Audio LLM audio-flamingo-3-hf Text-to-Speech / Speech-to-Text
Audio LLM audio-flamingo-3-hf Text-to-Speech / Speech-to-Text


Hearing about a potential new Audio LLM that might be 'house-runnable' we had Grok 4 do an investigation into the Audio LLM inference model 'audio-flamingo-3-hf'. This is the guide written for it, which we then followed to see if we really did need A100 cards (which are roughly about $8000/piece right now.)
- Updated Hugging Face Links for Audio-Flamingo-3-HF
The primary Hugging Face repository for the Audio Flamingo 3 model, including weights and configuration files, is available at: https://huggingface.co/nvidia/audio-flamingo-3-hf. A demonstration space for basic interaction with the model can be accessed at: https://huggingface.co/spaces/nvidia/audio-flamingo-3. An additional chat-oriented demonstration space, supporting multi-turn conversations, is located at: https://huggingface.co/spaces/nvidia/audio-flamingo-3-chat. Supporting code and README documentation for implementation details are hosted within these spaces, particularly at https://huggingface.co/spaces/nvidia/audio-flamingo-3/blob/main/README.md.

- Spoiler Alert! You will need Python 3.10 to Use this, The Installation 'Experience' follows the write up and code examples.
Updated Detailed Guide on Features, Options, and Capabilities of Audio Flamingo 3
Audio Flamingo 3 (AF3) represents a Transformer-based large audio-language model (LALM) designed to enhance reasoning and comprehension across diverse audio modalities, including speech, sounds, and music. It integrates an AF-Whisper unified audio encoder for joint representation learning, an MLP-based audio adaptor for modality alignment, a decoder-only LLM backbone derived from Qwen2.5-7B, and an optional streaming text-to-speech (TTS) module for voice interactions in the AF3-Chat variant. The model comprises approximately 8 billion parameters and supports non-commercial research applications under the NVIDIA OneWay Noncommercial License.
Key Features
- Unified Audio Representation Learning: Processes speech, sounds, and music through a single encoder, enabling seamless handling of mixed audio inputs without modality-specific preprocessing.
- On-Demand Chain-of-Thought Reasoning (Thinking in Audio): Allows the model to generate intermediate reasoning steps for complex queries, improving interpretability and accuracy in audio analysis tasks.
- Long-Context Audio Comprehension: Supports audio inputs up to 10 minutes in duration, facilitating analysis of extended recordings such as lectures, podcasts, or musical compositions.
- Multi-Turn and Multi-Audio Conversational Dialogue: In the AF3-Chat variant, maintains context across multiple interactions and audio files, enabling dynamic conversations.
- Voice-to-Voice Interaction: Converts input speech to text for processing and generates streaming TTS outputs, supporting end-to-end voice-based dialogues. The TTS module employs a decoder-only transformer architecture that predicts audio tokens conditioned on text tokens from the LLM and previously generated audio tokens, utilizing a neural audio codec for waveform reconstruction. This enables streaming speech generation for real-time interactions. However, based on available documentation, the TTS module does not support customizable voice options, such as generating speech in voices resembling a female (girl), male (guy), or elderly (old guy) persona. The generated speech is produced in a default, neutral voice derived from the model's training on approximately 100,000 hours of speaker-specific audio data, which includes random concatenations for consistency but lacks user-selectable attributes for gender, age, pitch, accent, or style. While the model can analyze input audio for attributes like speaker gender or emotional tone, this capability does not extend to output generation customization.
- Benchmark Performance: Establishes state-of-the-art results on over 20 public audio understanding and reasoning benchmarks, outperforming models such as Qwen2-Audio, SALMONN, and Gemini Pro v1.5.
Available Options and Configurations
- Input Formats: Accepts audio files in WAV, MP3, or FLAC formats (up to 10 minutes) and UTF-8 text prompts (up to 16,000 tokens). Audio inputs are treated as two-dimensional data, while text is one-dimensional.
- Output Formats: Generates UTF-8 text responses (up to 1,024 tokens) or optional streaming TTS waveforms for speech synthesis. TTS outputs are in a default voice without options for variation.
- Inference Modes: Standard inference for single-query tasks; PEFT (Parameter-Efficient Fine-Tuning) mode for enhanced efficiency in stage 3.5 variants; conversational mode for multi-turn interactions, including voice-to-voice with TTS.
- Customization Parameters: During inference, users can specify conversation modes (e.g., "auto"), prompt texts, media paths, and PEFT activation. Generation configurations, such as temperature or max tokens, can be adjusted via the underlying Hugging Face Transformers library. TTS integration is available in the AF3-Chat variant but lacks parameters for voice selection or modification.
- Ethical and Licensing Options: Restricted to non-commercial use; users must adhere to terms regarding data generated by integrated components like Qwen and OpenAI.
Capabilities and Applications
AF3 excels in tasks requiring integrated audio-text processing and is particularly suited for research in audio intelligence. Potential applications include:
- Audio Question Answering and Reasoning: Analyze audio content to answer queries, such as describing scenes, identifying emotions, or reasoning about events (e.g., "What elements make this music calming?").
- Long-Context Analysis: Summarize or extract insights from extended audio, such as transcribing and interpreting lengthy speeches or musical pieces.
- Interactive Assistants: Develop tools for sound or music design, where users iteratively refine creations through multi-turn dialogues (e.g., suggesting remixes based on uploaded samples).
- Voice-Based Interfaces: Enable voice-to-voice systems for accessibility, education, or entertainment, processing spoken inputs and responding audibly in a default voice. Note that while the model can process input speech and generate TTS outputs, it does not support altering the output voice to mimic specific personas such as a girl, guy, or old guy. Demonstrations illustrate factual responses in a neutral tone, but customization remains unavailable.
- Benchmarking and Research: Evaluate audio AI tasks, including captioning, classification, or generation, leveraging its superior performance on datasets like AudioSkills-XL and LongAudio-XL.
- Multi-Modal Integration: Combine with other modalities (e.g., text or vision in extended frameworks) for hybrid applications, though primarily focused on audio-language.
The model is trained on open-source datasets using a five-stage curriculum strategy, ensuring robustness across modalities without proprietary data dependencies. The TTS module's code is not currently available in the repositories, with plans for future release alongside a detailed report.
Updated Detailed Guide on Installation and Recommended Hardware Requirements
Installation Guide
Audio Flamingo 3 integrates with PyTorch and Hugging Face Transformers for inference, requiring a Linux environment optimized for NVIDIA GPUs. Follow these steps for setup:
Set Up the Environment: Install Python 3.10 or later. Create a virtual environment using venv or conda to isolate dependencies.
Install Core Dependencies: Execute the following commands:
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
pip install transformers peft gradio
These install PyTorch with CUDA support (version 2.1 or compatible), Hugging Face Transformers for model loading, PEFT for efficient fine-tuning in stage 3.5, and Gradio for optional interactive interfaces.
Clone the Supporting Code Repository: The inference scripts are derived from NVILA. Clone the adapted repository:
git clone https://huggingface.co/spaces/nvidia/audio-flamingo-3
cd audio-flamingo-3/audio_flamingo_3
Run the environment setup script:
./environment_setup.sh af3
This configures additional dependencies and paths. Note that the streaming TTS module for voice output is not included in the current release; it is planned for future availability.
Download Model Checkpoints: Use Hugging Face's snapshot_download or load directly via Transformers:
from huggingface_hub import snapshot_download
MODEL_PATH = snapshot_download(repo_id="nvidia/audio-flamingo-3-hf")
For the chat variant: repo_id="nvidia/audio-flamingo-3-chat".
Verify Installation: Test basic inference with a provided script (e.g., llava/cli/infer_audio.py) or launch the Gradio demo from app.py in the chat space:
python app.py
Ensure CUDA is detected by running torch.cuda.is_available() in Python.
Troubleshooting: If encountering module errors (e.g., llava), ensure the cloned repository's paths are added to PYTHONPATH. For TTS, the streaming pipeline code remains unreleased as of the latest documentation, limiting voice output to demonstration spaces only.
Recommended Hardware Requirements
The model is optimized for NVIDIA GPU-accelerated systems, leveraging CUDA for efficient training and inference. CPU-only operation is possible but significantly slower and not recommended for long-context tasks. Minimum requirements include:
- Operating System: Linux (tested on Ubuntu variants).
- GPU: NVIDIA Ampere architecture (e.g., A100) or Hopper (e.g., H100) with at least 80 GB VRAM for full-precision inference on 10-minute audio.
- RAM: 32 GB or more system memory to handle large tensors.
- Storage: 50 GB free space for checkpoints and dependencies.
- Additional: High-bandwidth storage (e.g., SSD) for audio file loading.
For reduced precision (e.g., BF16), lower VRAM (40 GB) may suffice, but performance may degrade on extended inputs. TTS operations, when available, may require additional GPU resources for real-time streaming, but specific requirements are not detailed due to the module's pending release.
| Model Variant | Parameter Size | Recommended Hardware | Notes |
|---|---|---|---|
| Audio-Flamingo-3 (Stage 3) | 8B | NVIDIA A100 (80 GB VRAM), Linux, PyTorch CUDA | Base model for standard inference; supports up to 10-minute audio. |
| Audio-Flamingo-3 (Stage 3.5) | 8B | NVIDIA A100/H100 (80 GB VRAM), Linux | PEFT-enabled for efficiency; suitable for fine-tuning experiments. |
| Audio-Flamingo-3-Chat | 8B | NVIDIA H100 (80 GB VRAM), Linux, TTS support | Optimized for multi-turn dialogues; TTS module pending code release, supports default voice output only. |
Updated 10 Code Examples of Using Audio Flamingo 3
The following examples demonstrate inference using Python, assuming the environment is set up as described. They are based on the model's CLI and API interfaces, utilizing the llava module from the cloned repository. Replace /path/to/checkpoint/af3-7b with your downloaded model path and ensure audio files are accessible. Note that TTS examples are hypothetical or based on planned integration, as the streaming TTS code is not yet released; they assume future availability of the module for waveform generation in a default voice. No examples include voice customization, as this feature is not supported.
Basic Audio Description (Stage 3):
# Run via CLI: python llava/cli/infer_audio.py --model-base /path/to/checkpoint/af3-7b --conv-mode auto --text "Describe the audio in detail." --media /path/to/audio.wav
# Or in script:
import llava
model = llava.load("/path/to/checkpoint/af3-7b")
sound = llava.Sound("/path/to/audio.wav")
response = model.generate_content([sound, "Describe the audio in detail."])
print(response)
Chain-of-Thought Reasoning:
import llava
model = llava.load("/path/to/checkpoint/af3-7b")
sound = llava.Sound("/path/to/music.mp3")
prompt = "Think step-by-step: What emotions does this music evoke and why?"
response = model.generate_content([sound, prompt])
print(response)
Long-Context Analysis:
import llava
model = llava.load("/path/to/checkpoint/af3-7b")
sound = llava.Sound("/path/to/10min_podcast.flac") # Up to 10 minutes
prompt = "Summarize the key points from this entire podcast."
response = model.generate_content([sound, prompt])
print(response)
PEFT Mode Inference (Stage 3.5):
# CLI: python llava/cli/infer_audio.py --model-base /path/to/checkpoint/af3-7b --model-path /path/to/checkpoint/af3-7b/stage35 --conv-mode auto --text "Identify sounds in the audio." --media /path/to/audio.wav --peft-mode
# Script:
from peft import PeftModel
import llava
base_model = llava.load("/path/to/checkpoint/af3-7b")
model = PeftModel.from_pretrained(base_model, "/path/to/checkpoint/af3-7b/stage35")
sound = llava.Sound("/path/to/audio.wav")
response = model.generate_content([sound, "Identify sounds in the audio."])
print(response)
Multi-Turn Chat Setup (AF3-Chat):
import llava
from huggingface_hub import snapshot_download
MODEL_BASE = snapshot_download("nvidia/audio-flamingo-3-chat")
model = llava.load(MODEL_BASE).to("cuda")
history = [] # Initialize chat history
Multi-Turn Interaction Example:
# Continuing from Example 5
sound = llava.Sound("/path/to/audio1.mp3")
user_input = "What is the main theme of this audio?"
prompt = f"<sound>\n {user_input}"
response = model.generate_content([sound, prompt])
history.append((user_input, response))
print(response)
# Next turn
user_input = "Suggest improvements to the composition."
response = model.generate_content([sound, user_input]) # Maintains context
history.append((user_input, response))
print(response)
Voice-to-Voice Prompt (Speech Input with TTS Output - Hypothetical):
import llava
# Assuming future TTS module integration
model = llava.load("/path/to/checkpoint/af3-chat").to("cuda")
sound = llava.Sound("/path/to/spoken_query.wav") # Spoken input
full_prompt = "<sound>" # Processes input to generate text, then TTS
response_text = model.generate_content([sound, full_prompt])
# Hypothetical TTS call (pending release): waveform = model.tts_generate(response_text) # Default voice
print(response_text) # Text output; waveform would be saved or streamed
Audio Classification Task with TTS Response - Hypothetical:
import llava
# Assuming TTS availability
model = llava.load("/path/to/checkpoint/af3-chat")
sound = llava.Sound("/path/to/sound_effect.flac")
prompt = "Classify the primary sound in this audio and explain your reasoning."
response_text = model.generate_content([sound, prompt])
# Hypothetical: waveform = model.stream_tts(response_text) # Streams in default neutral voice
print(response_text)
Music Remix Suggestion with Voice Output - Hypothetical:
import llava
model = llava.load("/path/to/checkpoint/af3-chat")
sound = llava.Sound("/path/to/music_sample.mp3")
prompt = "Suggest a remix by adding elements that enhance its energy."
response_text = model.generate_content([sound, prompt])
# Hypothetical TTS: model.generate_voice(response_text) # Outputs waveform in default voice, no gender/age options
print(response_text)
Error-Handled Batch Inference with Optional TTS:
import llava
model = llava.load("/path/to/checkpoint/af3-chat").to("cuda")
audios = ["/path/to/audio1.wav", "/path/to/audio2.mp3"]
prompts = ["Describe audio 1.", "Analyze audio 2."]
responses = []
for audio_path, prompt in zip(audios, prompts):
try:
sound = llava.Sound(audio_path)
response_text = model.generate_content([sound, prompt])
# Hypothetical: if tts_available: waveform = model.tts(response_text) # Default voice only
responses.append(response_text)
except Exception as e:
responses.append(f"Error: {str(e)}")
print(responses)
NOTES: Authors Experience with this Model: LOTS of LIBRARIES
- LOTS OF LIBRARIES.
- Python3.10 MUST be Used, as Python 3.13 broke it.
The following was experienced when running the following example code block:
from huggingface_hub import snapshot_download
MODEL_PATH = snapshot_download(repo_id="nvidia/audio-flamingo-3-hf")
import llava
model = llava.load("/path/to/checkpoint/af3-7b")
sound = llava.Sound("/path/to/audio.wav")
response = model.generate_content([sound, "Describe the audio in detail."])
print(response)- This installation did not work 'straight-out-of-the-box'
- The Git Repository was then downloaded with a new .venv setup, and and Pycharm is very good at automating this.
Next we needed to upgrade the .venv so:
cd .venv/bin
source ./activate # Start the .env python environment
pip install pip --upgradeNext numpy was broken - so we fixed that too.
sudo apt install python3-dev -yAnd then we did a manual numpy installation:
pip install numpyAt this point we were still kicking significant errors, we picked away at the dependency model requirements one by one.
pip install ../../requirements.txt
pip install peft # This solved a lotBy this time we were much closer,
Further:
python3 -m pip install uv hydra-core loguru torchvisionThis needed a LOT of stuff it continued,
python3 -m pip install soundfilesudo apt full-upgrade
sudo apt install python3.13-devWe continued running sync's, this became like swatting flies,
- This time it installed a LOT of stuff (again), but still kicking errors as in:
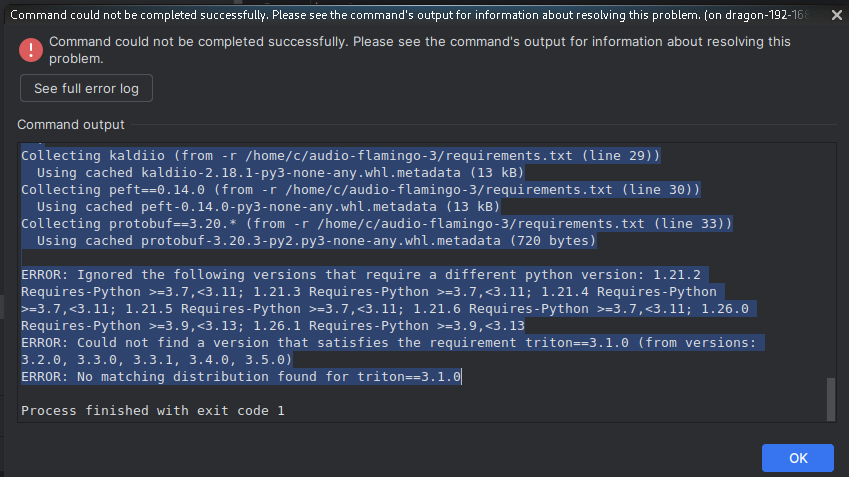
- The idea here is this stuff is IMMENSELY ACCELERATED by simply taking those fail logs, pasting them into a 'Tier 1' AI and letting it throw suggestions as there is an entire matrix of libraries it looks this one LLM needs, so we kept going:
Start Over Now! Install Python 3.10 and Related Tools (if not already present):
Next it was recommended we uninstall and reinstall python3.10 as in:
The error messages indicate compatibility issues between your Python 3.13 virtual environment and specific pinned dependencies in the requirements.txt file for the Audio Flamingo 3 project. Notably:
- NumPy version 1.26.4 explicitly requires Python >=3.9 and <3.13, as stated in its version constraints.
- Triton version 3.1.0 lacks pre-built distributions (wheels) for Python 3.13; available versions start from 3.2.0 and higher, which do not match the pinned requirement.
These constraints arise because many AI/ML libraries, including those used here (e.g., Torch, Transformers, and OpenAI Whisper, which depends on Triton), have not yet fully supported Python 3.13 due to its recent release and the need for recompilation of native extensions.
To resolve this, recreate the virtual environment using Python 3.10, which aligns with the project's recommended configuration as specified in the repository's requirements.txt (pinned to Python 3.10.14). This version ensures compatibility with all dependencies while maintaining stability for CUDA-accelerated operations.
Follow these steps precisely on your Ubuntu system:
sudo apt update
sudo apt install python3.10 python3.10-venv python3.10-dev build-essential
Navigate to the Project Directory:
cd /home/c/audio-flamingo-3
Remove the Existing Virtual Environment (to avoid conflicts):
rm -rf .venv
Create a New Virtual Environment with Python 3.10:
python3.10 -m venv .venv
Activate the New Environment:
source .venv/bin/activate
Upgrade Pip (to ensure smooth dependency resolution):
pip install --upgrade pip
Run the Environment Setup Script:
./environment_setup.sh af3
Install the Requirements:
pip install -r requirements.txt
After completing these steps, verify the installation by checking the Python version within the environment (python --version, which should output 3.10.x) and testing a basic import (e.g., python -c "import numpy; import triton; print('Success')"). If any issues persist, such as CUDA-related errors, confirm your NVIDIA drivers and CUDA toolkit are compatible with Torch 2.3.0 (as pinned in the repository). Should further errors occur, provide the complete output for additional analysis.
The process was repeated again - this time with Python 3.10, and it took another 15 mintes to now - redownload all the modules to take it back from the Python 3.13 -> 3.10
We were presented with the following error:
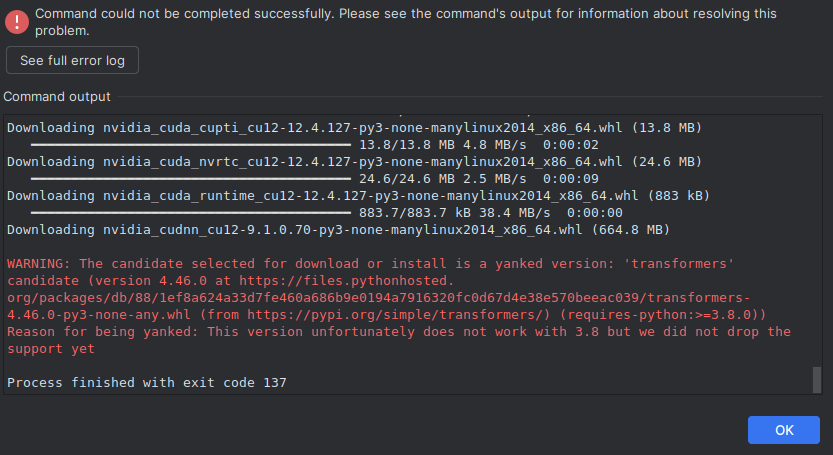
After this we tried running it, only to need more dependenices such as 'logru' and 'torchvision' on the third run we then installed 'soundfile' on the fourth run we needed 'librosa', then on the fifth try it needed 'whisper' then 'openai-whisper' Run 6 needed 'pytorchvideo
Finally we re-opened 'requirements.txt' in Pycharm which has a nice feature 'install all missing packages' as the ones highlighted were not done yet.
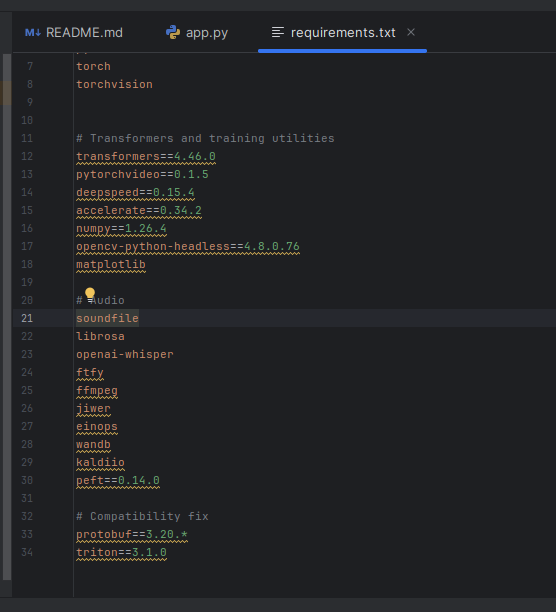
Some of the wheels are quite large - nvidia_cudnn is 664.8 MB!

It should be noted it seemd to take multiple cycles of attempting to get the packages to sync, this was a real process.
This was sent back to Grok 4 and the following inconsistencies were suggested as a fix:
The reported RuntimeError, which occurs during the import of transformers.models.bloom.modeling_bloom and references the missing torchvision::nms operator, typically results from an incompatibility between the installed versions of PyTorch (torch) and TorchVision (torchvision). This mismatch can arise from separate installations, differing CUDA dependencies, or incomplete upgrades, leading to the absence of required operators such as Non-Maximum Suppression (NMS) in TorchVision.
To address this issue within your virtual environment for the Audio Flamingo 3 setup, execute the following commands in sequence. These steps ensure the removal of conflicting packages and their reinstallation from a compatible source, aligned with the project's recommended CUDA 12.1 configuration.
- Activate the virtual environment if it is not already active: text
source /home/c/audio-flamingo-3/.venv/bin/activate- Uninstall the affected packages: text
pip uninstall torch torchvision torchaudio -y- Reinstall the packages using the specified index for consistency: text
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121Upon completion, verify the installations by checking the versions:
text
pip show torch torchvision torchaudioThe output should confirm matching versions (e.g., PyTorch 2.3.0 or a compatible release, depending on the index). Subsequently, attempt to rerun your import or inference code to confirm resolution of the error.
If the system lacks CUDA support (e.g., running on CPU), replace the reinstall command..
We worked through it:
STOP. We have stopped at this point, as clearly this type of LLM pretty much requires an A100 or higher video card to run it, so we are not sure if anyone was able to get it to work, and on what hardware, but we simply don't have the ponies to run this.
ACCESS IT FOR FREE ANYWAYS: https://huggingface.co/spaces/nvidia/audio-flamingo-3