we got
print(f" First 20 tokens: {generated_ids[:20]}")
print(f" Last 20 tokens: {generated_ids[-20:]}")
# Check if EOS was generated
if CODE_END_TOKEN_ID in generated_ids:
eos_position = generated_ids.index(CODE_END_TOKEN_ID)
print(f" EOS token found at position {eos_position}/{len(generated_ids)}")
# Extract SNAC audio tokens
snac_tokens = extract_snac_codes(generated_ids)
print(f"Extracted {len(snac_tokens)} SNAC tokens")
# Debug: Analyze token types
snac_count = sum(1 for t in generated_ids if SNAC_MIN_ID <= t <= SNAC_MAX_ID)
other_count = sum(1 for t in generated_ids if t < SNAC_MIN_ID or t > SNAC_MAX_ID)
print(f" SNAC tokens in output: {snac_count}")
print(f" Other tokens in output: {other_count}")
# Check for SOS token
if CODE_START_TOKEN_ID in generated_ids:
sos_pos = generated_ids.index(CODE_START_TOKEN_ID)
print(f" SOS token at position: {sos_pos}")
else:
print(f" No SOS token found in generated output!")
if len(snac_tokens) < 7:
print("Error: Not enough SNAC tokens generated")
return
# Unpack SNAC tokens to 3 hierarchical levels
levels = unpack_snac_from_7(snac_tokens)
frames = len(levels[0])
print(f"Unpacked to {frames} frames")
print(f" L1: {len(levels[0])} codes")
print(f" L2: {len(levels[1])} codes")
print(f" L3: {len(levels[2])} codes")
# Convert to tensors
device = "cuda" if torch.cuda.is_available() else "cpu"
codes_tensor = [
torch.tensor(level, dtype=torch.long, device=device).unsqueeze(0)
for level in levels
]
# Generate final audio with SNAC decoder
print("\n[4/4] Decoding to audio...")
with torch.inference_mode():
z_q = snac_model.quantizer.from_codes(codes_tensor)
audio = snac_model.decoder(z_q)[0, 0].cpu().numpy()
# Trim warmup samples (first 2048 samples)
if len(audio) > 2048:
audio = audio[2048:]
duration_sec = len(audio) / 24000
print(f"Audio generated: {len(audio)} samples ({duration_sec:.2f}s)")
# Save your emotional voice output
output_file = "output.wav"
sf.write(output_file, audio, 24000)
print(f"\nVoice generated successfully!")
if __name__ == "__main__":
main()
It worked first time, and of course you are going to have a fair bit of downloads the first time with any LLM as it pulls its 'shards'
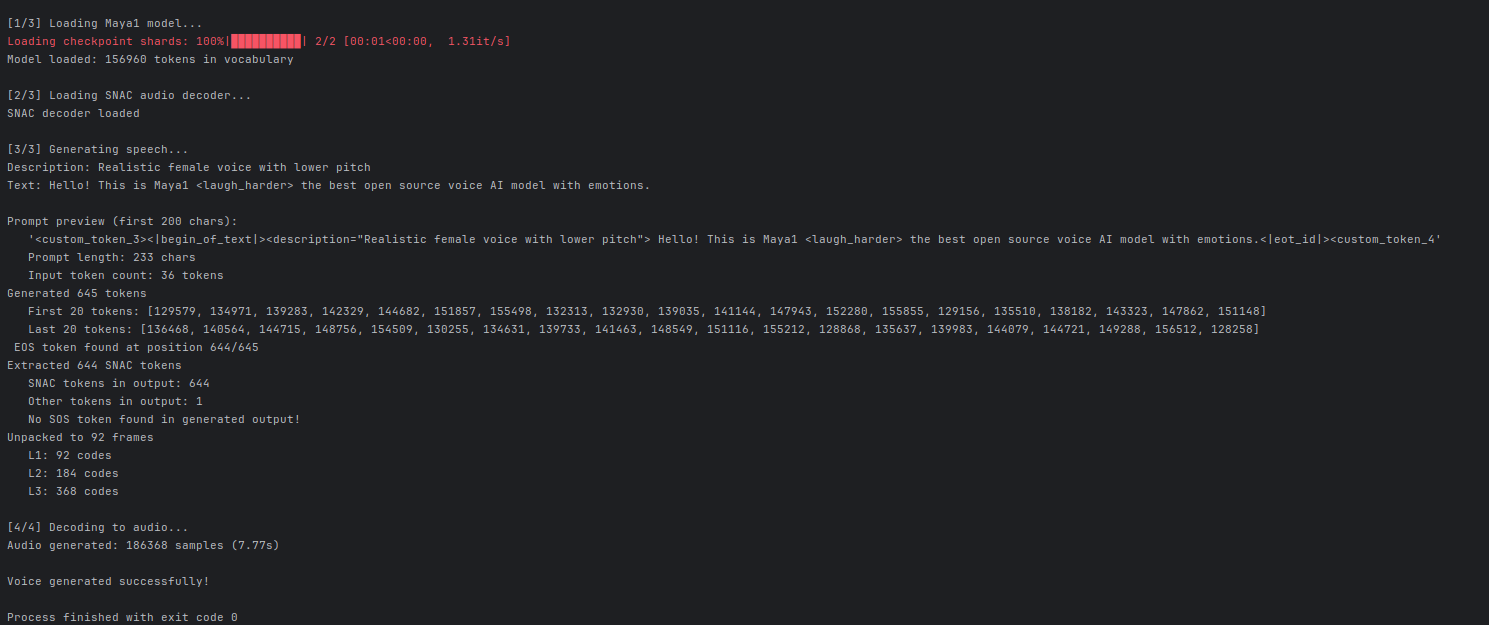
Benchmarks: Approximately ~2 words/second when loaded across 2-3060ti video cards. 3060ti video cards are a very good benchmark because it is a humble requirement, you are not starting with high-end 4090ti video cards that the lower-end public simply cannot afford.
We then updated this to process whole files to generated output wav files in sequential order, as in:
#!/usr/bin/env python3
import os
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
from snac import SNAC
import soundfile as sf
import numpy as np
CODE_START_TOKEN_ID = 128257
CODE_END_TOKEN_ID = 128258
CODE_TOKEN_OFFSET = 128266
SNAC_MIN_ID = 128266
SNAC_MAX_ID = 156937
SNAC_TOKENS_PER_FRAME = 7
SOH_ID = 128259
EOH_ID = 128260
SOA_ID = 128261
BOS_ID = 128000
TEXT_EOT_ID = 128009
def build_prompt(tokenizer, description: str, text: str) -> str:
"""Build formatted prompt for Maya1."""
soh_token = tokenizer.decode([SOH_ID])
eoh_token = tokenizer.decode([EOH_ID])
soa_token = tokenizer.decode([SOA_ID])
sos_token = tokenizer.decode([CODE_START_TOKEN_ID])
eot_token = tokenizer.decode([TEXT_EOT_ID])
bos_token = tokenizer.bos_token
formatted_text = f'<description="{description}"> {text}'
prompt = (
soh_token + bos_token + formatted_text + eot_token +
eoh_token + soa_token + sos_token
)
return prompt
def extract_snac_codes(token_ids: list) -> list:
"""Extract SNAC codes from generated tokens."""
try:
eos_idx = token_ids.index(CODE_END_TOKEN_ID)
except ValueError:
eos_idx = len(token_ids)
snac_codes = [
token_id for token_id in token_ids[:eos_idx]
if SNAC_MIN_ID <= token_id <= SNAC_MAX_ID
]
return snac_codes
def unpack_snac_from_7(snac_tokens: list) -> list:
"""Unpack 7-token SNAC frames to 3 hierarchical levels."""
if snac_tokens and snac_tokens[-1] == CODE_END_TOKEN_ID:
snac_tokens = snac_tokens[:-1]
frames = len(snac_tokens) // SNAC_TOKENS_PER_FRAME
snac_tokens = snac_tokens[:frames * SNAC_TOKENS_PER_FRAME]
if frames == 0:
return [[], [], []]
l1, l2, l3 = [], [], []
for i in range(frames):
slots = snac_tokens[i * 7:(i + 1) * 7]
l1.append((slots[0] - CODE_TOKEN_OFFSET) % 4096)
l2.extend([
(slots[1] - CODE_TOKEN_OFFSET) % 4096,
(slots[4] - CODE_TOKEN_OFFSET) % 4096,
])
l3.extend([
(slots[2] - CODE_TOKEN_OFFSET) % 4096,
(slots[3] - CODE_TOKEN_OFFSET) % 4096,
(slots[5] - CODE_TOKEN_OFFSET) % 4096,
(slots[6] - CODE_TOKEN_OFFSET) % 4096,
])
return [l1, l2, l3]
def main():
pwd = os.getcwd()
tfile = pwd + "/subliminal/01_super_coder.txt"
print(f"Loading {tfile}")
with open(tfile, "r") as g:
data = g.readlines()
# Load the best open source voice AI model
print("\n[1/3] Loading Maya1 model...")
model = AutoModelForCausalLM.from_pretrained(
"maya-research/maya1",
torch_dtype=torch.bfloat16,
device_map="auto",
trust_remote_code=True
)
tokenizer = AutoTokenizer.from_pretrained(
"maya-research/maya1",
trust_remote_code=True
)
print(f"Model loaded: {len(tokenizer)} tokens in vocabulary")
# Load SNAC audio decoder (24kHz)
print("\n[2/3] Loading SNAC audio decoder...")
snac_model = SNAC.from_pretrained("hubertsiuzdak/snac_24khz").eval()
if torch.cuda.is_available():
snac_model = snac_model.to("cuda")
print("SNAC decoder loaded")
description = "Realistic male voice in the 30s age with american accent. Normal pitch, warm timbre, conversational pacing."
c = 0
clen = len(data)
while c < clen:
text = data[c]
prompt = build_prompt(tokenizer, description, text)
inputs = tokenizer(prompt, return_tensors="pt")
if torch.cuda.is_available():
inputs = {k: v.to("cuda") for k, v in inputs.items()}
with torch.inference_mode():
outputs = model.generate(
**inputs,
max_new_tokens=2048, # Increase to let model finish naturally
min_new_tokens=28, # At least 4 SNAC frames
temperature=0.4,
top_p=0.9,
repetition_penalty=1.1, # Prevent loops
do_sample=True,
eos_token_id=CODE_END_TOKEN_ID, # Stop at end of speech token
pad_token_id=tokenizer.pad_token_id,
)
generated_ids = outputs[0, inputs['input_ids'].shape[1]:].tolist()
if CODE_END_TOKEN_ID in generated_ids:
eos_position = generated_ids.index(CODE_END_TOKEN_ID)
snac_tokens = extract_snac_codes(generated_ids)
if CODE_START_TOKEN_ID in generated_ids:
sos_pos = generated_ids.index(CODE_START_TOKEN_ID)
else:
pass
if len(snac_tokens) < 7:
return
levels = unpack_snac_from_7(snac_tokens)
device = "cuda" if torch.cuda.is_available() else "cpu"
codes_tensor = [
torch.tensor(level, dtype=torch.long, device=device).unsqueeze(0)
for level in levels
]
with torch.inference_mode():
z_q = snac_model.quantizer.from_codes(codes_tensor)
audio = snac_model.decoder(z_q)[0, 0].cpu().numpy()
if len(audio) > 2048:
audio = audio[2048:]
duration_sec = len(audio) / 24000
print(f"({duration_sec:.2f}s)")
print(f"Text {duration_sec:0.2f}s : {text} \n subliminal_out/{c:03d}_output.wav")
output_file = f""
sf.write(output_file, audio, 24000)
c += 1
if __name__ == "__main__":
main()
From here it was a small call to get Grok 4 to write a joining script to join all the files and convert to mp3 as in:
#!/bin/bash
# This script concatenates all .wav files in the current directory into a single MP3 file.
# It sorts the files alphabetically by name before concatenation.
# Output file: output.mp3
# Requirements: ffmpeg must be installed and available in the PATH.
# Check if ffmpeg is installed
if ! command -v ffmpeg &> /dev/null; then
echo "Error: ffmpeg is not installed. Please install ffmpeg to proceed."
exit 1
fi
# Check if nproc is available to detect number of cores
if ! command -v nproc &> /dev/null; then
echo "Warning: nproc not found. Defaulting to 1 thread."
threads=1
else
threads=$(nproc)
echo "Detected $threads CPU cores. Using all cores for ffmpeg processing."
fi
# Temporary file to list the WAV files for concatenation
list_file="wav_list.txt"
# Find all .wav files in the current directory, sort them alphabetically, and write to the list file
find . -maxdepth 1 -type f -iname "*.wav" | sort | while read -r file; do
echo "file '${file}'" >> "$list_file"
done
# Check if any .wav files were found
if [ ! -s "$list_file" ]; then
echo "Error: No .wav files found in the current directory."
rm -f "$list_file"
exit 1
fi
# Use ffmpeg to concatenate the files and convert to MP3, utilizing all detected cores
ffmpeg -f concat -safe 0 -i "$list_file" -c:a libmp3lame -q:a 2 -threads "$threads" output.mp3
# Clean up the temporary list file
rm -f "$list_file"
echo "Concatenation complete. Output file: output.mp3"